Shared mutable state is the root of all evil (共享的可变状态是万恶之源) -- Pete Hunt
有人说 Immutable 可以给 React 应用带来数十倍的提升,也有人说 Immutable 的引入是近期 JavaScript 中伟大的发明,因为同期 React 太火,它的光芒被掩盖了。这些至少说明 Immutable 是很有价值的,下面我们来一探究竟。
JavaScript 中的对象一般是可变的(Mutable),因为使用了引用赋值,新的对象简单的引用了原始对象,改变新的对象将影响到原始对象。如foo = {a: 1}; bar = foo; bar.a = 2你会发现此时foo.a也被改成了2。虽然这样做可以节约内存,但当应用复杂后,这就造成了非常大的隐患,Mutable 带来的优点变得得不偿失。为了解决这个问题,一般的做法是使用 shallowCopy (浅拷贝)或 deepCopy (深拷贝)来比米娜被修改,但这样做造成了CPU和内存的浪费。
Immutable 可以很好地解决这些问题。
什么是 Immutable Data
Immutable Data 就是一旦创建,就不能再被更改的数据。对 Immutable 想的任何修改或添加删除操作都会返回一个新的 Immutable 对象。Immutable 实现的原理是 Persistent Data Structure (持久化数据结构),也就是使用旧数据创建新数据时,要保证旧数据同事可用且不变。同事为了避免 deepCopy 把所有节点都复制一遍带来的性能损耗,Immutable 使用了 Structural Sharing (结构共享),即如果对象书中一个节点发生变化,只修改这个节点和受影响的父节点,其他节点则进行共享。请看下面的动画:
目前流行的 Immutable 库有两个:
- immutable.js
Facebook 工程师 Lee Byron 花费3年时间打造,与React同期出现,但没有被默认放到React工具集里(React提供了简化的Helper)。它内部实现了一套完整的Persistent Data Structure,还有很多易用的数据类型。像Collection,List, Map, Set, Record, Seq。有非常全面的map, filter, groupBy, reduce, find函数式操作方法。同时 API 也尽量与 Object 或 Array 类似。
其中有3重最重要的数据结构说明一下:(Java程序员应该最熟悉了)
- Map : 键值对集合,对应于 Object, ES6 也有专门的 Map对象
- List : 有序可重复的列表,对应于 Array
- Set : 无序且不可重复的列表
- seamless-immutable
与 Immutable.js 学院派的风格不同,seamless-immutable 并没有实现完成的 Persistent Data Structure, 而是使用Object.defineProperty(因此只有在IE9 及以上使用)扩展了 JavaScript 的 Array 和 Object 对象来实现,只支持 Array 和 Object 两种数据类型,API基于与 Array 和 Object 保持不变。代码库非常小,压缩后下载只有 2K。而 Immutable.js 压缩后下载有 16K。
下面上代码来感受一下两者的不同:
// 原来的写法 let foo = { a: { b: 1 } }; lef bar = boo; bar.a.b = 2; console.log(foo.a.b); // 打印 2 console.log(foo === bar); // 打印 true // 使用 immutable.js 后 import Immutable from 'immutable'; foo = Immutable.fromJS({ a: { b: 1 } }); bar = foo.setIn( ['a', 'b'], 2 ); // 使用 SetIn 赋值 console.log(foo.getIn(['a', 'b'])); // 使用 getIn 取值, 打印 1 console.log(foo === bar); // 打印 false // 使用 seamless-immutable.js 后 import SImmutable from 'seamless-immutable'; foo = SImmutable({ a: { b: 1 } }); boo = foo.merge({ a: { b: 2 } }); // 使用 merge 赋值 console.log(foo.a.b); // 像原生 Object 一样取值,打印 1 console.log(foo === bar); // 打印 false
Immutable 优点
- Immutable 降低了 Mutable 带来的复杂度
可变(Mutable)数据耦合了 Time 和 Value 的概念,造成了数据很难被回溯。
比如下面一段代码:
function touchAndLog(touchFn) { let data = { key: 'value' }; touchFn(data); console.log(data.key); // 这里打印的数据会根据touchFn的处理发生变化 }
在不查看 touchFn 的代码的情况下,因为不确定它对 data 做了什么,你是不可能知道会打印什么。但如果 data是 Immutable 的呢, 你可以很肯定的知道打印的是 value。
- 节省内存
Immutable.js 使用了 Structure Sharing 会尽量复用内存。没有被引用的对象会被垃圾回收。
import { Map } from 'immutable';
let a = Map({
select: 'users',
filter: Map({
name: 'Cam'
})
})
let b = a.set('select', 'people');
a === b; // false
a.get('filter') === b.get('filter'); // true
上面 a 和 b 共享了没有变化的 filter 节点。
- Undo/Redo,Copy/Paste,甚至时间旅行这些功能做起来小菜一碟
因为每次数据都是不一样的,只要把这些数据放到一个数组里存储起来,想回退到哪里就拿出对应数据即可,很容易开发出撤销重做这种功能。
后面我会提供Flux 做 Undo 的示例。
- 并发安全
传统的并发非常难做,因为要处理各种数据不一致的问题,因此·聪明人·发明了各种锁来解决。但使用了Immutable 之后,数据天生是不可变的,并发锁就不需要了。
然而现在并没有什么卵用,因为 JavaScript 还是单项城运行的。但未来可能会加入,提前解决未来的问题不是挺好的吗?
- 拥抱函数式编程
Immutable 本身就是函数式编程中的概念,纯函数式编程比面向对象更适用于前端开发。因为只要输入一致,输出必然一致,这样开发的组件更易于调试和组装。
像 ClojureScript , Elm 等函数式编程语言中的数据类型天生都是Immutable 的,这是因为什么ClojureScript 基于 React 的框架 -- Om 性能比 React 还要好的原因。
使用 Immutable 的缺点
- 需要学习心得 API
No Comments
- 增加了资源文件大小
No Comments
- 容易对原生对象混淆
这点事我们使用 Immutable.js 过程中遇到最大的问题。写代码要做思维上的转变。
虽然 Immutable.js 尽量尝试把 API 设计的原生对象类似,有时候还是很难区别到底是 Immutable 对象还是原生对象,容易混淆操作。
Immutable 中的 Map 和 List 虽然对应原生 Object 和 Array,但操作非常不同,比如你要用 map.get('key') 而不是map.key, arr.get(0)而不是 array[0]。另外 Immutable 每次修改都会返回新对象,也很容易忘记赋值。
当使用外部库的时候,一般需要使用原生对象,也很容易忘记转换。
下面给出一些办法来避免类似问题发生:
- 使用 Flow 或 TypeScript 这类有静态类型检查的工具
- 约定变量命名规则:如所有 Immutable 类型对象以 开头。
- 使用
Immutable.fromJS而不是Immutable.Map或Immutable.List来创建对象,这样可以避免 Immutable 和原生对象间混用。
更多认识
- Immutable.js
两个 immutable 对象可以使用 === 来比较,这样是直接比较内存地址,性能最好。但即使两个对象的值是一样的,也会返回 false:
let map1 = Immutable.Map({ a: 1, b: 1, c: 1 });
let map2 = Immutable.Map({ a: 1, b: 1, c: 1 });
map1 === map2; // false
为了直接比较对象的值,immutable.js 提供了 Immutable.is 来做 “值比较”, 结果如下:
Immutable.is(map1, map2); // true
Immutable.is 比较的是两个对象的 hashCode 或 valueOf (对于JavaScript对象)。由于 immutable 内部使用了 Trie 数据结构来存储,只要两个对象 hashCode 相等,值就是一样的。这样的算法避免了深度遍历比较,性能非常好。
后面会使用 Immutable.is 来减少 React 重复渲染,提高性能。
另外,还有 mori、cortex 等,因为类似就不再介绍。
- 与 Object.freeze、const 区别
Object.freeze 和 ES6 中新加入的 const 都可以达到防止对象被篡改的功能,但它们是shallowCopy 的。对象层级一深就要特殊处理了。
- Cursor 的概念
这个 Cursor 和数据库中的游标是完全不同的概念。
由于 Immutable 数据一般嵌套非常深,为了便于访问深层数据,Cursor 提供了可以直接访问这个深层数据的引用。
import Immutable from 'immutable'; import Cursor from 'immutable/contrib/cursor'; let data = Immutable.froomJS({ a: { b: { c: 1 } } }); // 让 cursor 指向 { c: 1} let cursor = Cursor.from(data, ['a', 'b'], newData => { // 当 cursor 或其子 cursor 执行 update 时调用 console.log(newData); }); cursor.get('c'); // 1 cursor = cursor.update('c', x => x + 1); cursor.get('c'); // 2
实践
- 与 React 搭配使用,Pure Render
熟悉 React 的都知道,React 做性能优化时有一个避免重复渲染的大招,就是使用 shouldComponentUpdate() ,但它默认返回 true,即始终会执行 render()方法,然后做 Virtual DOM 比较,并得出是否需要做真实 DOM 更新,这里往往会带来很多无必要的渲染并成为性能瓶颈。
当然我们也可以在 shouldComponentUpdate() 中使用 deepCopy 和 deepCompare 来避免吴彪要的 render(), 但 deepCopy 和 deepCompare 一般都是非常耗性能的。
Immutable 则提供了简洁高效的判断数据是否变化的方法, 只需 === 和 is 比较就能知道是否需要执行render(), 而这个操作几乎 0 成本,所以可以极大提高性能。修改后的 shouldComponentUpdate 是这样的:
immport { is } from 'immutable';
shouldComponentUpdate (nextProps = {}, nextState = {}) {
const thisProps = this.props || {}, thisState = this.state || {};
if (Object.keys(thisProps).length !== Object.keys(nextProps).length ||
Object.keys(thisProps).length !== Object.keys(nextProps).length
){
return true;
}
for (const key in nextProps) {
if (thisProps[key] !== nextProps[key] || !is(thisProps[key], nextProps[key])) {
return true;
}
}
for (const key in nextProps) {
if (thisState[key] !== nextState[key] || !is(thisState[key], nextState[key])) {
return true;
}
}
return false;
}
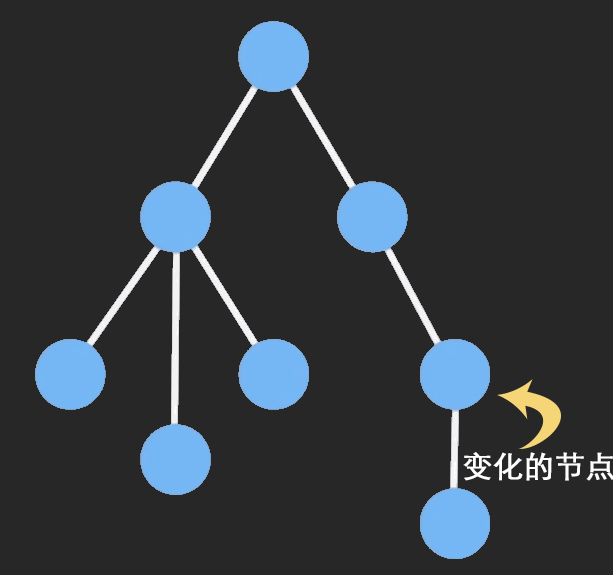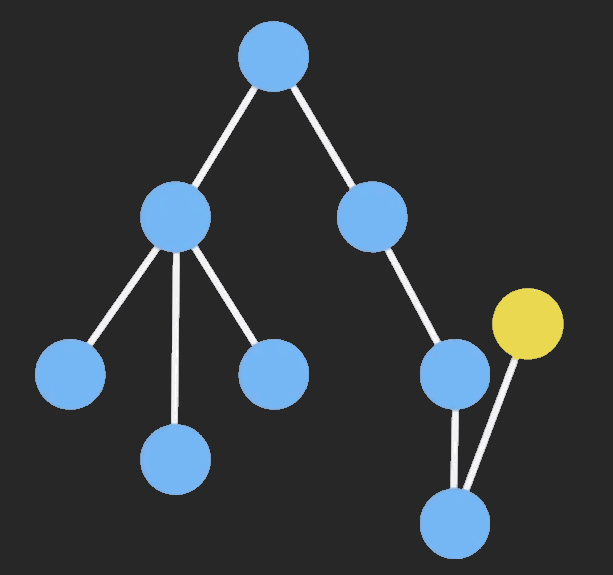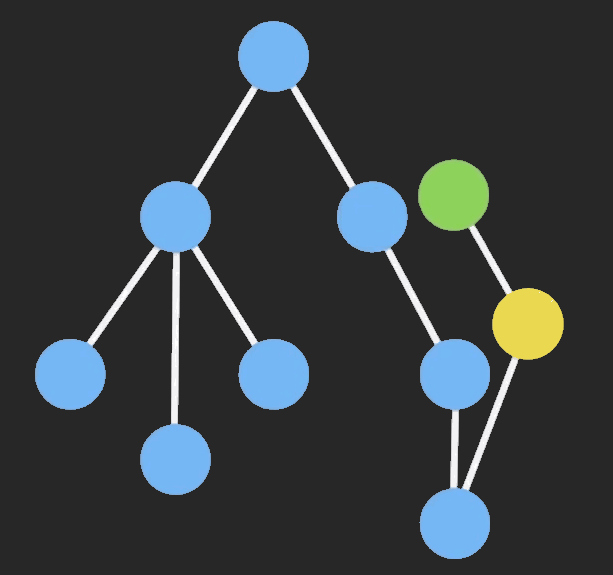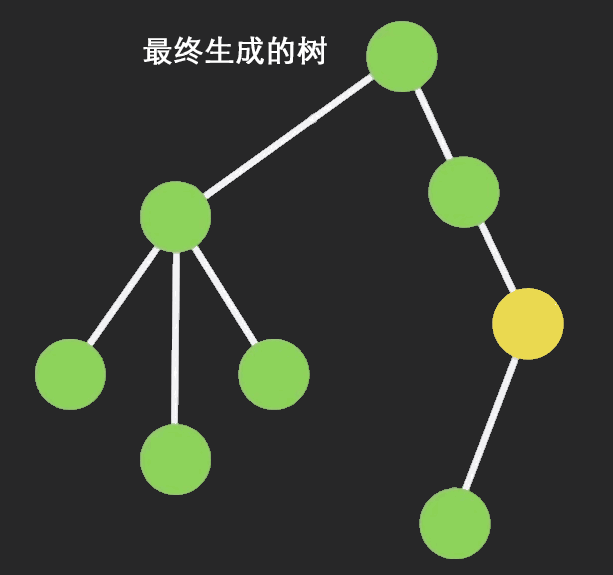
使用 Immutable 后, 如下图,当红色节点的 state 变化后,不会再渲染树种的所有节点,而是只渲图中绿色的部分:
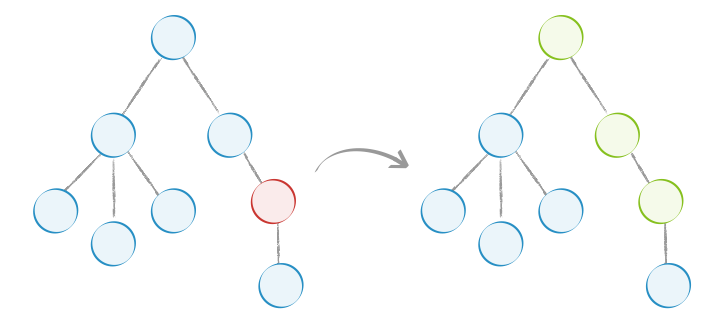
你也可以借助 React.addons.PureRenderMixin 或支持 class 语法的 pure-render-decorator 来实现。
setState 的一个技巧
React 建议把 this.state 当作 Immutable 的,因此修改前需要做一个 deepCopy,显得麻烦:
import '_' from 'lodash'; const Component = React.createClass({ getInitialState() { return { data: { times: 0 } } }, handleAdd() { let data = _.cloneDeep(this.state.data); data.times = data.times + 1; this.setState({ data: data }); // 如果上面不做 cloneDeep, 下面打印的结果会是已经加 1 后的值。 console.log(this.state.data.times); } })
使用 Immutable 后:
getInitialState() { return { data: Map({ times: 0 }) } }, handleAdd() { this.setState({ data: this.state.data.update('times', v => v + 1) }); // 这时的 times 并不会改变 console.log(this.state.data.get('times')); }
上面的 handleAdd 可以简写成:
handleAdd() { this.setState(({data}) => ({ data: data.updata('times', v => v + 1) })) }
- 与 Flux 搭配使用
由于 Flux 并没有限定 Store 中数据的类型,使用 Immutable 非常简单。
现在是实现一个类似带有添加和撤销功能的Store:
import { Map, OrderedMap } from 'immutable';
let todos = OrderedMap();
let history = []; // 普通数组,存放每次操作后产生的数据
let TodoStore = createStore({
getAll() {
return todos;
}
});
Dispatcher.register(action => {
if (action.actionType === 'create') {
let id = createGUID();
history.push(todos); // 记录当前操作前的数据,便于撤销
todos = todos.set(id, Map({
id: id,
complete: false,
text: action.text.trim() // 注: trim() 方法是去掉字符串前后空格的方法
}));
TodoStore.emitChange();
} else if (action.actionType === 'undo') {
// 这里是撤销功能实现,
// 只需要从 history 数组中取一次 todos 即可
if (history.length > 0) {
todos = history.pop();
}
TodoStore.emitChange();
}
})
- 与 Redux 搭配使用
Redux 是目前流行的 Flux 衍生库。它简化了 Flux 中多个 Store 的概念,只有一个 Store, 数据操作通过 Reducer 中实现;同时它提供了更简洁和清晰的单项数据流(View -> Action -> Middleware -> Reducer),也更易于开发同构应用。目前已经在我们项目中大规模使用。
由于 Redux 中内置的 combineReducers 和 reducer 中的 initialState 都为原生的 Object 对象,所以不能和 Immutable 原生搭配使用。
幸运的是,Redux 并不排斥使用 Immutable,可以自己重写 combineReducers 或使用 redux-immutablejs 来提供支持。
上面我们提到 Cursor 可以方便检索和 update 层级比较深的数据,但因为 Redux 中已经有了 select 来做检索,Action 来更新数据,因此 Cursor 在这里就没有用武之地了。
总结
Immutable 可以给应用带来极大的性能提升,但是否使用还是要看项目情况。由于侵入性较强,新项目引入比较容易,老项目迁移需要评估迁移。对于一些提供给外部使用的公共组件,最好不要把 Immutable 对象直接暴露在对外接口中。
如果 JS 原生 Immutable 类型会不会太美,被称为 React API 终结者的 Sebastion Markbage 有一个这样的提案,能否通过现在还不确定。不过可以肯定的是 Immutable 会被越来越多的项目使用。
(完)
参考来源:https://zhuanlan.zhihu.com/p/20295971
