flink wordcount 代码及相关知识点总结:
package com.lw.myflinkproject; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.operators.Order; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.LocalEnvironment; import org.apache.flink.api.java.operators.*; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.core.fs.FileSystem; import org.apache.flink.util.Collector; import java.util.List; /** * 1.Flink处理数据分为批处理数据 ,流式处理数据,SQL处理数据 * 2.Flink中的数据分为有界数据,无界数据。批处理的数据就是有界数据,流处理的数据有有界数据也有无界数据。 * 3.Flink处理数据规则: Source -> transformations ->Sink * 4.Flink和Spark的区别: * 1).Flink和Spark都是计算框架,都有批处理,SQL处理,流式处理,Flink吞吐量高,延迟低,Spark吞吐量高,延迟高。 * 2).Spark中批次处理底层是RDD,Flink底层是DataSet * Spark中流数据底层是DStream,Flink 底层是DataStream * 3).Spark编程是K,V格式的编程模型,Flink不是K,V格式的编程模型。 * 4).Spark中的RDD需要action触发执行,Flink中的transformation执行需要env.execute()触发执行。 * 5).Spark 批处理中可以根据key排序,Flink中只有分区内排序,没有全局排序
* 6).spark中是由driver进行task发送,flink中是由jobmanager进行task发送的 * 5.Flink处理数据流程: * 1).需要创建Flink环境: * 处理批数据: * 本地执行:ExecutionEnvironment.createLocalEnvironment(); --可以不用这种方式,直接使用集群方式。 * 集群执行:ExecutionEnvironment.getExecutionEnvironment(); * 处理流数据: * StreamExecutionEnvironment.getExecutionEnvironment(); * 2).source -> transformations -> sink * 3).使用env.execute()触发执行。在批处理中特殊的算子 有 print,count,collect 既有sink功能,还有触发功能。 * * 6.注意: * 1).本地运行Flink,并行度是8,与当前机器的Cpu的线程数相同,集群中运行的并行度就是1。 * 2).在Flink中只有在分区内排序,没有全局排序。 * 3).可以将数据保存成csv格式的数据,但是数据必须是tuple格式 * */ public class FlinkWordCount { public static void main(String[] args) throws Exception { // LocalEnvironment env = ExecutionEnvironment.createLocalEnvironment(); ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); DataSource<String> dataSource = env.readTextFile("./data/words"); FlatMapOperator<String, String> words = dataSource.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String line, Collector<String> collector) throws Exception { String[] split = line.split(" "); for (String word : split) { collector.collect(word); } } }); MapOperator<String, Tuple2<String, Integer>> map = words.map(new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String word) throws Exception { return new Tuple2<>(word, 1); } }); UnsortedGrouping<Tuple2<String, Integer>> groupBy = map.groupBy(0); AggregateOperator<Tuple2<String, Integer>> sum = groupBy.sum(1).setParallelism(1); SortPartitionOperator<Tuple2<String, Integer>> sort = sum.sortPartition(1, Order.DESCENDING); DataSink<Tuple2<String, Integer>> tuple2DataSink = sort.writeAsCsv("./data/result", FileSystem.WriteMode.OVERWRITE); env.execute("xx"); // long count = sort.count(); // System.out.println("count = "+count); // List<Tuple2<String, Integer>> collect = sort.collect(); // for (Tuple2<String, Integer> stringIntegerTuple2 : collect) { // System.out.println(stringIntegerTuple2); // } // sort.print(); // sort.writeAsText("./data/result",FileSystem.WriteMode.OVERWRITE); // env.execute("xxxx"); } }
pom 文件:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.lw.myflinkproject</groupId> <artifactId>MyFilnk0519</artifactId> <version>1.0-SNAPSHOT</version> <name>MyFilnk0519</name> <!-- FIXME change it to the project's website --> <url>http://www.example.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <flink.version>1.7.1</flink.version> </properties> <dependencies> <!-- Flink 依赖 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-wikiedits_2.11</artifactId> <version>${flink.version}</version> </dependency> <!-- Flink Kafka连接器的依赖 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <!-- log4j 和slf4j 包,如果在控制台不想看到日志,可以将下面的包注释掉--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.25</version> <scope>test</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-nop</artifactId> <version>1.7.25</version> <scope>test</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>1.7.5</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.4</version> <configuration> <!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” --> <!--<appendAssemblyId>false</appendAssemblyId>--> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>com.lw.myflink.Streaming.FlinkSocketWordCount</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>assembly</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
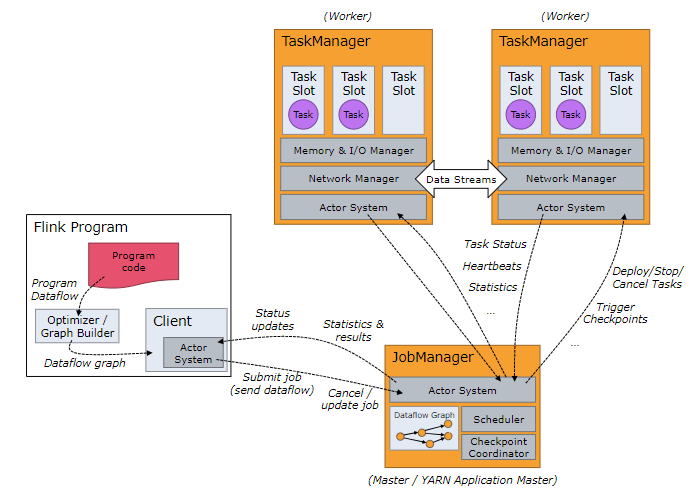
Flink运行时包含两种类型的进程:
- JobManger:也叫作masters,协调分布式执行,调度task,协调checkpoint,协调故障恢复(存储整体状态外还保存算子状态)。在Flink程序中至少有一个JobManager,高可用可以设置多个JobManager,其中一个是Leader,其他都是standby状态。
- TaskManager:也叫workers,执行dataflow生成的task,负责缓冲数据,及TaskManager之间的交换数据(shuffle)。Flink程序中必须有一个TaskManager.
Flink程序可以运行在standalone集群,Yarn或者Mesos资源调度框架中。
clients不是Flink程序运行时的一部分,作用是向JobManager准备和发送dataflow,之后,客户端可以断开连接或者保持连接。
TaskSlots 任务槽:就是并行度,下图最大是3:(worker放大图)
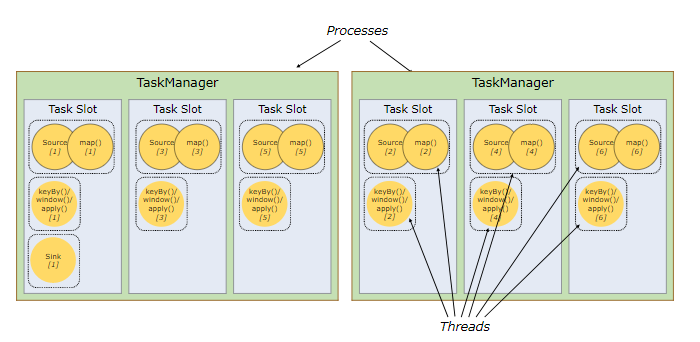
每个Worker(TaskManager)是一个JVM进程,可以执行一个或者多个task,这些task可以运行在任务槽上,每个worker上至少有一个任务槽。每个任务槽都有固定的资源,例如:TaskManager有三个TaskSlots,那么每个TaskSlot会将TaskMananger中的内存均分,即每个任务槽的内存是总内存的1/3。任务槽的作用就是分离任务的托管内存,不会发生cpu隔离。(整体3g,3个task,每个task就1g内存。即使不用,别的task也拿不走。每个task处理一条链)
通过调整任务槽的数据量,用户可以指定每个TaskManager有多少任务槽,更多的任务槽意味着更多的task可以共享同一个JVM,同一个JVM中的task共享TCP连接和心跳信息,共享数据集和数据结构,从而减少TaskManager中的task开销。
总结:task slot的个数代表TaskManager可以并行执行的task数。
flink集群的搭建:
1、上传安装包,解压
2、更改配置文件:
在sleaves文件中添加worker节点的节点名称
在flink-conf.yaml文件中配置jobmanager节点的节点名称 jobmanager.rpc.address: mynode1
3、将配置好的文件分发到其他的节点
scp -r ./flink mynode2:`pwd`
启动flink: ./start-cluster.sh
启动之后去前台页面进行查看: mynode1:8081
将本地代码打成jar包提交到集群的过程:在集群中进行提交的方式有两种,第一种是在页面进行提交,第二种是在集群用命令进行提交
用命令提交的方式: 1、首先在maven projects 中用clear 清空target包中的内容
2、执行parget 进行打包,完成之后将jar包上传到集群
3、在flink bin 目录下执行程序: ./flink run -c com.flink.studey.stream.SocketSimple /opt/wcg/localdir/flinktest1-1.0-SNAPSHOT-jar-with-dependencies.jar --port 9999
4、查看运行结果: 在前端页面 Task manager中进行查看程序的运行结果
注: 在将maven项目打成jar包的时候,第一次运行失败了,失败的主要原因:
由于在配置pom文件时没有配置将项目打成jar包的配置选项,导致文件生成jar包失败
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<!-- 设置false后是去掉 MySpark-1.0-SNAPSHOT-jar-with-dependencies.jar 后的 “-jar-with-dependencies” -->
<!--<appendAssemblyId>false</appendAssemblyId>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.lw.myflink.Streaming.FlinkSocketWordCount</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
在本地运行flink是没有webui的,所以想要看webui需要在集群进行提交
可以在前台页面将运行的任务终止。
flink对于与kafka关联操作的时候,offset即可以手动设置也可以自动设置。
对于kafka两阶段提交数据机制可以有效保证数据不发生丢失。
package com.lw.myflink.Streaming.kafka; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.java.tuple.Tuple; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011; import org.apache.flink.util.Collector; import java.util.Properties; public class ReadMessageFromKafkaAndUseFileSink { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // env.setParallelism(2);//设置并行度 env.enableCheckpointing(15000); // env.setStateBackend() // StateBackend stateBackend = env.getStateBackend(); // System.out.println("----"+stateBackend); Properties props = new Properties(); props.setProperty("bootstrap.servers", "mynode1:9092,mynode2:9092,mynode3:9092"); props.setProperty("group.id", "g0517"); props.setProperty("auto.offset.reset", "earliest"); props.setProperty("enable.auto.commit", "false"); /** * 第一个参数是topic * 第二个参数是value的反序列化格式 * 第三个参数是kafka配置 */ FlinkKafkaConsumer011<String> consumer011 = new FlinkKafkaConsumer011<>("FlinkTopic", new SimpleStringSchema(), props); // consumer011.setStartFromEarliest();//从topic的最早位置offset位置读取数据 // consumer011.setStartFromLatest();//从topic的最新位置offset来读取数据 consumer011.setStartFromGroupOffsets();//默认,将从kafka中找到消费者组消费的offset的位置,如果没有会按照auto.offset.reset 的配置策略 // consumer011.setStartFromTimestamp(111111);//从指定的时间戳开始消费数据 consumer011.setCommitOffsetsOnCheckpoints(true); DataStreamSource<String> stringDataStreamSource = env.addSource(consumer011); SingleOutputStreamOperator<String> flatMap = stringDataStreamSource.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String s, Collector<String> outCollector) throws Exception { String[] split = s.split(" "); for (String currentOne : split) { outCollector.collect(currentOne); } } }); //注意这里的tuple2需要使用org.apache.flink.api.java.tuple.Tuple2 这个包下的tuple2 SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String word) throws Exception { return new Tuple2<>(word, 1); } }); //keyby 将数据根据key 进行分区,保证相同的key分到一起,默认是按照hash 分区 KeyedStream<Tuple2<String, Integer>, Tuple> keyByResult = map.keyBy(0); WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowResult = keyByResult.timeWindow(Time.seconds(5)); SingleOutputStreamOperator<Tuple2<String, Integer>> endResult = windowResult.sum(1); //sink 直接控制台打印 //执行flink程序,设置任务名称。console 控制台每行前面的数字代表当前数据是哪个并行线程计算得到的结果 // endResult.print(); //sink 将结果存入文件,FileSystem.WriteMode.OVERWRITE 文件目录存在就覆盖 // endResult.writeAsText("./result/kafkaresult",FileSystem.WriteMode.OVERWRITE); // endResult.writeAsText("./result/kafkaresult",FileSystem.WriteMode.NO_OVERWRITE); //sink 将结果存入kafka topic中,存入kafka中的是String类型,所有endResult需要做进一步的转换 // FlinkKafkaProducer011<String> producer = new FlinkKafkaProducer011<>("node1:9092,node2:9092,node3:9092","FlinkResult",new SimpleStringSchema()); //将tuple2格式数据转换成String格式 endResult.map(new MapFunction<Tuple2<String,Integer>, String>() { @Override public String map(Tuple2<String, Integer> tp2) throws Exception { return tp2.f0+"-"+tp2.f1; } })/*.setParallelism(1)*/.addSink(new MyTransactionSink()).setParallelism(1); //最后要调用execute方法启动flink程序 env.execute("kafka word count"); } }
package com.lw.myflink.Streaming.kafka; import org.apache.flink.api.common.ExecutionConfig; import org.apache.flink.api.common.typeutils.base.VoidSerializer; import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer; import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction; import java.io.*; import java.util.*; import static org.apache.flink.util.Preconditions.checkArgument; import static org.apache.flink.util.Preconditions.checkNotNull; import static org.apache.flink.util.Preconditions.checkState; public class MyTransactionSink extends TwoPhaseCommitSinkFunction<String, MyTransactionSink.ContentTransaction, Void> { private ContentBuffer contentBuffer = new ContentBuffer(); public MyTransactionSink() { super(new KryoSerializer<>(ContentTransaction.class, new ExecutionConfig()),VoidSerializer.INSTANCE); } @Override /** * 当有数据时,会执行到这个invoke方法 * 2执行 */ protected void invoke(ContentTransaction transaction, String value, Context context){ System.out.println("====invoke===="+value); transaction.tmpContentWriter.write(value); } @Override /** * 开启一个事务,在临时目录下创建一个临时文件,之后,写入数据到该文件中 * 1执行 */ protected ContentTransaction beginTransaction() { ContentTransaction contentTransaction= new ContentTransaction(contentBuffer.createWriter(UUID.randomUUID().toString())); System.out.println("====beginTransaction====,contentTransaction Name = "+contentTransaction.toString()); // return new ContentTransaction(tmpDirectory.createWriter(UUID.randomUUID().toString())); return contentTransaction; } @Override /** * 在pre-commit阶段,flush缓存数据块到磁盘,然后关闭该文件,确保再不写入新数据到该文件。同时开启一个新事务执行属于下一个checkpoint的写入操作 * 3执行 */ protected void preCommit(ContentTransaction transaction) throws InterruptedException { System.out.println("====preCommit====,contentTransaction Name = "+transaction.toString()); System.out.println("pre-Commit----正在休息5s"); Thread.sleep(5000); System.out.println("pre-Commit----休息完成5s"); transaction.tmpContentWriter.flush(); transaction.tmpContentWriter.close(); } @Override /** * 在commit阶段,我们以原子性的方式将上一阶段的文件写入真正的文件目录下。这里有延迟 * 4执行 */ protected void commit(ContentTransaction transaction) { System.out.println("====commit====,contentTransaction Name = "+transaction.toString()); /** * 实现写入文件的逻辑 */ //获取名称 String name = transaction.tmpContentWriter.getName(); //获取数据 Collection<String> content = contentBuffer.read(name); /** * 测试打印 */ for(String s: content){ // if("hello-1".equals(s)){ // try { // System.out.println("正在休息5s"); // Thread.sleep(5000); // System.out.println("休息完成5s"); // } catch (InterruptedException e) { // e.printStackTrace(); // } // } System.out.println(s); } // //将数据写入文件 // FileWriter fw =null; // PrintWriter pw =null ; // try { // //如果文件存在,则追加内容;如果文件不存在,则创建文件 // File dir=new File("./data/FileResult/result.txt"); // if(!dir.getParentFile().exists()){ // dir.getParentFile().mkdirs();//创建父级文件路径 // dir.createNewFile();//创建文件 // } // fw = new FileWriter(dir, true); // pw = new PrintWriter(fw); // for(String s:content){ // if(s.equals("sss-1")){ // throw new NullPointerException(); // } // pw.write(s+" "); // } // } catch (IOException e) { // e.printStackTrace(); // } // try { // pw.flush(); // fw.flush(); // pw.close(); // fw.close(); // } catch (IOException e) { // e.printStackTrace(); // } } @Override /** * 一旦有异常终止事务时,删除临时文件 */ protected void abort(ContentTransaction transaction) { System.out.println("====abort===="); transaction.tmpContentWriter.close(); contentBuffer.delete(transaction.tmpContentWriter.getName()); } public static class ContentTransaction { private ContentBuffer.TempContentWriter tmpContentWriter; public ContentTransaction(ContentBuffer.TempContentWriter tmpContentWriter) { this.tmpContentWriter = tmpContentWriter; } @Override public String toString() { return String.format("ContentTransaction[%s]", tmpContentWriter.getName()); } } } /** * ContentBuffer 类中 放临时的处理数据到一个list中 */ class ContentBuffer implements Serializable { private Map<String, List<String>> filesContent = new HashMap<>(); public TempContentWriter createWriter(String name) { checkArgument(!filesContent.containsKey(name), "File [%s] already exists", name); filesContent.put(name, new ArrayList<>()); return new TempContentWriter(name, this); } private void putContent(String name, List<String> values) { List<String> content = filesContent.get(name); checkState(content != null, "Unknown file [%s]", name); content.addAll(values); } public Collection<String> read(String name) { List<String> content = filesContent.get(name); checkState(content != null, "Unknown file [%s]", name); List<String> result = new ArrayList<>(content); return result; } public void delete(String name) { filesContent.remove(name); } //内部类 class TempContentWriter { private final ContentBuffer contentBuffer; private final String name; private final List<String> buffer = new ArrayList<>(); private boolean closed = false; public String getName() { return name; } private TempContentWriter(String name, ContentBuffer contentBuffer) { this.name = checkNotNull(name); this.contentBuffer = checkNotNull(contentBuffer); } public TempContentWriter write(String value) { checkState(!closed); buffer.add(value); return this; } public TempContentWriter flush() { contentBuffer.putContent(name, buffer); return this; } public void close() { buffer.clear(); closed = true; } } }