以笔主手头上的Canon LIDE 100为例
先安装好扫描仪驱动程序,可使用自带驱动光盘或驱动精灵等程序完成。
打开Photoshop程序,以CS5为例,找到扫描仪入口:
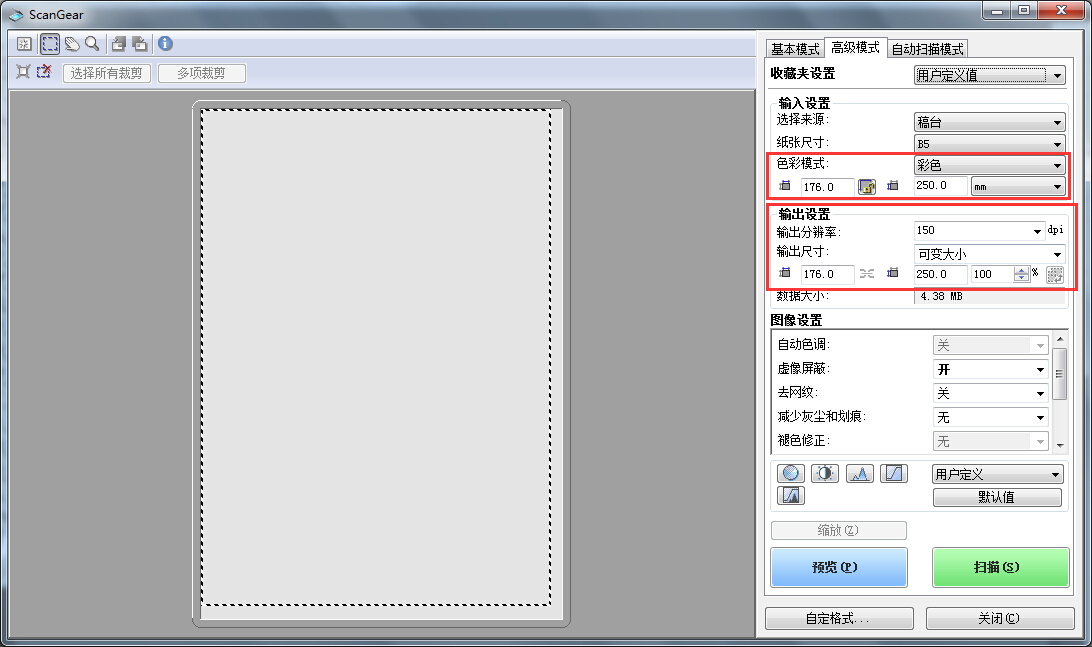
点开高级模式进行配置,笔主准备扫描的是普通B5版面的笔记本资料,笔记本封面上一般都有标记纸张尺寸,输入到相应设置项中,可减少扫描时间,并自动进行裁剪
关于dpi:
鉴于笔主当前使用的显示器为18.5英寸,1366*768分辨率,计算得出目前应用的像素密度为85ppi(普通显示器像素密度为100ppi左右),因此这里输出分辨率一般设置为150dpi足够普通资料文档查阅使用(大约为放大2倍的效果)
当然也可根据实际需要设置得更高,dpi设置越高,实际效果是扫描出来的图像文件尺寸越大,占用空间也越高
笔主手头上的扫描仪光学分辨率为2400x4800dpi,因此理论上无损最大可用dpi为2400
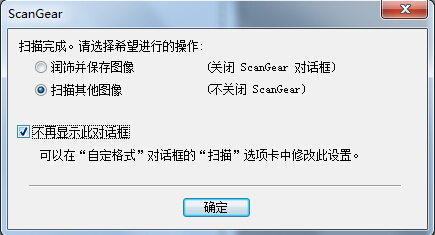
放入待扫描文件(以左下角为基准对齐),点击扫描,扫描完成后可点选弹出提示框中的 扫描其他图像 并勾选不再显示,继续扫描其他文件资料,已扫描完成的图像将自动进入到Photoshop的工作区(未保存状态)
所有文件扫描完毕后,关闭ScanGear窗口,打开动作面板(Alt+F9),新建一动作,命名为【保存】,录制其中一张扫描文件的保存并关闭过程
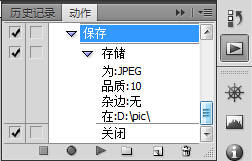
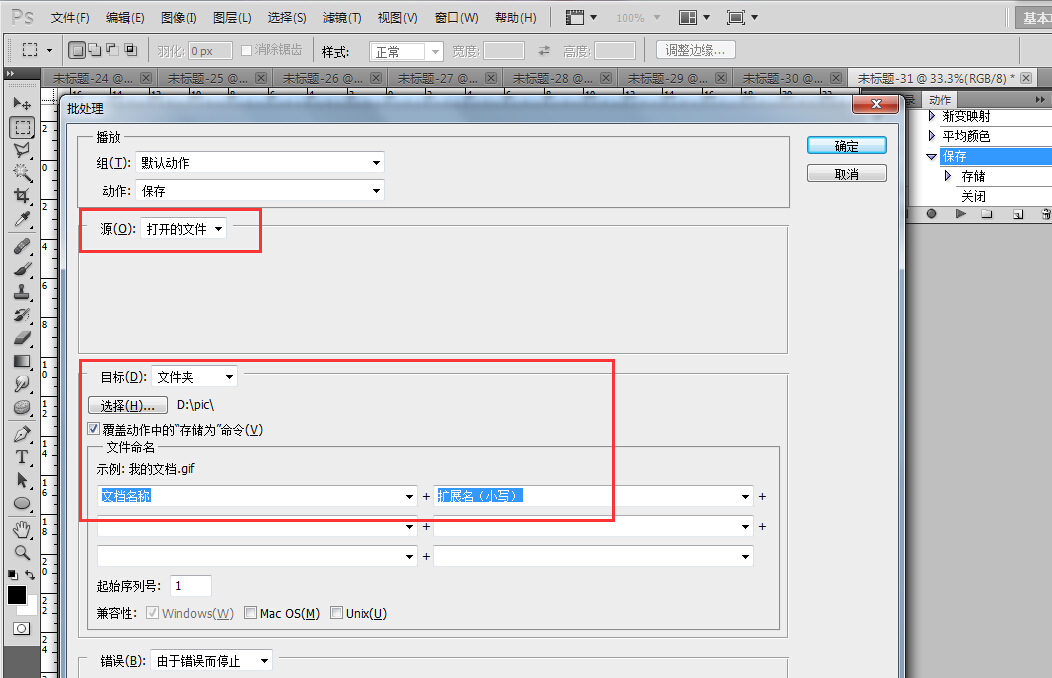
打开 文件 - 自动 - 批处理,选择刚才录制好的【保存】动作,其他选项按下图选取,点击确定,则当前工作区中所有已扫描图像将统一批量自动保存到指定文件夹中(如D:pic),其后可利用其他批量命名工具重命名所有扫描图像序列文件
顾及到系统可用内存空间问题(工作区每张扫描图占用15M内存),建议每扫描完一定数量的文件(约30张),执行一次自动保存批处理操作,清空工作区暂留资料