1、定长和变长相分离 在定长表上与变长表建立关系 这样子定长表查询速度快
2、适当添加冗余字段 比如栏目表的多于字段文章个数用于记录中的每个栏目下的文章个数 在此之前可能需要链表查询得到文章个数这样相当耗资源 内存换时间
3、类型优先级:int datatime char varchar text tyint(1) 占用一个直接 char(1) 占用3个直接 int占用4个字节 tynint unsigned占用一个字节
4、尽量不用 NULL
5、索引类型:哈希索引 b-tree索引 都属于高效的数据结构
B-tree查找数据 比如在1 到10 的数据当中查找4 首先先构建一个b-tree 左小右大 比根节点小找左边 查找42亿数据普通插座需要平均21
亿次 使用b-tree查找为32次 该节点指向存储信息的内存位置
哈希索引 精准查询速度快 查询范围性数据id>5较慢 ,因为该哈希索引的每条数据的存储地址是根据id和一定的算法计算得出 因此会产生很多缺口地址不连续 前缀查询和排序均无法优化 只适合查找具体的位置
联合索引是最常用的 将多个列当成一个索引 索引的左前缀原则 %hello 。。
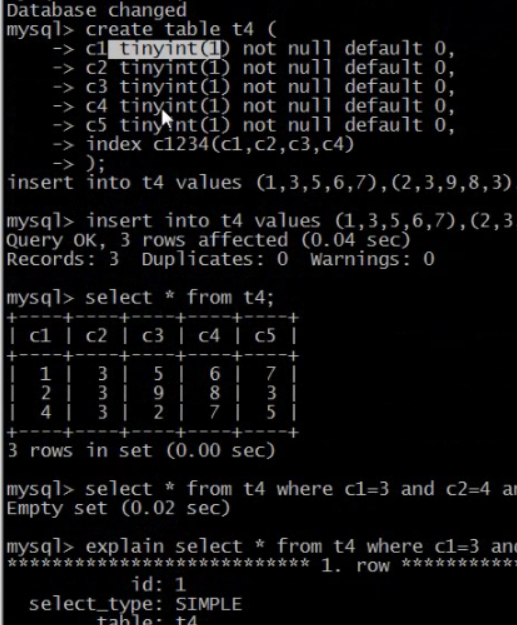
比如电商网站当中想进入栏目、电脑、品牌、价格 可以建立一个栏目 电脑 品牌 价格 符合索引如果直接使用价格索引速度还是很慢
假设某张表上建立 index(a,b,c,d)
select * from test where a = x1 and b = x2 and c = x3 and order by d 里边有使用到的索引 a,b,c ,d 不过d用在排序上面