python信用评分卡建模(附代码,博主录制)

医药统计项目可联系
QQ:231469242
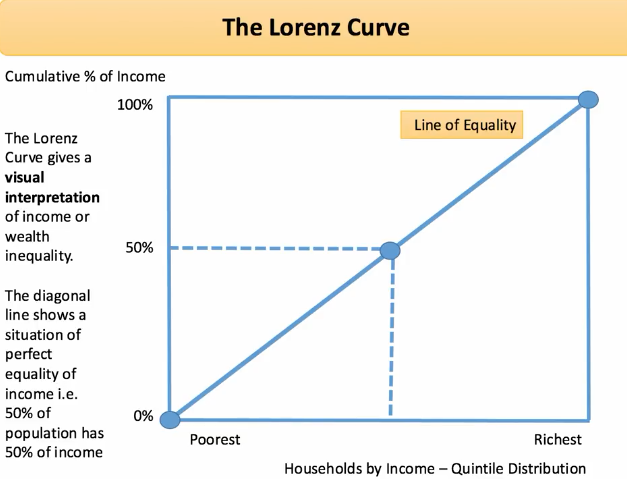
洛伦兹曲线(Lorenz curve)也叫提升图或收益曲线
提升图主要通过随机选择比较模型表现。


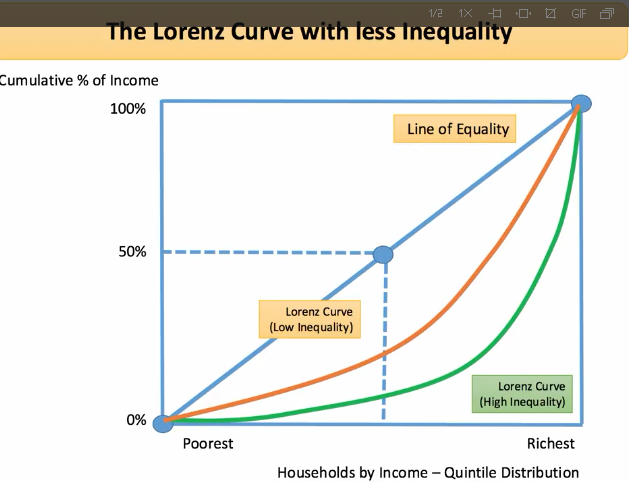
绿色曲线比黄色曲线更加不平衡
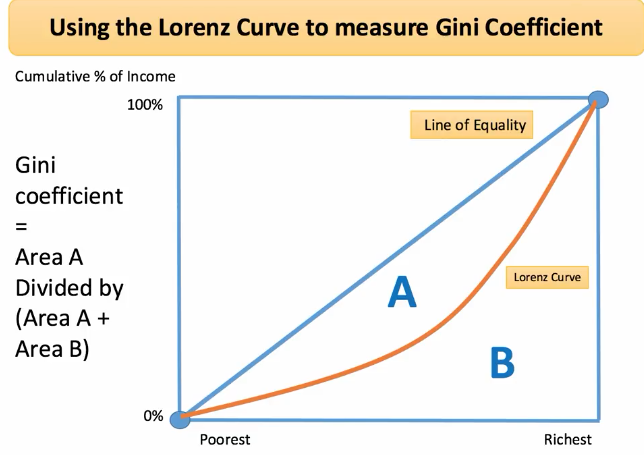
基尼系数=A/(A+B)
A+B为正方形一半恒定面积,A区间面积越大,基尼系数越大
Lift, Lift Table, and Lift Chart
提升指数、提升表和提升图
1. 什么是Lift?
I) Lift(提升指数)是评估一个预测模型是否有效的一个度量;这个比值由运用和不运用这个模型所得来的结果计算而来。
II) 一个简单的数字例子:
i. 比如说你要向选定的1000人邮寄调查问卷。以往的经验告诉你大概20%的人会把填好的问卷寄回给你,即1000人中有200人会对你的问卷作出回应(response),用统计学的术语,我们说baseline response rate是20%;
ii. 如果你现在就邮寄问卷,1000份你期望能收回200份,这可能达不到一次问卷调查所要求的回收率,比如说工作手册规定邮寄问卷回收率要在25%以上;
iii. 通过以前的问卷调查,你收集了关于问卷采访对象的相关资料,比如说年龄、教育程度之类。利用这些数据,你确定了哪类被访问者对问卷反应积极。假设你已经利用这些过去的数据建立了模型,这个模型把这1000人分了类,现在你可以从你的千人名单中挑选出反应最积极的100人来,这10%的人的反应率(response rate)为60%。那么,对这100人的群体(我们称之为Top 10%),通过运用我们的模型,相对的提升(gain or lift value)就为60%/20%=3;换句话说,与不运用模型而随机选择相比,运用模型而挑选有3倍的好处;
iv. 类似地,对占总样本的任何比例的人群,我们都可以计算出相应的提升指数,比如说我们可以计算Top 20%的群体的提升指数。
III) 一个结论就是,提升指数越大,模型的运行效果越好。
2. 建立Lift Table 的步骤(并画出Lift Chart),以验证信用评分模型为例:
I) 利用已经建立的评分模型,对我们要验证的样本进行评分。样本下的每一个个体都将得到一个分数,或者是违约概率,或者是一个分值;
II) 对样本按照上面计算好的分数进行降序排序;
III) 把已经排好序的样本依次分成10个数量相同的群体,我们就建立了一个叫decile的变量,它依次取10个值,1、2、3、4、5、6、7、8、9、10,diclie1包括违约概率值较高的10%的个体,diclie2包括下一个10%的群体,以此类推;
IV) 帐户总数是每个decile下的样本数,它是整个样本数的10%;
V) 边际坏账数是每个decile内违约的人数,就是说,利用我们的评分模型,在decile1,有25个人违约,以此类推;
VI) 累计坏账数,45表明前两个decile内共有45个人违约,以此类推;
VII) 边际坏账率是每个decile内坏账的比率。对decile1,边际坏账率由25/100得来;
VIII) 对每一个加总的decile,都计算一个累计坏账率,比如说,对前两个decile,也就是整个样本的20%,累计坏账率等于(25+20)/(100+100);
IX) 在每个decile里,提升指数(Lift)就是相应的累计坏账率与平均坏账率的偏离程度,计算公式是(累计坏账率-平均坏账率)/平均坏账率,习惯上还会乘上一个100。
X) 注:在一些处理中,提升指数直接由每个decile的累计坏账率除以平均坏账率得来,它们之间就相差1,一个是相对偏离,一个是偏离。
XI) 就我们考察的信用评分模型,它的目的就是尽可能把人群区别来开来,比如说“好”的顾客、 “坏”的顾客。提升指数越大,表明模型运作效果越好。
表1:Lift Table
(注:该表内数字纯粹为了演示,没有任何实际背景)
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149
