一、前言
Celery是一个基于python开发的分布式任务队列,如果不了解请阅读笔者上一篇博文Celery入门与进阶,而做python WEB开发最为流行的框架莫属Django,但是Django的请求处理过程都是同步的无法实现异步任务,若要实现异步任务处理需要通过其他方式(前端的一般解决方案是ajax操作),而后台Celery就是不错的选择。倘若一个用户在执行某些操作需要等待很久才返回,这大大降低了网站的吞吐量。下面将描述Django的请求处理大致流程(图片来源于网络):
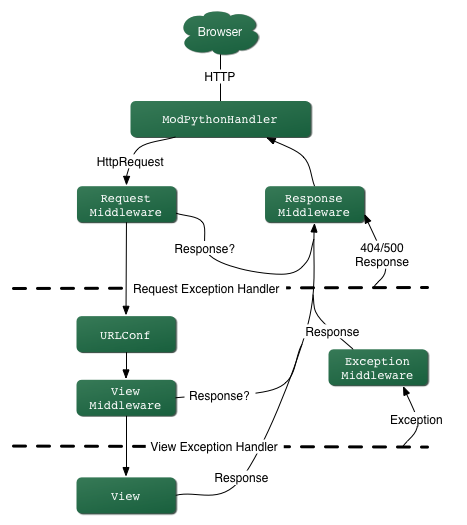
请求过程简单说明:浏览器发起请求-->请求处理-->请求经过中间件-->路由映射-->视图处理业务逻辑-->响应请求(template或response)
二、配置使用
celery很容易集成到Django框架中,当然如果想要实现定时任务的话还需要安装django-celery-beta插件,后面会说明。需要注意的是Celery4.0只支持Django版本>=1.8的,如果是小于1.8版本需要使用Celery3.1。
配置
新建立项目taskproj,目录结构(每个app下多了个tasks文件,用于定义任务):
taskproj ├── app01 │ ├── __init__.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tasks.py │ └── views.py ├── manage.py ├── taskproj │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates
在项目目录taskproj/taskproj/目录下新建celery.py:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # Author:wd from __future__ import absolute_import, unicode_literals import os from celery import Celery os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'taskproj.settings') # 设置django环境 app = Celery('taskproj') app.config_from_object('django.conf:settings', namespace='CELERY') # 使用CELERY_ 作为前缀,在settings中写配置 app.autodiscover_tasks() # 发现任务文件每个app下的task.py
taskproj/taskproj/__init__.py:
from __future__ import absolute_import, unicode_literals
from .celery import app as celery_app
__all__ = ['celery_app']
taskproj/taskproj/settings.py
CELERY_BROKER_URL = 'redis://10.1.210.69:6379/0' # Broker配置,使用Redis作为消息中间件 CELERY_RESULT_BACKEND = 'redis://10.1.210.69:6379/0' # BACKEND配置,这里使用redis CELERY_RESULT_SERIALIZER = 'json' # 结果序列化方案
