关于rabbitmq
1 简单介绍rabbitmq
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而聚类和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
2.为什么使用mq,rabbitmq相对其他列队的优势?
mq主要是做程序异步处理,服务解耦,流量削峰,顺序处理保证,程序扩展性等
与一些主流消息中间比较
| 维度mq | rabbitmq | Kafka | ZeroMQ | RocketMQ | ActiveMQ |
| 开发语言 | Erlang | Scala | c | java | java |
| 支持协议 | amqp | 基于tcp自定义一套 |
tcpudp |
自定义 |
n多 |
| 消息存储 |
rabbitmq的消息分为持久化的消息和非持久化消息,不管是持久化的消息还是非持久化的消息都可以写入到磁盘。 持久化的消息在到达队列时就写入到磁盘,并且如果可以,持久化的消息也会在内存中保存一份备份,这样可以提高一定的性能,当内存吃紧的时候会从内存中清除。非持久化的消息一般只存在于内存中,在内存吃紧的时候会被换入到磁盘中,以节省内存。 引入镜像队列机制,可将重要队列“复制”到集群中的其他broker上,保证这些队列的消息不会丢失。配置镜像的队列,都包含一个主节点master和多个从节点slave,如果master失效,加入时间最长的slave会被提升为新的master,除发送消息外的所有动作都向master发送,然后由master将命令执行结果广播给各个slave,rabbitmq会让master均匀地分布在不同的服务器上,而同一个队列的slave也会均匀地分布在不同的服务器上,保证负载均衡和高可用性。 |
kafka的最小存储单元是分区,一个topic包含多个分区,kafka创建主题时,这些分区会被分配在多个服务器上,通常一个broker一台服务器。 分区首领会均匀地分布在不同的服务器上,分区副本也会均匀的分布在不同的服务器上,确保负载均衡和高可用性,当新的broker加入集群的时候,部分副本会被移动到新的broker上。 根据配置文件中的目录清单,kafka会把新的分区分配给目录清单里分区数最少的目录。 默认情况下,分区器使用轮询算法把消息均衡地分布在同一个主题的不同分区中,对于发送时指定了key的情况,会根据key的hashcode取模后的值存到对应的分区中。 | 消息发送端的内存或者磁盘中。不支持持久化。 |
commitLog文件存放实际的消息数据,每个commitLog上限是1G,满了之后会自动新建一个commitLog文件保存数据。ConsumeQueue队列只存放offset、size、tagcode,非常小,分布在多个broker上。ConsumeQueue相当于CommitLog的索引文件,消费者消费时会从consumeQueue中查找消息在commitLog中的offset,再去commitLog中查找元数据。 ConsumeQueue存储格式的特性,保证了写过程的顺序写盘(写CommitLog文件),大量数据IO都在顺序写同一个commitLog,满1G了再写新的。加上rocketmq是累计4K才强制从PageCache中刷到磁盘(缓存),所以高并发写性能突出。 |
内存、磁盘、数据库。支持少量堆积。 |
| 消息事物 | y(支持。 客户端将信道设置为事务模式,只有当消息被rabbitMq接收,事务才能提交成功,否则在捕获异常后进行回滚。使用事务会使得性能有所下降 ) | y | n | y | y |
| 管理界面 | just so so | good | 没有 | 目测没有 | gust so so |
| 消息重复性 | 支持at least once、at most once | 支持at least once、at most once |
只有重传机制,但是没有持久化,消息丢了重传也没有用。既不是at least once、也不是at most once、更不是exactly only once |
支持at least once | 支持at least once |
| tps | 比较大(万) | 极大 Kafka按批次发送消息和消费消息。发送端将多个小消息合并,批量发向Broker,消费端每次取出一个批次的消息批量处理。(十万) | 极大 | 大(rocketMQ接收端可以批量消费消息,可以配置每次消费的消息数,但是发送端不是批量发送。 )(以前是万-->十万) | 比较大(万) |
| 订阅形式和消息分发 | 提供了4种:direct, topic ,Headers和fanout。 | 基于topic以及按照topic进行正则匹配的发布订阅模式。 | p2p(point to point) | 基于topic/messageTag以及按照消息类型、属性进行正则匹配的发布订阅模式。 |
点对点(p2p)、广播(发布-订阅) |
| 消息回溯 | n | 支持指定分区offset位置的回溯 | n | 支持指定时间点的回溯 | n |
3.rabbitmq的交换机的概念,以及交换有哪些?
交换机:我认为它就是一种逻辑分发消息的形式,类似一种路由机制,根据类型来分发消息一个组件。
rabbitmq的交换有4种:direct, topic ,Headers和fanout。




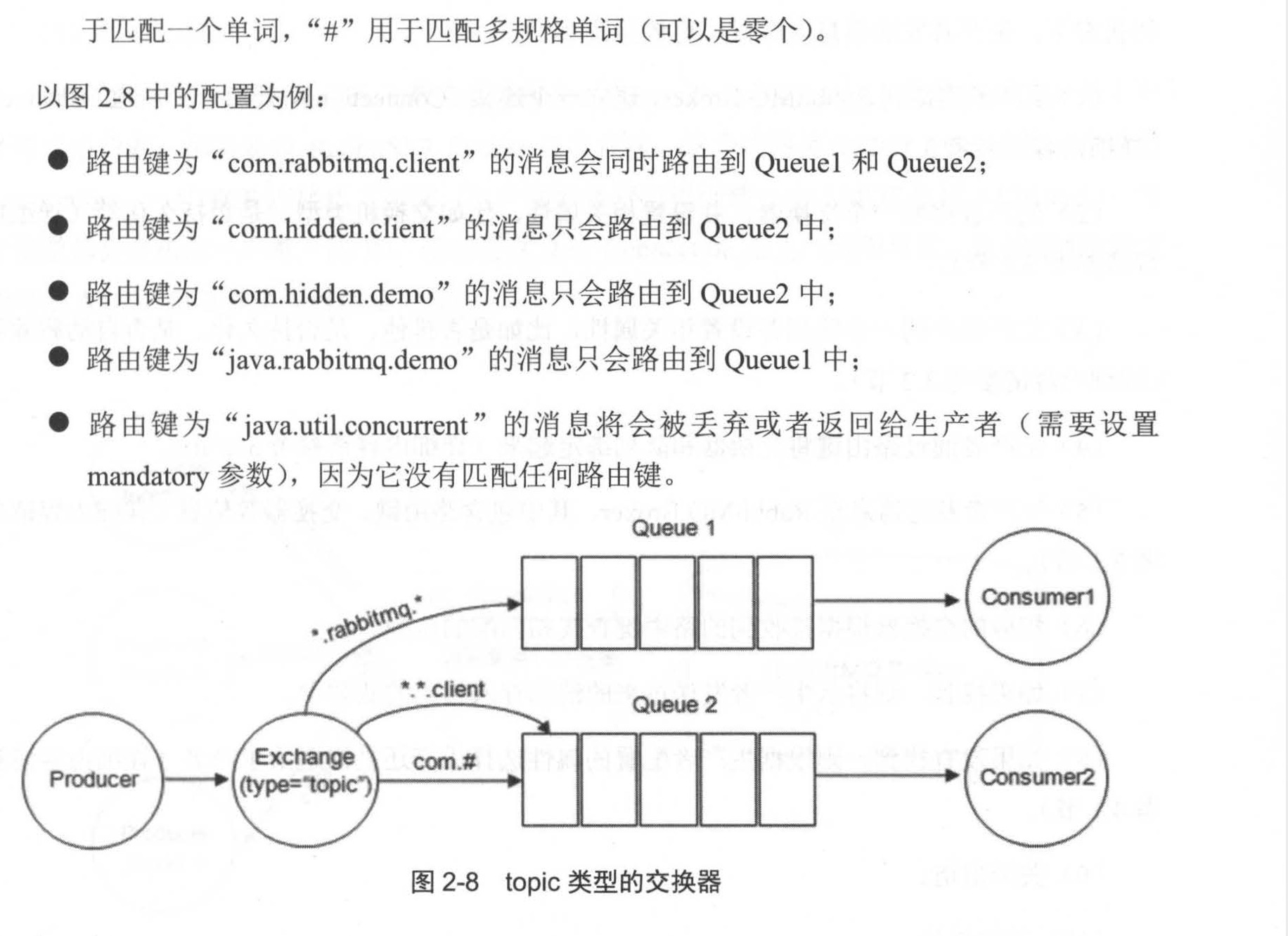
摘抄---->rabbitmq实战指南。
4>关于springboot集成rabbitmq
略
5>关于搭建rabbitmq集群
普通集群:
意思就是在多台机器上启动多个rabbitmq实例,每个机器启动一个。但是你创建的queue,只会放在一个rabbtimq实例上,但是每个实例都同步queue的元数据(存放真正实例位置)。消费的时候,实际上如果连接到了另外一个实例,那么那个实例会从queue所在实例上拉取数据过来。
这种方式确实很麻烦,也不怎么好,没做到所谓的分布式,就是个普通集群。
因为这导致你要么消费者每次随机连接一个实例然后拉取数据,要么固定连接那个queue所在实例消费数据,前者有数据拉取的开销,后者导致单实例性能瓶颈。
而且如果那个放queue的实例宕机了,会导致接下来其他实例就无法从那个实例拉取,如果你开启了消息持久化,让rabbitmq落地存储消息的话,消息不一定会丢,得等这个实例恢复了,然后才可以继续从这个queue拉取数据。
所以这个普通集群比较尴尬了,这就没有什么所谓的高可用性可言了,这方案主要是提高吞吐量的,就是说让集群中多个节点来服务某个queue的读写操作。好处就是:几分钟就搭建好了 - -。
不好的地方:集群内部大量消息传输,可用性基本没有什么保证,如果如果数据所在的队列挂了,消息没有持久化,就会丢失,没法消费。
镜像集群:
镜像集群模式
好处在于,你任何一个机器宕机了,没事儿,别的机器都可以用。
坏处在于
- 1>,这个性能开销也太大了吧,消息同步所有机器,导致网络带宽压力和消耗很重!
- 2>,这么玩儿,就没有扩展性可言了,如果某个queue负载很重,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue
那么怎么开启这个镜像集群模式呢?我这里简单说一下,其实很简单rabbitmq有很好的管理控制台,我们可以在后台新增一个策略,这个策略是镜像集群模式的策略,可以指定要求数据同步到所有节点,也可以要求同步到指定数量的节点,然后你再次创建queue的时候,应用这个策略,就会自动将数据同步到其他的节点上去了
6>关于rabbitmq特殊的队列介绍
1>死信队列
2>优先级队列
3>延迟队列
暂时就这样吧: