装载自:http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html
TensorFlow训练MNIST
这个教程的目标读者是对机器学习和TensorFlow都不太了解的新手。如果你已经了解MNIST和softmax回归(softmax regression)的相关知识,你可以阅读这个快速上手教程。
当我们开始学习编程的时候,第一件事往往是学习打印"Hello World"。就好比编程入门有Hello World,机器学习入门有MNIST。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:

它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1。
在此教程中,我们将训练一个机器学习模型用于预测图片里面的数字。我们的目的不是要设计一个世界一流的复杂模型 -- 尽管我们会在之后给你源代码去实现一流的预测模型 -- 而是要介绍下如何使用TensorFlow。所以,我们这里会从一个很简单的数学模型开始,它叫做Softmax Regression。
对应这个教程的实现代码很短,而且真正有意思的内容只包含在三行代码里面。但是,去理解包含在这些代码里面的设计思想是非常重要的:TensorFlow工作流程和机器学习的基本概念。因此,这个教程会很详细地介绍这些代码的实现原理。
MNIST数据集
MNIST数据集的官网是Yann LeCun's website。在这里,我们提供了一份python源代码用于自动下载和安装这个数据集。你可以下载这份代码,然后用下面的代码导入到你的项目里面,也可以直接复制粘贴到你的代码文件里面。
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
下载下来的数据集被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不用于训练而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上(泛化)。
正如前面提到的一样,每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为“xs”,把这些标签设为“ys”。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。
每一张图片包含28像素X28像素。我们可以用一个数字数组来表示这张图片:

我们把这个数组展开成一个向量,长度是 28x28 = 784。如何展开这个数组(数字间的顺序)不重要,只要保持各个图片采用相同的方式展开。从这个角度来看,MNIST数据集的图片就是在784维向量空间里面的点, 并且拥有比较复杂的结构 (提醒: 此类数据的可视化是计算密集型的)。
展平图片的数字数组会丢失图片的二维结构信息。这显然是不理想的,最优秀的计算机视觉方法会挖掘并利用这些结构信息,我们会在后续教程中介绍。但是在这个教程中我们忽略这些结构,所介绍的简单数学模型,softmax回归(softmax regression),不会利用这些结构信息。
因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784]的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。

相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里表示的数字。为了用于这个教程,我们使标签数据是"one-hot vectors"。 一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。所以在此教程中,数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。因此, mnist.train.labels 是一个 [60000, 10] 的数字矩阵。

现在,我们准备好可以开始构建我们的模型啦!
Softmax回归介绍
我们知道MNIST的每一张图片都表示一个数字,从0到9。我们希望得到给定图片代表每个数字的概率。比如说,我们的模型可能推测一张包含9的图片代表数字9的概率是80%但是判断它是8的概率是5%(因为8和9都有上半部分的小圆),然后给予它代表其他数字的概率更小的值。
这是一个使用softmax回归(softmax regression)模型的经典案例。softmax模型可以用来给不同的对象分配概率。即使在之后,我们训练更加精细的模型时,最后一步也需要用softmax来分配概率。
softmax回归(softmax regression)分两步:第一步
为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。
下面的图片显示了一个模型学习到的图片上每个像素对于特定数字类的权值。红色代表负数权值,蓝色代表正数权值。

我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。因此对于给定的输入图片 x 它代表的是数字 i 的证据可以表示为

其中  代表权重,
代表权重, 代表数字 i 类的偏置量,j 代表给定图片 x 的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率 y:
代表数字 i 类的偏置量,j 代表给定图片 x 的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率 y:

这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。softmax函数可以定义为:

展开等式右边的子式,可以得到:

但是更多的时候把softmax模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0值或者负值。Softmax然后会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。(更多的关于Softmax函数的信息,可以参考Michael Nieslen的书里面的这个部分,其中有关于softmax的可交互式的可视化解释。)
对于softmax回归模型可以用下面的图解释,对于输入的xs加权求和,再分别加上一个偏置量,最后再输入到softmax函数中:

如果把它写成一个等式,我们可以得到:

我们也可以用向量表示这个计算过程:用矩阵乘法和向量相加。这有助于提高计算效率。(也是一种更有效的思考方式)

更进一步,可以写成更加紧凑的方式:

实现回归模型
为了用python实现高效的数值计算,我们通常会使用函数库,比如NumPy,会把类似矩阵乘法这样的复杂运算使用其他外部语言实现。不幸的是,从外部计算切换回Python的每一个操作,仍然是一个很大的开销。如果你用GPU来进行外部计算,这样的开销会更大。用分布式的计算方式,也会花费更多的资源用来传输数据。
TensorFlow也把复杂的计算放在python之外完成,但是为了避免前面说的那些开销,它做了进一步完善。Tensorflow不单独地运行单一的复杂计算,而是让我们可以先用图描述一系列可交互的计算操作,然后全部一起在Python之外运行。(这样类似的运行方式,可以在不少的机器学习库中看到。)
使用TensorFlow之前,首先导入它:
import tensorflow as tf
我们通过操作符号变量来描述这些可交互的操作单元,可以用下面的方式创建一个:
x = tf.placeholder("float", [None, 784])
x不是一个特定的值,而是一个占位符placeholder,我们在TensorFlow运行计算时输入这个值。我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。我们用2维的浮点数张量来表示这些图,这个张量的形状是[None,784 ]。(这里的None表示此张量的第一个维度可以是任何长度的。)
我们的模型也需要权重值和偏置量,当然我们可以把它们当做是另外的输入(使用占位符),但TensorFlow有一个更好的方法来表示它们:Variable 。 一个Variable代表一个可修改的张量,存在在TensorFlow的用于描述交互性操作的图中。它们可以用于计算输入值,也可以在计算中被修改。对于各种机器学习应用,一般都会有模型参数,可以用Variable表示。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
我们赋予tf.Variable不同的初值来创建不同的Variable:在这里,我们都用全为零的张量来初始化W和b。因为我们要学习W和b的值,它们的初值可以随意设置。
注意,W的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类。b的形状是[10],所以我们可以直接把它加到输出上面。
现在,我们可以实现我们的模型啦。只需要一行代码!
y = tf.nn.softmax(tf.matmul(x,W) + b)
首先,我们用tf.matmul(X,W)表示x乘以W,对应之前等式里面的 ,这里
,这里x是一个2维张量拥有多个输入。然后再加上b,把和输入到tf.nn.softmax函数里面。
至此,我们先用了几行简短的代码来设置变量,然后只用了一行代码来定义我们的模型。TensorFlow不仅仅可以使softmax回归模型计算变得特别简单,它也用这种非常灵活的方式来描述其他各种数值计算,从机器学习模型对物理学模拟仿真模型。一旦被定义好之后,我们的模型就可以在不同的设备上运行:计算机的CPU,GPU,甚至是手机!
训练模型
为了训练我们的模型,我们首先需要定义一个指标来评估这个模型是好的。其实,在机器学习,我们通常定义指标来表示一个模型是坏的,这个指标称为成本(cost)或损失(loss),然后尽量最小化这个指标。但是,这两种方式是相同的。
一个非常常见的,非常漂亮的成本函数是“交叉熵”(cross-entropy)。交叉熵产生于信息论里面的信息压缩编码技术,但是它后来演变成为从博弈论到机器学习等其他领域里的重要技术手段。它的定义如下:

