Spring中提供了基于注解来配置bean的容器,即AnnotationConfigApplicationContext
1. 开始
先看看在Spring家族中,AnnotationConfigApplicationContext在一个什么样的地位,看看继承图
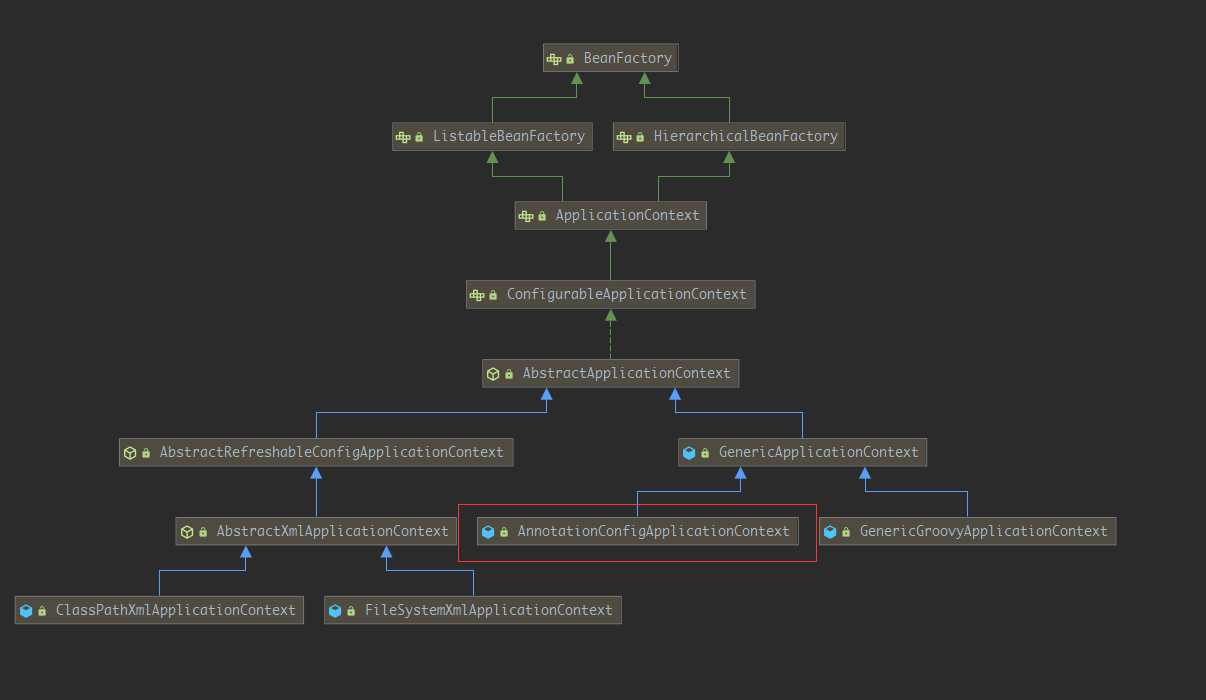
可以看到Spring提供了基于Xml配置的容器之外,还提供了基于注解和Groovy的容器,今天我们来看看基于注解配置的容器
2. 方法窥探
看看AnnotationConfigApplicationContext中提供了哪些方法
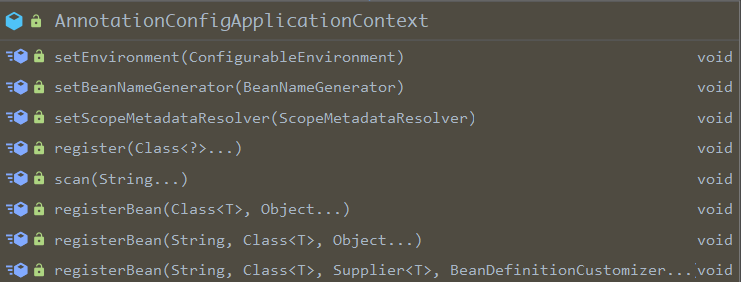
3. 从构造方法开始
我们从构造方法开始,分析基于注解的容器,是如何获取BeanDefinition并注册beanDefinitionMap中的
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
接下来一步一步分析下去
this()
调用了本类中的一个无参构造函数
public AnnotationConfigApplicationContext() {
//注解bean读取器
this.reader = new AnnotatedBeanDefinitionReader(this);
//注解bean扫描器
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
而AnnotationConfigApplicationContext继承自GenericApplicationContext,所以GenericApplicationContext的无参构造方法也会被调用
/**
* Create a new GenericApplicationContext.
* @see #registerBeanDefinition
* @see #refresh
*/
public GenericApplicationContext() {
this.beanFactory = new DefaultListableBeanFactory();
}
可以看到父类拆功能键
scan(basePackages)
public void scan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
this.scanner.scan(basePackages);
}
调用了scanner.scan(),scanner是ClassPathBeanDefinitionScanner的一个实例
/**
* Perform a scan within the specified base packages.
* @param basePackages the packages to check for annotated classes
* @return number of beans registered
*/
public int scan(String... basePackages) {
// 原来的beanDefinition数量
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
doScan(basePackages);
// 下面是注册配置处理器
// 这个是啥呢,就是以前在xml中配置的<context:annotation-config>
// 这里会注册四个注解处理器,分别是
// AutowiredAnnotationBeanPostProcessor,
// CommonAnnotationBeanPostProcessor
// PersistenceAnnotationBeanPostProcessor
// RequiredAnnotationBeanPostProcessor
// 这四个都是BeanPostProccessor,在每个Bean创建的时候都会调用它们
// 既然是注解处理器,他们处理什么注解呢?
// AutowiredAnnotationBeanPostProcessor 处理@AutoWired注解
// CommonAnnotationBeanPostProcessor 处理@ Resource 、@ PostConstruct、@ PreDestroy
// PersistenceAnnotationBeanPostProcessor 处理@PersistenceContext
// RequiredAnnotationBeanPostProcessor 处理@Required
// Register annotation config processors, if necessary.
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
// 返回本次扫描注册的beanDefinition数量
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
这个ClassPathBeanDefinitionScanner是干什么的呢,通过查看源码注释
/ * A bean definition scanner that detects bean candidates on the classpath,
* registering corresponding bean definitions with a given registry ({@code BeanFactory}
* or {@code ApplicationContext}).
*
* <p>Candidate classes are detected through configurable type filters. The
* default filters include classes that are annotated with Spring's
* {@link org.springframework.stereotype.Component @Component},
* {@link org.springframework.stereotype.Repository @Repository},
* {@link org.springframework.stereotype.Service @Service}, or
* {@link org.springframework.stereotype.Controller @Controller} stereotype.
*/
意思就是扫描类路径下的被@Component,@Repository,@Service,@Controller注解的的类,然后注册BeanDefinition到给定的BeanFactory
重点戏就在doScan()方法中
/**
* Perform a scan within the specified base packages,
* returning the registered bean definitions.
* 扫描指定的包,反正注册后的Bean Definition
* <p>This method does <i>not</i> register an annotation config processor
* but rather leaves this up to the caller.
* 这个方法不会注册注解处理器,而是留给调用者去做这件事
* @param basePackages the packages to check for annotated classes
* @return set of beans registered if any for tooling registration purposes (never {@code null})
*/
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 遍历给定的packages
for (String basePackage : basePackages) {
// findCandidateComponents是获取一个包下的满足条件的类,下面会介绍
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
findCandidateComponents(String basePackage)
这个方法可以获取一个包下的满足条件的BeanDefinition
/**
* Scan the class path for candidate components.
* @param basePackage the package to check for annotated classes
* @return a corresponding Set of autodetected bean definitions
*/
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
// 是否使用Filter,不扫描指定的包
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 扫描包
return scanCandidateComponents(basePackage);
}
}
这个scanCandidateComponents()里面就是获取资源判断是否满足条件,但是Spring判断的条件比较复杂,就先不看了
再回到doScan()方法里面:
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
// 遍历给定的packages
for (String basePackage : basePackages) {
// findCandidateComponents是获取一个包下的满足条件的类,下面会介绍
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
// 绑定scope(解析@Scope)
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// 设置beanName
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
////检查beanName否存在
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 正式将BeanDefinition注入
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
registerBeanDefinition(definitionHolder,registry)
/**
* Register the specified bean with the given registry.
* <p>Can be overridden in subclasses, e.g. to adapt the registration
* process or to register further bean definitions for each scanned bean.
* @param definitionHolder the bean definition plus bean name for the bean
* @param registry the BeanDefinitionRegistry to register the bean with
*/
protected void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) {
BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, registry);
}
/**
* Register the given bean definition with the given bean factory.
* @param definitionHolder the bean definition including name and aliases
* @param registry the bean factory to register with
* @throws BeanDefinitionStoreException if registration failed
*/
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// Register bean definition under primary name.
// 以主要名称
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// Register aliases for bean name, if any.
// 如果有别名,遍历别名注册到容器的aliasMap
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
上面的registry.registerBeanDefinition()就是DefaultListableBeanFactory中的方法了
现在scan()方法已经走完了,回到构造方法中,还剩最后一个refresh()
refresh()
这里的refresh和Xml的容器中调用的refresh是同一个方法,都来自AbstractApplicationContext
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// 记录启动时间,标记状态,检查变量
prepareRefresh();
// 初始化BeanFactory容器
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// 添加BeanPostProcessor,手动注册几个特殊的 bean
prepareBeanFactory(beanFactory);
try {
// 子类扩展点
postProcessBeanFactory(beanFactory);
// 调用 BeanFactoryPostProcessor 各个实现类的 postProcessBeanFactory(factory) 方法
invokeBeanFactoryPostProcessors(beanFactory);
// 注册 BeanPostProcessor 的实现类
registerBeanPostProcessors(beanFactory);
// 初始化MessageSource
initMessageSource();
// 初始化事件广播器
initApplicationEventMulticaster();
// 子类扩展点
onRefresh();
// 注册事件监听器
registerListeners();
// 初始化所有的 singleton beans
finishBeanFactoryInitialization(beanFactory);
// 完成refresh(),发布广播事件
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// 销毁已经初始化的的Bean
destroyBeans();
// 设置 active为false
cancelRefresh(ex);
throw ex;
}
finally {
// 清除缓存
resetCommonCaches();
}
}
}
这里也有一点不同就是第二步obtainFreshBeanFactory(),这个方法里面的调用getBeanFactory是留给子类实现的,基于注解的AnnotationConfigApplicationContext和ClassPathXmlApplicationContext是不一样的。
具体就是调用refresh方法多次,AnnotationConfigApplicationContext类的BeanFactory始终都是同一个,不会重新创建,但是ClassPathXmlApplicationContext会重新创建