进入项目的taskproj目录启动worker:
celery worker -A taskproj -l debug
定义与触发任务
任务定义在每个tasks文件中,app01/tasks.py:
from __future__ import absolute_import, unicode_literals from celery import shared_task @shared_task def add(x, y): return x + y @shared_task def mul(x, y): return x * y
视图中触发任务
from django.http import JsonResponse from app01 import tasks # Create your views here. def index(request,*args,**kwargs): res=tasks.add.delay(1,3) #任务逻辑 return JsonResponse({'status':'successful','task_id':res.task_id})
访问http://127.0.0.1:8000/index

若想获取任务结果,可以通过task_id使用AsyncResult获取结果,还可以直接通过backend获取:

扩展
除了redis、rabbitmq能做结果存储外,还可以使用Django的orm作为结果存储,当然需要安装依赖插件,这样的好处在于我们可以直接通过django的数据查看到任务状态,同时为可以制定更多的操作,下面介绍如何使用orm作为结果存储。
1.安装
pip install django-celery-results
2.配置settings.py,注册app
INSTALLED_APPS = ( ..., 'django_celery_results', )
4.修改backend配置,将redis改为django-db
#CELERY_RESULT_BACKEND = 'redis://10.1.210.69:6379/0' # BACKEND配置,这里使用redis CELERY_RESULT_BACKEND = 'django-db' #使用django orm 作为结果存储
5.修改数据库
python3 manage.py migrate django_celery_results
此时会看到数据库会多创建:
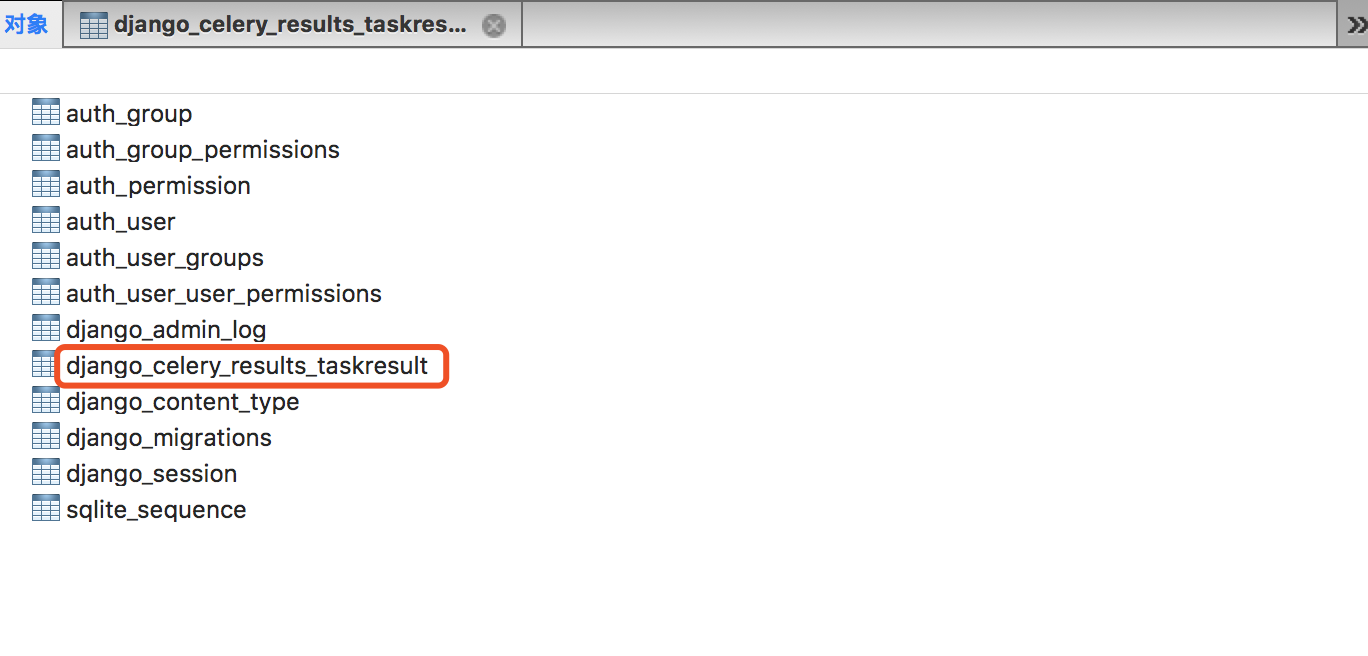 当然你有时候需要对task表进行操作,以下源码的表结构定义:
当然你有时候需要对task表进行操作,以下源码的表结构定义:
class TaskResult(models.Model): """Task result/status.""" task_id = models.CharField(_('task id'), max_length=255, unique=True) task_name = models.CharField(_('task name'), null=True, max_length=255) task_args = models.TextField(_('task arguments'), null=True) task_kwargs = models.TextField(_('task kwargs'), null=True) status = models.CharField(_('state'), max_length=50, default=states.PENDING, choices=TASK_STATE_CHOICES ) content_type = models.CharField(_('content type'), max_length=128) content_encoding = models.CharField(_('content encoding'), max_length=64) result = models.TextField(null=True, default=None, editable=False) date_done = models.DateTimeField(_('done at'), auto_now=True) traceback = models.TextField(_('traceback'), blank=True, null=True) hidden = models.BooleanField(editable=False, default=False, db_index=True) meta = models.TextField(null=True, default=None, editable=False) objects = managers.TaskResultManager() class Meta: """Table information.""" ordering = ['-date_done'] verbose_name = _('task result') verbose_name_plural = _('task results') def as_dict(self): return { 'task_id': self.task_id, 'task_name': self.task_name, 'task_args': self.task_args, 'task_kwargs': self.task_kwargs, 'status': self.status, 'result': self.result, 'date_done': self.date_done, 'traceback': self.traceback, 'meta': self.meta, } def __str__(self): return '<Task: {0.task_id} ({0.status})>'.format(self)
三、Django中使用定时任务
如果想要在django中使用定时任务功能同样是靠beat完成任务发送功能,当在Django中使用定时任务时,需要安装django-celery-beat插件。以下将介绍使用过程。
安装配置
1.beat插件安装
pip3 install django-celery-beat
2.注册APP
INSTALLED_APPS = [ .... 'django_celery_beat', ]
3.数据库变更
python3 manage.py migrate django_celery_beat
4.分别启动woker和beta
celery -A proj beat -l info --scheduler django_celery_beat.schedulers:DatabaseScheduler #启动beta 调度器使用数据库 celery worker -A taskproj -l info #启动woker
5.配置admin
urls.py
# urls.py from django.conf.urls import url from django.contrib import admin urlpatterns = [ url(r'^admin/', admin.site.urls), ]
6.创建用户
python3 manage.py createsuperuser
7.登录admin进行管理(地址http://127.0.0.1:8000/admin)并且还可以看到我们上次使用orm作为结果存储的表。
http://127.0.0.1:8000/admin/login/?next=/admin/

使用示例:
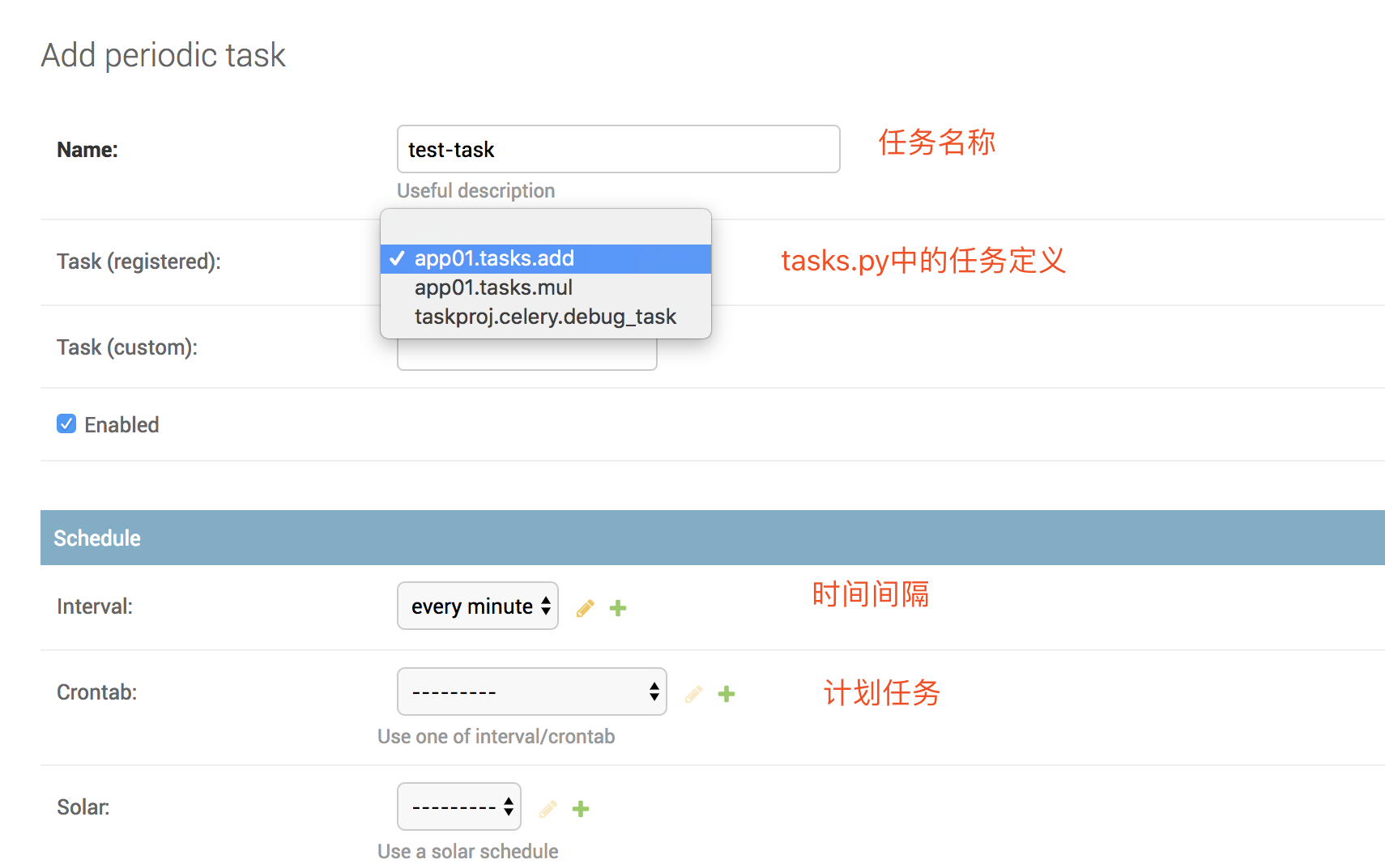

查看结果:
二次开发
django-celery-beat插件本质上是对数据库表变化检查,一旦有数据库表改变,调度器重新读取任务进行调度,所以如果想自己定制的任务页面,只需要操作beat插件的四张表就可以了。当然你还可以自己定义调度器,django-celery-beat插件已经内置了model,只需要进行导入便可进行orm操作,以下我用django reset api进行示例:
settings.py
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'app01.apps.App01Config', 'django_celery_results', 'django_celery_beat', 'rest_framework', ]
urls.py
urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^index$', views.index), url(r'^res$', views.get_res), url(r'^tasks$', views.TaskView.as_view({'get':'list'})), ]
views.py
from django_celery_beat.models import PeriodicTask #倒入插件model from rest_framework import serializers from rest_framework import pagination from rest_framework.viewsets import ModelViewSet class Userserializer(serializers.ModelSerializer): class Meta: model = PeriodicTask fields = '__all__' class Mypagination(pagination.PageNumberPagination): """自定义分页""" page_size=2 page_query_param = 'p' page_size_query_param='size' max_page_size=4 class TaskView(ModelViewSet): queryset = PeriodicTask.objects.all() serializer_class = Userserializer permission_classes = [] pagination_class = Mypagination
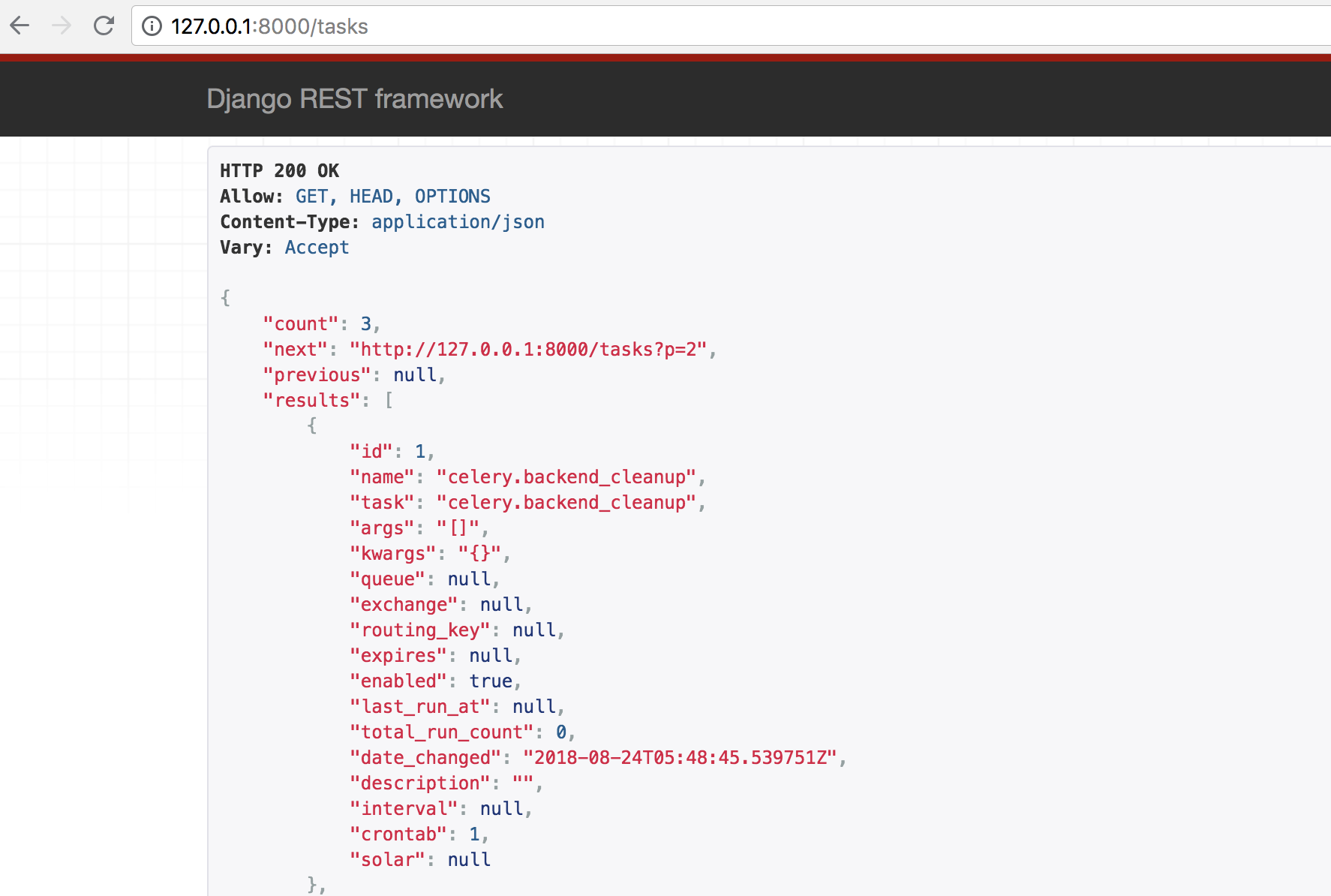
访问http://127.0.0.1:8000/tasks如下: