sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

https://www.pythonprogramming.net/chinking-nltk-tutorial/?completed=/chunking-nltk-tutorial/
代码
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 13 09:14:13 2016
@author: daxiong
"""
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
#训练数据
train_text=state_union.raw("2005-GWBush.txt")
#测试数据
sample_text=state_union.raw("2006-GWBush.txt")
'''
Punkt is designed to learn parameters (a list of abbreviations, etc.)
unsupervised from a corpus similar to the target domain.
The pre-packaged models may therefore be unsuitable:
use PunktSentenceTokenizer(text) to learn parameters from the given text
'''
#我们现在训练punkttokenizer(分句器)
custom_sent_tokenizer=PunktSentenceTokenizer(train_text)
#训练后,我们可以使用punkttokenizer(分句器)
tokenized=custom_sent_tokenizer.tokenize(sample_text)
'''
nltk.pos_tag(["fire"]) #pos_tag(列表)
Out[19]: [('fire', 'NN')]
'''
'''
#测试语句
words=nltk.word_tokenize(tokenized[0])
tagged=nltk.pos_tag(words)
chunkGram=r"""Chunk:{<RB.?>*<VB.?>*<NNP>+<NN>?}"""
chunkParser=nltk.RegexpParser(chunkGram)
chunked=chunkParser.parse(tagged)
#lambda t:t.label()=='Chunk' 包含Chunk标签的列
for subtree in chunked.subtrees(filter=lambda t:t.label()=='Chunk'):
print(subtree)
'''
#文本词性标记函数
def process_content():
try:
for i in tokenized[0:5]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
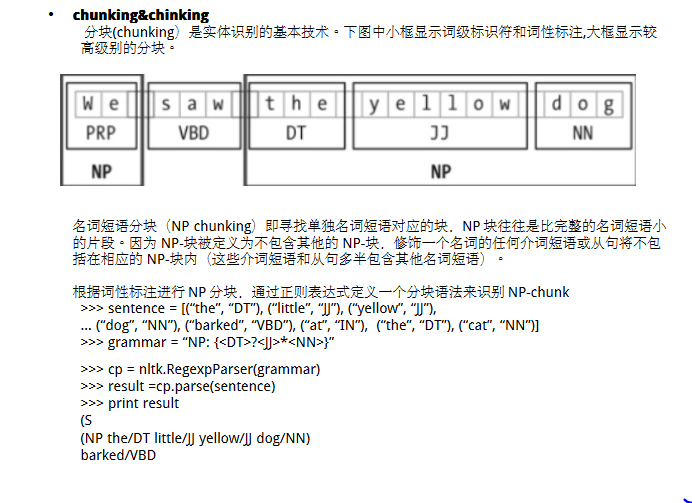
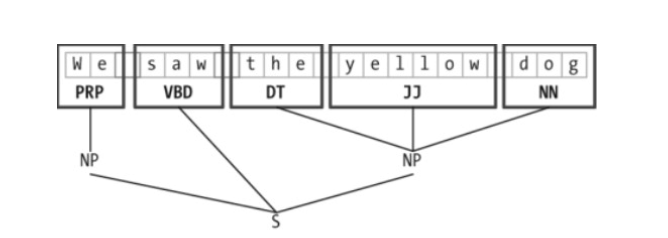
百度文库参考
http://wenku.baidu.com/link?url=YIrqeVS8a1zO_H0t66kj1AbUUReLUJIqId5So5Szk0JJAupyg_m2U_WqxEHqAHDy9DfmoAAPu0CdNFf-rePBsTHkx-0WDpoYTH1txFDKQxC


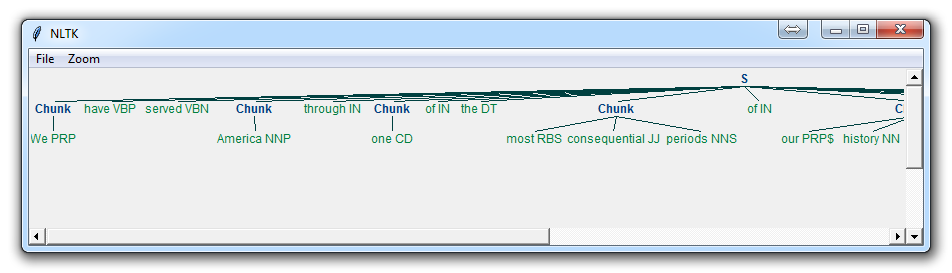
chinking可用于提取句子主干,去除不需要的修饰语
Chinking with NLTK
You may find that, after a lot of chunking, you have some words in your chunk you still do not want, but you have no idea how to get rid of them by chunking. You may find that chinking is your solution.
Chinking is a lot like chunking, it is basically a way for you to remove a chunk from a chunk. The chunk that you remove from your chunk is your chink.
The code is very similar, you just denote the chink, after the chunk, with }{ instead of the chunk's {}.
import nltk
from nltk.corpus import state_union
from nltk.tokenize import PunktSentenceTokenizer
train_text = state_union.raw("2005-GWBush.txt")
sample_text = state_union.raw("2006-GWBush.txt")
custom_sent_tokenizer = PunktSentenceTokenizer(train_text)
tokenized = custom_sent_tokenizer.tokenize(sample_text)
def process_content():
try:
for i in tokenized[5:]:
words = nltk.word_tokenize(i)
tagged = nltk.pos_tag(words)
chunkGram = r"""Chunk: {<.*>+}
}<VB.?|IN|DT|TO>+{"""
chunkParser = nltk.RegexpParser(chunkGram)
chunked = chunkParser.parse(tagged)
chunked.draw()
except Exception as e:
print(str(e))
process_content()
With this, you are given something like:
Now, the main difference here is:
}<VB.?|IN|DT|TO>+{
此句表示,我们移除一个或多个动词,介词,定冠词,或to
This means we're removing from the chink one or more verbs, prepositions, determiners, or the word 'to'.
Now that we've learned how to do some custom forms of chunking, and chinking, let's discuss a built-in form of chunking that comes with NLTK, and that is named entity recognition.
