这里来学习一下从一个源字符串中搜索指定的字符串,有些啰嗦,直接看最终的效果: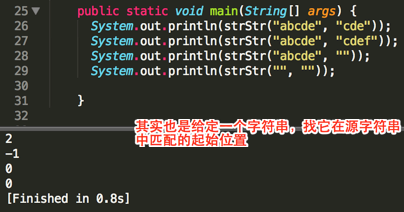
实际上JAVA SDK中相当于String.indexOf()方法,上面的用例改用JAVA SDK来实现看一下:

编译运行:
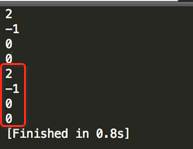
结果一模一样~
而首先先用JAVA语言去实现这个算法,如何实现呢,下面先来捋一下思路:
如果想从上图中搜"cde"这个字符串的位置如何搞呢?假设source代表源字符串、target代表待搜索的字符串:
1、搜寻的总次数max=source.length() - target.length();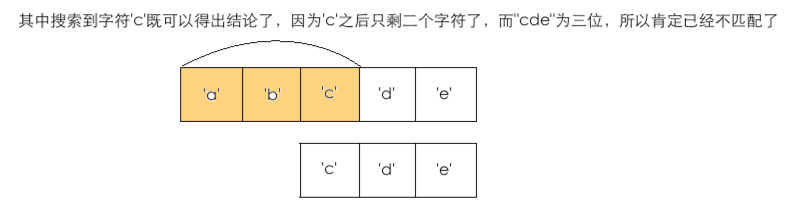
2、每次搜寻时,拿target中的字符跟source的起始位置进行匹对,如果一个都不相等,则此次循环结果,往下继续循环;如果第一个相等了,则再拿target的第二个元素进行对比,以此循环,只要有一个没匹对上,则当前循环结束;其当target的所有元素都匹配完了则将当前循环的位置返回出来。
下面直接上代码:
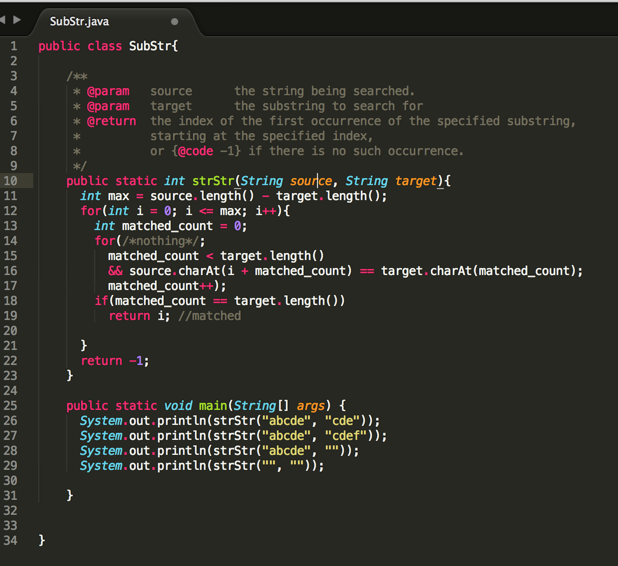
下面来分析一下流程,以 这个用例来进行分析:
这个用例来进行分析:
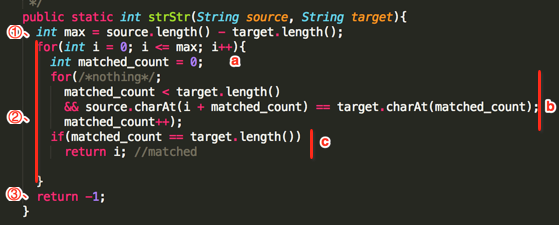
其中参数:source="abcde"、target="cde"
①、int max = 5 - 3 = 2;也就是总搜寻的次数,"c"以后由于已经小于target的长度了,所以再循环就没意义了。
②、开始对源字符串进行循环一一进行对比:
i=0,i <= 2,开始Loop1:
a、int matched_count = 0;用来进行对匹配的数量进行累加。
b、接着用target一个个字符跟source进行对比,实际就是一个循环:
1、for(; 0 < 3 && source.charAt(0) == target.charAt(0);0++) = for(; 0 < 3 && 'a' == 'c';0++),很显然循环条件不满足,所以直接退出该循环。
c、由于matched_count【0】 == target.length()【3】条件不满足,所以继续循环。
i++ = 1;
i=1,i <= 2,开始Loop2:
a、int matched_count = 0;用来进行对匹配的数量进行累加。
b、接着用target一个个字符跟source进行对比,实际就是一个循环:
1、for(; 0 < 3 && source.charAt(1) == target.charAt(0);0++) = for(; 0 < 3 && 'b' == 'c';0++),很显然循环条件不满足,所以直接退出该循环。
c、由于matched_count【0】 == target.length()【3】条件不满足,所以继续循环。
i++ = 2;
i=2,i <= 2,开始Loop3:
a、int matched_count = 0;用来进行对匹配的数量进行累加。
b、接着用target一个个字符跟source进行对比,实际就是一个循环:
1、for(; 0 < 3 && source.charAt(2) == target.charAt(0);0++) = for(; 0 < 3 && 'c' == 'c';0++),条件满足,则matched_count++=1,继续对target下一个元素进行匹配;
2、for(; 1 < 3 && source.charAt(3) == target.charAt(1);1++) = for(; 0 < 3 && 'd' == 'd';1++),条件满足,则matched_count++=2,继续对target下一个元素进行匹配;
3、for(; 2 < 3 && source.charAt(4) == target.charAt(2);2++) = for(; 2 < 3 && 'e' == 'e';2++),条件满足,则matched_count++=3,继续对target下一个元素进行匹配;
4、for(; 3 < 3 && source.charAt(5) == target.charAt(3);3++)明显条件不满足,所以匹配过程结束。
c、由于matched_count【3】 == target.length()【3】条件满足,则证明刚好能匹配上,将当前位置i=2返回。
③、如果没有搜寻到则返回-1。
下面来看一下这种算法的时间复杂度:
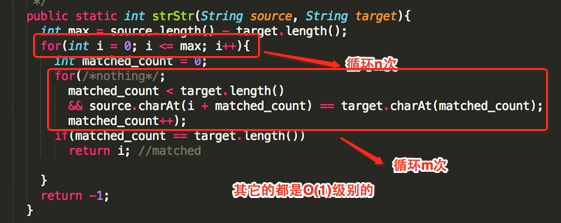
所以比较明显O(m * n)是它的时间复杂度,也就是随着source和target字串的长度的变化用的时间也会相应进行便化。