y 是我们预测的概率分布, y' 是实际的分布(我们输入的one-hot vector)。比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。更详细的关于交叉熵的解释超出本教程的范畴,但是你很有必要好好理解它。
为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", [None,10])
然后我们可以用  计算交叉熵:
计算交叉熵:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
首先,用 tf.log 计算 y 的每个元素的对数。接下来,我们把 y_ 的每一个元素和 tf.log(y_) 的对应元素相乘。最后,用 tf.reduce_sum 计算张量的所有元素的总和。(注意,这里的交叉熵不仅仅用来衡量单一的一对预测和真实值,而是所有100幅图片的交叉熵的总和。对于100个数据点的预测表现比单一数据点的表现能更好地描述我们的模型的性能。
现在我们知道我们需要我们的模型做什么啦,用TensorFlow来训练它是非常容易的。因为TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法(backpropagation algorithm)来有效地确定你的变量是如何影响你想要最小化的那个成本值的。然后,TensorFlow会用你选择的优化算法来不断地修改变量以降低成本。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动。当然TensorFlow也提供了其他许多优化算法:只要简单地调整一行代码就可以使用其他的算法。
TensorFlow在这里实际上所做的是,它会在后台给描述你的计算的那张图里面增加一系列新的计算操作单元用于实现反向传播算法和梯度下降算法。然后,它返回给你的只是一个单一的操作,当运行这个操作时,它用梯度下降算法训练你的模型,微调你的变量,不断减少成本。
现在,我们已经设置好了我们的模型。在运行计算之前,我们需要添加一个操作来初始化我们创建的变量:
init = tf.initialize_all_variables()
现在我们可以在一个Session里面启动我们的模型,并且初始化变量:
sess = tf.Session()
sess.run(init)
然后开始训练模型,这里我们让模型循环训练1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
该循环的每个步骤中,我们都会随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换之前的占位符来运行train_step。
使用一小部分的随机数据来进行训练被称为随机训练(stochastic training)- 在这里更确切的说是随机梯度下降训练。在理想情况下,我们希望用我们所有的数据来进行每一步的训练,因为这能给我们更好的训练结果,但显然这需要很大的计算开销。所以,每一次训练我们可以使用不同的数据子集,这样做既可以减少计算开销,又可以最大化地学习到数据集的总体特性。
评估我们的模型
那么我们的模型性能如何呢?
首先让我们找出那些预测正确的标签。tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
最后,我们计算所学习到的模型在测试数据集上面的正确率。
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
这个最终结果值应该大约是91%。
在这里说明一下,我照着它给的代码敲了一下发现一个问题,那就是使用它给的那个 下载并解压数据集的那个脚本文件出现了问题,所以这里给出自己写的代码,这样能够顺利下载数据集:
1 # # -*- coding: UTF-8 -*- 2 # # date:2018/6/14 3 # # User:WangHong 4 from tensorflow.examples.tutorials.mnist import input_data 5 import tensorflow as tf 6 7 # 注册一个默认的Session,之后的运算都跑在这个session里面 8 sess = tf.InteractiveSession() 9 # 读取数据,one_hot是10类表示的师0-9的10个数字 10 mnist = input_data.read_data_sets("MNIST_data", one_hot = True) 11 # 创建一个Placeholder,输入数据的地方,参数(数据类型,tensor的shape),其中None表示不限制条数输入,n表示n维向量 12 x = tf.placeholder(tf.float32, [None, 784]) 13 # 初始化weight和biases全部初始化为0,模型训练会选择合适的值 14 w = tf.Variable(tf.zeros([784, 10])) 15 # 其中w的shape是[784,10],784为特征数,10代表有10类,因为one_hot编码后是10维向量 16 b = tf.Variable(tf.zeros([10])) 17 # tf.nn包含大量的神经网络的组件,tf.matmul是矩阵乘法 18 y = tf.nn.softmax(tf.matmul(x, w) + b) 19 # 定义一个模型分类的损失函数,损失越小,模型越准确 20 y_ = tf.placeholder(tf.float32, [None, 10]) 21 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1])) # 一个信息熵的计算 22 # 优化算法,随机梯度下降SGD,通过反向传播进行训练更新参数减少loss,学习速率0.5,优化目标就是定义的loss 23 train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) 24 # 使用全局参数初始化器tf.global_variables_initializer,运行其run方法 25 tf.global_variables_initializer().run() 26 27 for i in range(1000): 28 # 每次随机从训练集中抽取100条样本构成一个mini_batch,并feed给placeholder 29 batch_xs, batch_ys = mnist.train.next_batch(100) 30 # 小样本避免全局样本的局部最优,以及速度问题,小样本收敛速度越快 31 train_step.run({x: batch_xs, y_: batch_ys}) 32 33 # 对于模型的准确性验证,tf,argmax寻找最大值的序号,tf.equal用于判断是否分类到正确类别 34 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) 35 # 统计全部样本的精度,tf.cast将之前的correct_prediction输出的bool值转化为float32,再去求平均值 36 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) 37 print(accuracy.eval({x:mnist.test.images, y_:mnist.test.labels}))
最终得到结果:

得到的结果的识别率只有91.52%不是很理想
二、使用多成卷积网络训练MNIST
构建一个多层卷积网络
在MNIST上只有91%正确率,实在太糟糕。在这个小节里,我们用一个稍微复杂的模型:卷积神经网络来改善效果。这会达到大概99.2%的准确率。虽然不是最高,但是还是比较让人满意。
权重初始化
为了创建这个模型,我们需要创建大量的权重和偏置项。这个模型中的权重在初始化时应该加入少量的噪声来打破对称性以及避免0梯度。由于我们使用的是ReLU神经元,因此比较好的做法是用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为0的问题(dead neurons)。为了不在建立模型的时候反复做初始化操作,我们定义两个函数用于初始化。
1 def weight_variable(shape): 2 initial = tf.truncated_normal(shape, stddev=0.1) 3 return tf.Variable(initial) 4 5 def bias_variable(shape): 6 initial = tf.constant(0.1, shape=shape) 7 return tf.Variable(initial)
卷积和池化
TensorFlow在卷积和池化上有很强的灵活性。我们怎么处理边界?步长应该设多大?在这个实例里,我们会一直使用vanilla版本。我们的卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小。我们的池化用简单传统的2x2大小的模板做max pooling。为了代码更简洁,我们把这部分抽象成一个函数。
def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
第一层卷积
现在我们可以开始实现第一层了。它由一个卷积接一个max pooling完成。卷积在每个5x5的patch中算出32个特征。卷积的权重张量形状是[5, 5, 1, 32],前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。 而对于每一个输出通道都有一个对应的偏置量。
W_conv1 = weight_variable([5, 5, 1, 32]) b_conv1 = bias_variable([32])
为了用这一层,我们把x变成一个4d向量,其第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是rgb彩色图,则为3)。
x_image = tf.reshape(x, [-1,28,28,1])
We then convolve x_image with the weight tensor, add the bias, apply the ReLU function, and finally max pool. 我们把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行max pooling。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) h_pool1 = max_pool_2x2(h_conv1)
第二层卷积
为了构建一个更深的网络,我们会把几个类似的层堆叠起来。第二层中,每个5x5的patch会得到64个特征。
W_conv2 = weight_variable([5, 5, 32, 64]) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) h_pool2 = max_pool_2x2(h_conv2)
密集连接层
现在,图片尺寸减小到7x7,我们加入一个有1024个神经元的全连接层,用于处理整个图片。我们把池化层输出的张量reshape成一些向量,乘上权重矩阵,加上偏置,然后对其使用ReLU。
W_fc1 = weight_variable([7 * 7 * 64, 1024]) b_fc1 = bias_variable([1024]) h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
Dropout
为了减少过拟合,我们在输出层之前加入dropout。我们用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。这样我们可以在训练过程中启用dropout,在测试过程中关闭dropout。 TensorFlow的tf.nn.dropout操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的scale。所以用dropout的时候可以不用考虑scale。
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
输出层
最后,我们添加一个softmax层,就像前面的单层softmax regression一样。
W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
训练和评估模型
这个模型的效果如何呢?
为了进行训练和评估,我们使用与之前简单的单层SoftMax神经网络模型几乎相同的一套代码,只是我们会用更加复杂的ADAM优化器来做梯度最速下降,在feed_dict中加入额外的参数keep_prob来控制dropout比例。然后每100次迭代输出一次日志。
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print "test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
全部代码:


1 # # -*- coding: UTF-8 -*- 2 # # date:2018/6/14 3 # # User:WangHong 4 from tensorflow.examples.tutorials.mnist import input_data 5 import tensorflow as tf 6 7 # 注册一个默认的Session,之后的运算都跑在这个session里面 8 sess = tf.InteractiveSession() 9 # # 读取数据,one_hot是10类表示的师0-9的10个数字 10 mnist = input_data.read_data_sets("MNIST_data", one_hot = True) 11 # # 创建一个Placeholder,输入数据的地方,参数(数据类型,tensor的shape),其中None表示不限制条数输入,n表示n维向量 12 x = tf.placeholder(tf.float32, [None, 784]) 13 y_ = tf.placeholder("float", shape=[None, 10]) 14 15 def weight_variable(shape): 16 initial = tf.truncated_normal(shape, stddev=0.1) 17 return tf.Variable(initial) 18 19 def bias_variable(shape): 20 initial = tf.constant(0.1, shape=shape) 21 return tf.Variable(initial) 22 23 def conv2d(x, W): 24 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') 25 26 def max_pool_2x2(x): 27 return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], 28 strides=[1, 2, 2, 1], padding='SAME') 29 30 31 W_conv1 = weight_variable([5, 5, 1, 32]) 32 b_conv1 = bias_variable([32]) 33 34 x_image = tf.reshape(x, [-1,28,28,1]) 35 36 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) 37 h_pool1 = max_pool_2x2(h_conv1) 38 39 40 W_conv2 = weight_variable([5, 5, 32, 64]) 41 b_conv2 = bias_variable([64]) 42 43 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) 44 h_pool2 = max_pool_2x2(h_conv2) 45 46 W_fc1 = weight_variable([7 * 7 * 64, 1024]) 47 b_fc1 = bias_variable([1024]) 48 49 h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) 50 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) 51 52 keep_prob = tf.placeholder("float") 53 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) 54 55 W_fc2 = weight_variable([1024, 10]) 56 b_fc2 = bias_variable([10]) 57 58 y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) 59 60 cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv)) 61 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) 62 correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1)) 63 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) 64 sess.run(tf.initialize_all_variables()) 65 for i in range(20000): 66 batch = mnist.train.next_batch(50) 67 if i%100 == 0: 68 train_accuracy = accuracy.eval(feed_dict={ 69 x:batch[0], y_: batch[1], keep_prob: 1.0}) 70 print ("step %d, training accuracy %g"%(i, train_accuracy)) 71 train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) 72 73 print ("test accuracy %g"%accuracy.eval(feed_dict={ 74 x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
结果:
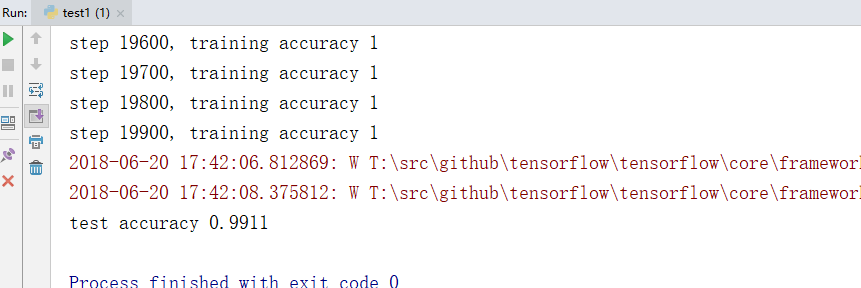
以上代码,在最终测试集上的准确率大概是99.11%。
使用AlexNet模型训练MNIST:
1 # -*- coding: UTF-8 -*- 2 # date:2018/6/22 3 # User:WangHong 4 import tensorflow as tf 5 #加载数据 6 from tensorflow.examples.tutorials.mnist import input_data 7 mnist = input_data.read_data_sets('MNIST_data',one_hot=True) 8 #定义网络超参数 9 learning_rate = 0.001 10 training_iters = 200000 11 batch_size = 128 12 display_step = 10 13 14 #定义网络参数 15 n_input = 784 16 n_classes = 10 #标记的维度,分类的种类 17 dropout = 0.75#Dropout的概率 18 #占位符 19 x = tf.placeholder(tf.float32,[None,n_input]) 20 y = tf.placeholder(tf.float32,[None,n_classes]) 21 keep_prob = tf.placeholder(tf.float32) 22 23 #定义卷积操作 24 def conv2d(name,x,W,b,strides = 1): 25 x = tf.nn.conv2d(x,W,strides=[1,strides,strides,1],padding='SAME') 26 x = tf.nn.bias_add(x,b) 27 return tf.nn.relu(x,name=name) 28 #定义池化层 29 def maxpool2d(name,x,k=2): 30 return tf.nn.max_pool(x,ksize=[1,k,k,1],strides=[1,k,k,1],padding='SAME',name=name) 31 #规范化操作 32 def norm(name,l_input,lsize = 4): 33 return tf.nn.lrn(l_input,lsize,bias=1.0,alpha=0.001/9.0,beta=0.75,name=name) 34 35 #定义所有参数 36 weights = { 37 'wc1': tf.Variable(tf.random_normal([11, 11, 1, 96])), 38 'wc2': tf.Variable(tf.random_normal([5, 5, 96, 256])), 39 'wc3': tf.Variable(tf.random_normal([3, 3, 256, 384])), 40 'wc4': tf.Variable(tf.random_normal([3, 3, 384, 384])), 41 'wc5': tf.Variable(tf.random_normal([3, 3, 384, 256])), 42 'wd1': tf.Variable(tf.random_normal([4*4*256, 4096])), 43 'wd2': tf.Variable(tf.random_normal([4096, 4096])), 44 'out': tf.Variable(tf.random_normal([4096, 10])) 45 } 46 47 biases = { 48 'bc1': tf.Variable(tf.random_normal([96])), 49 'bc2': tf.Variable(tf.random_normal([256])), 50 'bc3': tf.Variable(tf.random_normal([384])), 51 'bc4': tf.Variable(tf.random_normal([384])), 52 'bc5': tf.Variable(tf.random_normal([256])), 53 'bd1': tf.Variable(tf.random_normal([4096])), 54 'bd2': tf.Variable(tf.random_normal([1024])),# 55 'out': tf.Variable(tf.random_normal([n_classes])) 56 } 57 58 #定义AlexNet的网络模型: 59 def alex_net(x,weights,biases,dropot): 60 x = tf.reshape(x,shape=[-1,28,28,1]) 61 #第一层卷积 62 conv1 = conv2d('conv1',x,weights['wc1'],biases['bc1']) 63 pool1 = maxpool2d('pool1',conv1,k=2) 64 norm1 = norm('norm1',pool1,lsize=4) 65 #第二层卷积 66 conv2 = conv2d('conv2', norm1, weights['wc2'], biases['bc2']) 67 pool2 = maxpool2d('pool2', conv2, k=2) 68 norm2 = norm('norm2', pool2, lsize=4) 69 #第三层卷积 70 conv3 = conv2d('conv3', norm2, weights['wc3'], biases['bc3']) 71 #pool3 = maxpool2d('pool3', conv3, k=2) 72 norm3 = norm('norm3', conv3, lsize=4) 73 # 第四层卷积 74 conv4 = conv2d('conv4', norm3, weights['wc4'], biases['bc4']) 75 # 第五层卷积 76 conv5 = conv2d('conv5', conv4, weights['wc5'], biases['bc5']) 77 pool5 = maxpool2d('pool5', conv5, k=2) 78 norm5 = norm('norm5', pool5, lsize=4) 79 #全连接层1 80 fc1 = tf.reshape(norm5, [-1, weights['wd1'].get_shape().as_list()[0]]) 81 fc1 = tf.add(tf.matmul(fc1, weights['wd1']), biases['bd1']) 82 fc1 = tf.nn.relu(fc1) 83 # dropout 84 fc1 = tf.nn.dropout(fc1, dropout) 85 # 全连接层2 86 fc2 = tf.reshape(fc1, [-1, weights['wd1'].get_shape().as_list()[0]]) 87 fc2 = tf.add(tf.matmul(fc2, weights['wd1']), biases['bd1']) 88 fc2 = tf.nn.relu(fc2) 89 # dropout 90 fc2 = tf.nn.dropout(fc2, dropout) 91 #输出层 92 out = tf.add(tf.matmul(fc2, weights['out']), biases['out']) 93 return out 94 95 #构建模型 96 pred = alex_net(x, weights, biases, keep_prob) 97 # 定义损失函数和优化器 98 cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) 99 optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) 100 # 评估函数 101 correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) 102 accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) 103 #训练模型和评估模型 104 init = tf.global_variables_initializer() 105 106 with tf.Session() as sess: 107 sess.run(init) 108 step = 1 109 # 开始训练,直到达到 training_iters,即 200000 110 while step * batch_size < training_iters: 111 batch_x, batch_y = mnist.train.next_batch(batch_size) 112 sess.run(optimizer, feed_dict={x: batch_x, y: batch_y,keep_prob: dropout}) 113 if step % display_step == 0: 114 # 计算损失值和准确度,输出 115 loss, acc = sess.run([cost, accuracy], feed_dict={x: batch_x,y: batch_y,keep_prob: 1.}) 116 print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + 117 "{:.6f}".format(loss) + ", Training Accuracy= " + 118 "{:.5f}".format(acc)) 119 step += 1 120 print("Optimization Finished!") 121 print("Testing Accuracy:", 122 sess.run(accuracy, feed_dict={x: mnist.test.images[:256], 123 y: mnist.test.labels[:256], 124 keep_prob: 1.}))
使用AlexNet模型训练的结果为:
