scrapy 基础
1、 创建一个spider项目
a) Scrapy startproject project_name [project_dir]
b) Cd project 进入项目
2、 命令:
a) Global commands:
i. startproject 创建项目
ii. genspider 创建一个爬虫
iii. settings
iv. runspider
v. shell
vi. fetch
vii. view
viii. version
b) Project-only commands:
i. crawl
ii. check
iii. list
iv. edit
v. parse
vi. bench
3、 创造一个爬虫
$ scrapy genspider -l
Available templates:
Basic 默认
crawl
csvfeed
xmlfeed
a) Scrapy genspider mydomain mydomain.com ---》basic
b) Scrapy genspider –t crawl mydomain mydomain.com
4、 运行spider
a) Scrapy crawl myspider
理解一个scrapy:
Spider.py :
1、 start_url:是要爬取的第一个URL地址,可以有多个值
2、 parse(response):是request请求的结果,使用response.text()获取页面信息。
3、 response是一个‘scrapy.http.response.html.HtmlResponse’对象,可以使用xpath和css来提取数据。
4、 提取出来的数据是一个‘selector’或者‘selectorList’对象,可以使用get(),或者getall()来获取内容。
5、 Getall()是获取一个列表,get()是获取列表的第一个值
6、 如果数据解析出来,可以使用yield一个一个返回,也可以一次使用return返回多个。
7、 Item:建议使用item,数据结构化处理,数据更清晰。
8、 Pipline:用来处理item数据:
a) Open_spider():再启动爬虫时执行,可以做一些预处理操作
b) Process_item():处理spider.py传过来的数据可以保存、去重等操作。
c) Close_spider():关闭爬虫时执行,坐一些善后操作。
注:要使用pipline,必须先在setting中激活pipline
Request 与 Response 请求与响应
Request:参数
1、 URL:request对象发送请求的URL
2、 Callback:请求之后的回调函数
3、 Method:默认Get,可以设置为其他方式,如果是post,建议使用formRequest
4、 Headers:请求头:对于一般固定的设置放在setting中,非固定的可以在发送请求的时候指定
5、 Meta:比较常用,用于在不同的请求之间使用传递使用
6、 Encoding:编码,默认是utf-8
7、 Dot_filter:表示不由调度器过滤,在使用多次重复请求的使用用的比较多,比如:验证码失败的时候
8、 Errback:在发生错误的时候执行的函数。
Response:对象属性,可以用来提取数据
1、 meta:从其他请求传过来的meta属性,可以用来保持多个请求之间的数据连接
2、 encoding:返回当前字符串编码和解码的格式
3、 text:将返回的数据作为Unicode字符串返回
4、 body:将返回的数据作为bytes字符串返回
5、 xpath:xpath选择器
6、 css:css选择器
POST请求:
1、重写‘start_requests’方法
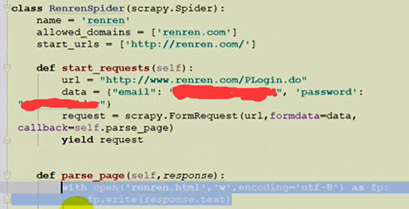
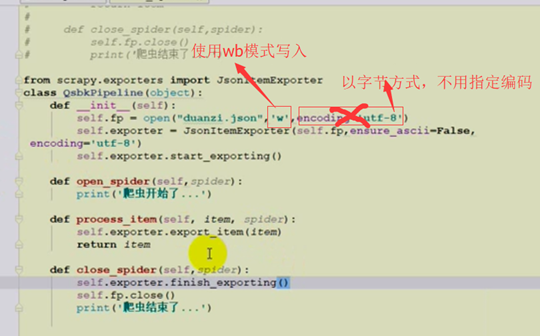
以json的形式导出:pipline操作
1、使用JSonItemExporter 先是保存在列表中,最后在finish一次写入,占用内存。满足json格式
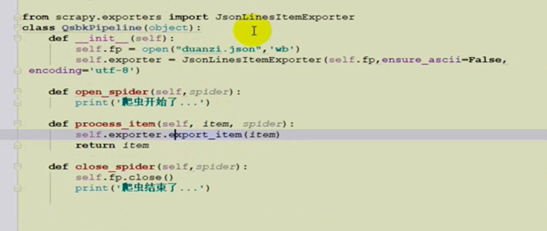
2、JsonLinerItemExporter、多次写入不是json格式,数据比较安全,防止发生意外
================crawlspider ====
需要使用“LinkExtrator”和“Rule”。这两个东西是(crawlspider)爬虫的主要内容。
1 、allow设置规则的方法:要能够限制在我们我们想要的URL上面,不要跟其他的URL产生相同的正则表达式即可。
2、使用Fallow的情况:如果在爬取页面的时候,需要将满足条件的URL连接进行跟进,那么就设置为True,否则设置为False。
3、callkack:如果这个URL对应的页面,只是为了获取更多的URL,并不需要里面的数据,那么可以不指定callkack。如果想要获取URL对应的页面的数据,那么就需要指定一个callback。
===========scrapy shell URL==========
1、可以方便我们做一些数据提取的测试代码。
2、如果想要执行scrapy命令,要先进入scrapy的环境中
3、如果想要读取某个项目的配置信息,那么应该先进入这个项目,在执行“scrapy shell URL”命令。
反 爬虫:
验证码:阿里云接口识别
File pipline文件下载管道
image pipline图片下载管道
下载器中间件:自定义 重写两个方法
1、process_request()
参数1:request 发送请求的request
参数2:spider 发送请求的spider
返回值:
1、 None: 如果返回none,scrapy继续执行该请求,执行其他的中间件的相应方法,直到合适的下载器函数被相应调用。
2、 Response: 如果返回response,那么scrapy将不会调用其他的process_request方法,将直接返回这个response对象,已经激活的中间件的process_response方法则会在每个response返回时调用
3、 Request :不再使用之前的request对象去下载数据,而是根据现在返回的request对象返回数据
4、 如果这个方法抛出异常,则会调用process_exception方法
2、process_response()
参数:
1、 request:请求对象
2、 response:被处理的response对象
3、 spider:spider对象
返回值:
1、 response:会将这个新的response对象传递给其他中间件,最终给爬虫
2、 request:下载器链被切断,返回的request会重新被下载器调度下载
3、 异常:那么将调用request的errback方法,如果没有指定这个方法,那么会抛出异常