Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门
https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6EmUbbW&id=564564604865
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import requests,bs4,openpyxl,time,selenium
from openpyxl.cell import get_column_letter,column_index_from_string
from selenium import webdriver
excelName="51job.xlsx"
sheetName="Sheet1"
wb1=openpyxl.load_workbook(excelName)
sheet=wb1.get_sheet_by_name(sheetName)
start=1
charset="gb2312"
site="http://jobs.51job.com/all/co198308.html"
browser=webdriver.Firefox()
browser.get(site)
linkElem=browser.find_element_by_link_text("下一页")
linkElem.click()
#elem = browser.find_element_by_class_name('el')
#返回标签的值
#elem.text
#elems = browser.find_elements_by_class_name('el')
elem=browser.find_elements_by_class_name('el')
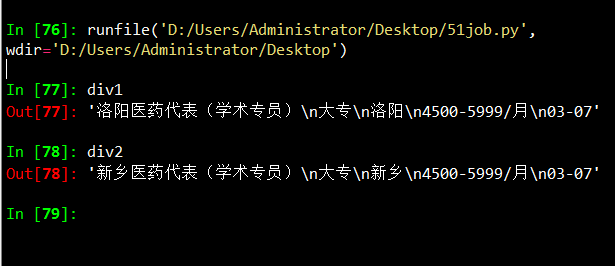
div1=elem[0].text
div2=elem[1].text
#每个网站爬取相应数据
def Craw(site):
res=requests.get(site)
res.encoding = charset
soup1=bs4.BeautifulSoup(res.text,"lxml")
div=soup1.select('.el')
len_div=len(div)
for i in range(len_div):
#print ("i:",i)
content=div[i].getText()
content_list=content.split('
')
name=content_list[1]
#print ("name:",name)
education=content_list[2]
#print ("education:",education)
position=content_list[3]
#print ("position:",position)
salary=content_list[4]
#print ("salary:",salary)
date=content_list[5]
#print ("date:",date)
sheet['A'+str(i+2)].value=name
sheet['B'+str(i+2)].value=education
sheet['C'+str(i+2)].value=position
sheet['D'+str(i+2)].value=salary
sheet['E'+str(i+2)].value=date
'''
Craw(site)
wb1.save(excelName)
'''
Finding Elements on the Page
WebDriver objects have quite a few methods for finding elements on a page. They are divided into the find_element_* and find_elements_* methods. Thefind_element_* methods return a single WebElement object, representing the first element on the page that matches your query. The find_elements_* methods return a list of WebElement_* objects for every matching element on the page.
Table 11-3 shows several examples of find_element_* and find_elements_* methods being called on a WebDriver object that’s stored in the variable browser.
Except for the *_by_tag_name() methods, the arguments to all the methods are case sensitive. If no elements exist on the page that match what the method is looking for, the selenium module raises a NoSuchElement exception. If you do not want this exception to crash your program, add try and except statements to your code.
Once you have the WebElement object, you can find out more about it by reading the attributes or calling the methods in Table 11-4.
Table 11-4. WebElement Attributes and Methods
|
Attribute or method |
Description |
|---|---|
|
|
The tag name, such as |
|
|
The value for the element’s |
|
|
The text within the element, such as |
|
|
For text field or text area elements, clears the text typed into it |
|
|
Returns |
|
|
For input elements, returns |
|
|
For checkbox or radio button elements, returns |
|
|
A dictionary with keys |
Table 11-5. Commonly Used Variables in the selenium.webdriver.common.keysModule
|
Attributes |
Meanings |
|---|---|
|
|
The keyboard arrow keys |
|
|
The ENTER and RETURN keys |
|
|
The |
|
|
The ESC, BACKSPACE, and DELETE keys |
|
|
The F1 to F12 keys at the top of the keyboard |
|
|
The TAB key |