第二篇: CentOS7 配置hadoop (二) 配置hdfs(伪分布)
配置hdfs:
1.修改主机名
在CentOS 7中,我们可以通过hostname命令查看当前的主机名。

我们可以通过命令“hostnamectl set-hostname 主机名”来永久修改主机名。

vi /etc/hosts

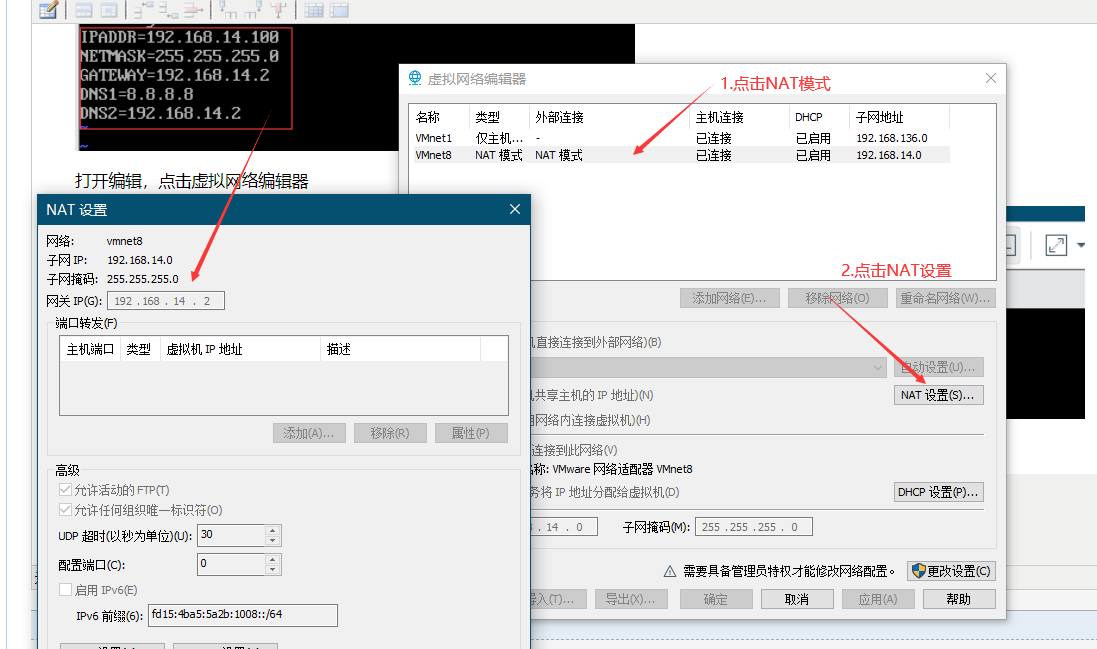
这里的红框内是在下面的NAT 设置的网络 网关 子网,其中 IPADDR 要和NAT 设置的 网关IP前三段一致 ,后一段不一样就可以
打开编辑,点击虚拟网络编辑器
注意IP的设置
设置完记得service network restart
查看IP 指令为 ip addr
3.配置静态IP地址,
使用命令 vi /etc/sysconfig/network-scripts/ifcfg-ens33

:wq! 保存并退出
4.查看IP 指令为 ip addr
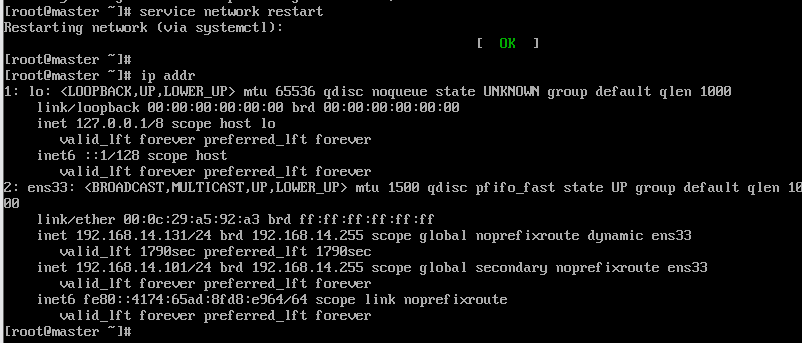
5.service network restart重启网络
6.在配置SSH无密码连接之前,需要关闭防火墙
关闭防火墙 service iptables stop
永久关闭防火墙 chkconfig iptables off

7. 检查SSH是否安装 (root用户执行 所有节点都需执行)
绝大多数系统已经附带SSH,但是预防万一,可以进行SSH安装
yum install ssh
yum install rsync
service sshd start启动SSH服务
检查SSH是否安装成功
rpm -qa | grep openssh
rpm -qa | grep rsync
配置ssh公钥 ssh-keygen -t rsa 一直回车就行
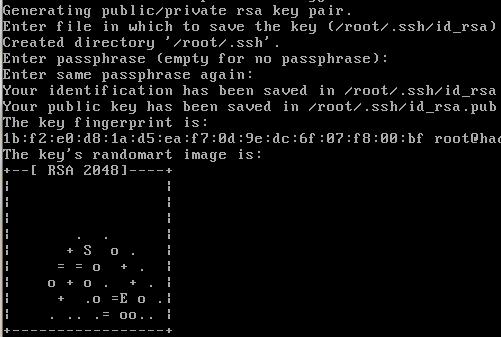
公钥生成位置 : /home/用户名/.ssh隐藏目录下 ls -a 查看隐藏目录
公钥拷贝至本机得zuthorized_key列表
ssh-copy-id -i ~/.ssh/id_rsa.pub 用户名@主机名(例master@master)
重启虚拟机
8.使用Xshell工具连接到
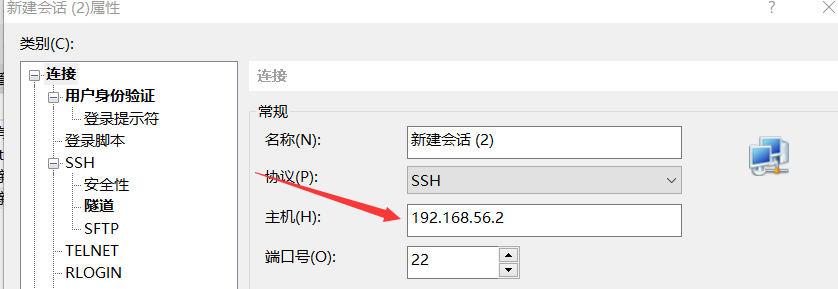
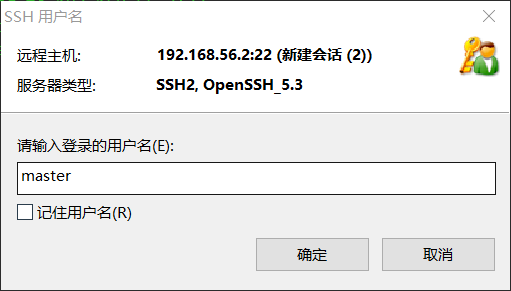

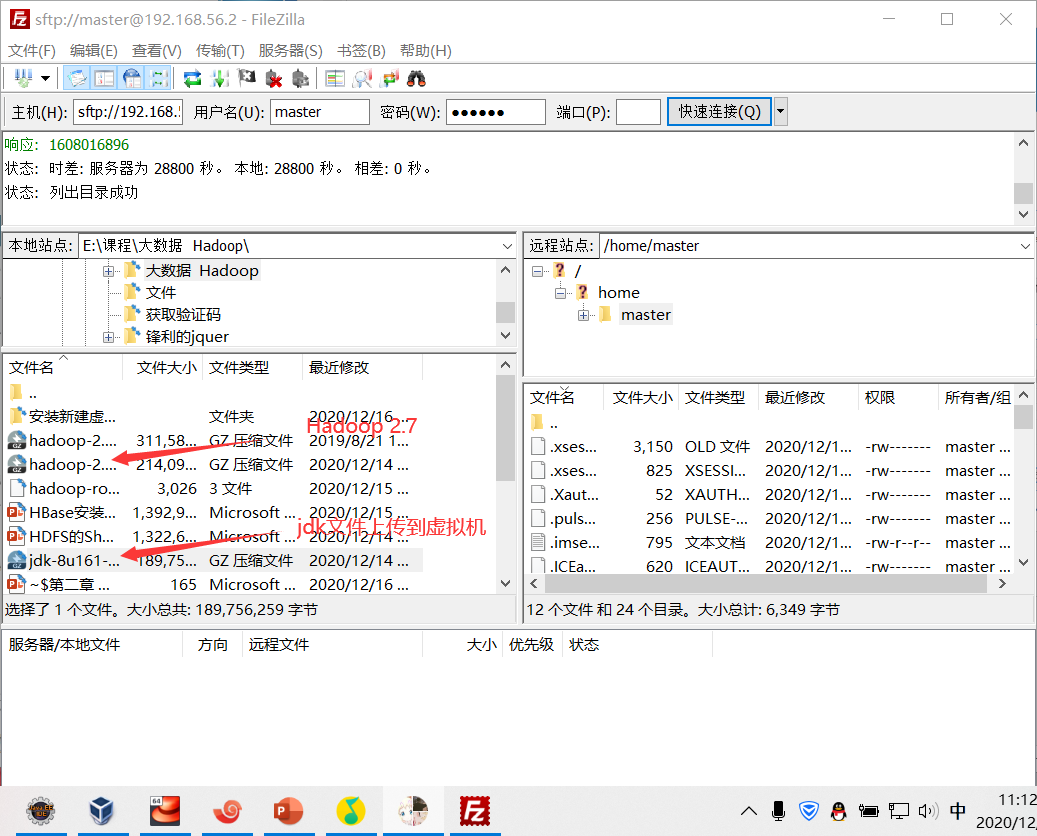
9.链接FileZilla

10.使用FileZilla上传文件到虚拟机 右键上传
卸载Open JDK root用户执行
查看当前系统jdk,如果出现openjdk则需要删除
rpm -qa | grep jdk
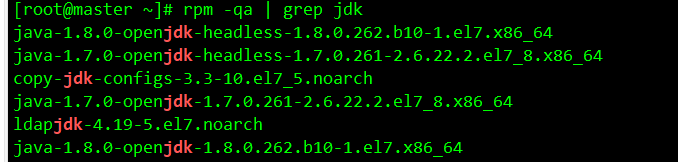
删除openjdk 命令 rpm -e --nodeps java....

11.上传完毕到xshell工具里解压两个tar压缩包 命令 tar -xzvf 压缩包名
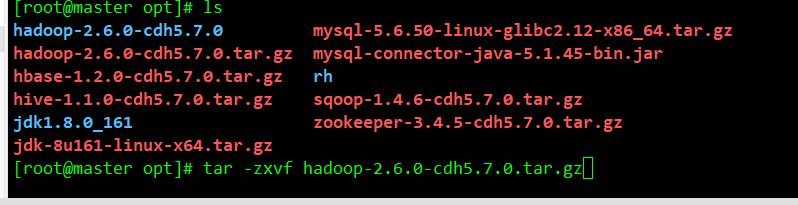
12.解压完成配置环境变量 vi /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.7.0
export PATH=$PATH:$HADOOP_HOME/bin
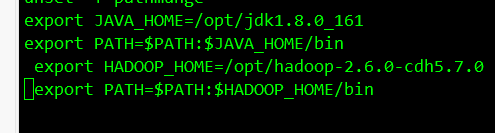
配置完环境变量记得 source /etc/profile
检查配置完成后的jdk版本
java -version

13.配置hadoop 先进入 cd /opt/hadoop-2.6.0-cdh5.7.0/etc/hadoop 文件目录下
1)修改hadoop-env.sh 文件
export JAVA_HOME=/opt/jdk1.8.0_161
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.7.0

2)修改core-site.xml 文件
<property>
<name>fs.default.name</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hdfs/tmp</value>
</property>
3)修改hdfs-site.xml文件
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/data/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/data/data</value>
</property>
4)修改mapred-site.xml文件 要先执行cp 命令(cp mapred-site.xml.template mapred-site.xml)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5)修改yarn-site.xml文件
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8080</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
6)修改slaves 文件
vi etc/hadoop/slaves
写入主机名(master)
14.格式化hdfs 命令hadoop namenode -format
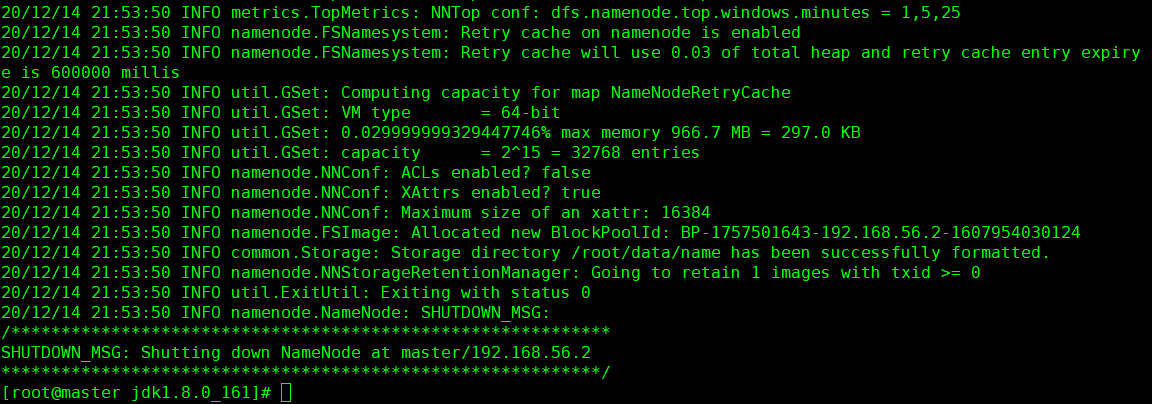
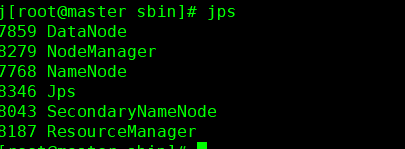
15 .启动hdfs 进入到 cd /opt/hadoop-2.6.0-cdh5.7.0/sbin/ 执行启动命令 ./start-all.sh 关闭命令 ./stop-all.sh
输入jps查看
作者:旧歌
链接:https://www.cnblogs.com/wdyjt/p/14142994.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利