
我们经常需要对分析的数据提取常用词,做词云展示。比如一些互联网公司会抓取用户的画像,或者每日讨论话题的关键词,形成词云并进行展示。再或者,假如你喜欢某个歌手,想了解这个歌手创作的歌曲中经常用到哪些词语,词云就是个很好的工具。最后,只需要将词云生成一张图片就可以直观地看到结果。
目标:
-
掌握词云分析工具,并进行可视化呈现;
-
掌握 Python 爬虫,对网页的数据进行爬取;
-
掌握 XPath 工具,分析提取想要的元素 。
如何制作词云
首先我们需要了解什么是词云。词云也叫文字云,它帮助我们统计文本中高频出现的词,过滤掉某些常用词(比如“作曲”“作词”),将文本中的重要关键词进行可视化,方便分析者更好更快地了解文本的重点,同时还具有一定的美观度。
Python 提供了词云工具 WordCloud,使用 pip install wordcloud 安装后,就可以创建一个词云,构造方法如下:
wc = WordCloud( background_color='white',# 设置背景颜色 mask=backgroud_Image,# 设置背景图片 font_path='./SimHei.ttf', # 设置字体,针对中文的情况需要设置中文字体,否则显示乱码 max_words=100, # 设置最大的字数 stopwords=STOPWORDS,# 设置停用词 max_font_size=150,# 设置字体最大值 width=2000,# 设置画布的宽度 height=1200,# 设置画布的高度 random_state=30# 设置多少种随机状态,即多少种颜色 )
创建好 WordCloud 类之后,就可以使用 wordcloud=generate(text) 方法生成词云,传入的参数 text 代表你要分析的文本,最后使用 wordcloud.tofile(“a.jpg”) 函数,将得到的词云图像直接保存为图片格式文件。
你也可以使用 Python 的可视化工具 Matplotlib 进行显示,方法如下:
import matplotlib.pyplot as plt plt.imshow(wordcloud) plt.axis("off") plt.show()
需要注意的是,我们不需要显示 X 轴和 Y 轴的坐标,使用 plt.axis(“off”) 可以将坐标轴关闭。
了解了如何使用词云工具 WordCloud 之后,我们将专栏前 15 节的标题进行词云可视化,具体的代码如下:
from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba from PIL import Image import numpy as np # 生成词云 def create_word_cloud(f): print('根据词频计算词云') text = " ".join(jieba.cut(f,cut_all=False, HMM=True)) wc = WordCloud( font_path="./SimHei.ttf", max_words=100, width=2000, height=1200, ) wordcloud = wc.generate(text) # 写词云图片 wordcloud.to_file("wordcloud.jpg") # 显示词云文件 plt.imshow(wordcloud) plt.axis("off") plt.show()
给陈奕迅做歌词词云展示
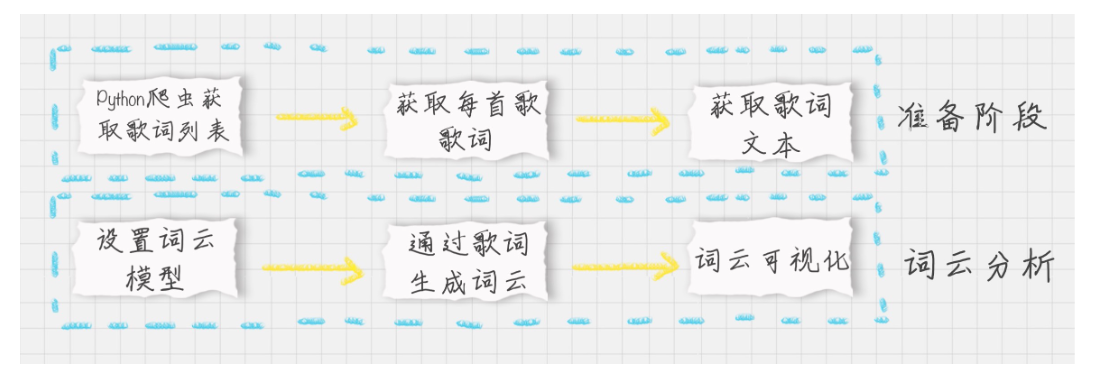
在准备阶段:我们主要使用 Python 爬虫获取 HTML,用 XPath 对歌曲的 ID、名称进行解析,然后通过网易云音乐的 API 接口获取每首歌的歌词,最后将所有的歌词合并得到一个变量。
在词云分析阶段,我们需要创建 WordCloud 词云类,分析得到的歌词文本,最后可视化。
基于上面的流程,编写代码如下:
import requests import sys import re import os from wordcloud import WordCloud import matplotlib.pyplot as plt import jieba from PIL import Image import numpy as np from lxml import etree headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/86.0.4240.198 Safari/537.36 " } # 得到指定歌手页面 热门前 50 的歌曲 ID,歌曲名 def get_songs(artist_id_): # 歌手主页URL page_url = 'https://music.163.com/artist?id={}'.format(artist_id_) # 发送请求获取响应 res = requests.get(page_url, headers) # 用 XPath 解析 前 50 首热门歌曲 html = etree.HTML(res.text) hrefs = html.xpath("//*[@id='hotsong-list']//a/@href") names = html.xpath("//*[@id='hotsong-list']//a/text()") # 获取热门歌曲的 ID,歌曲名称 songs_id = [] songs_name = [] for href, name in zip(hrefs, names): songs_id.append(href[9:]) songs_name.append(name) return songs_id, songs_name # 得到某一首歌的歌词 def get_song_lyric(lyric_url_): res = requests.request("GET", url=lyric_url_, headers=headers) if 'lrc' in res.json(): lyric_ = res.json()['lrc']['lyric'] # 去除歌词时间 lyric_ = re.sub(r'([.+])', '', lyric_)
# 去除歌词之外的无关内容 new_lyric = re.sub(r".*[::&/by|Recorded|recorded|Mixed|Mixing].*", "", lyric_) return new_lyric # 去掉停用词 # def remove_stop_words(f): # stop_words = [line.strip() for line in open('baidu_stopwords.txt', encoding='UTF-8').readlines()] # stop_words = [""] # for stop_word in stop_words: # f = f.replace(stop_word, '') # return f # 生成词云 def create_word_cloud(f): print('根据词频,开始生成词云!') # f = remove_stop_words(f) cut_text = " ".join(jieba.cut(f, cut_all=False, HMM=True)) wc = WordCloud( font_path=r"C:WindowsFontsSimHei.ttf", max_words=100, width=2000, height=1200, ) print(cut_text) wordcloud = wc.generate(cut_text) # 写词云图片 wordcloud.to_file("wordcloud.jpg") # 显示词云文件 plt.imshow(wordcloud) plt.axis("off") plt.show() if __name__ == '__main__': # 设置歌手 ID,陈奕迅为 2116 artist_id = '2116' song_ids, song_names = get_songs(artist_id) all_word = '' for song_id, song_name in zip(song_ids, song_names): # 构造歌词URL lyric_url = 'http://music.163.com/api/song/lyric?os=pc&id={}&lv=-1&kv=-1&tv=-1'.format(song_id) lyric = get_song_lyric(lyric_url).strip() all_word += lyric print(song_name) print(all_word) create_word_cloud(all_word)
步骤:
- 根据歌手的id去请求主页,获取响应
- 提取歌曲id和歌曲名称
- 构造歌词url列表
- 遍历歌词url列表,通过正则表达式提取歌词内容
- 利用全部歌词制作词云
运行结果:
