一、目标
爬取 https://vc.bilibili.com/p/eden/rank#/?tab=全部 小视频排行榜视频
二、准备
安装第三方库 requests、fake_useragent
创建bili文件夹
三、解释
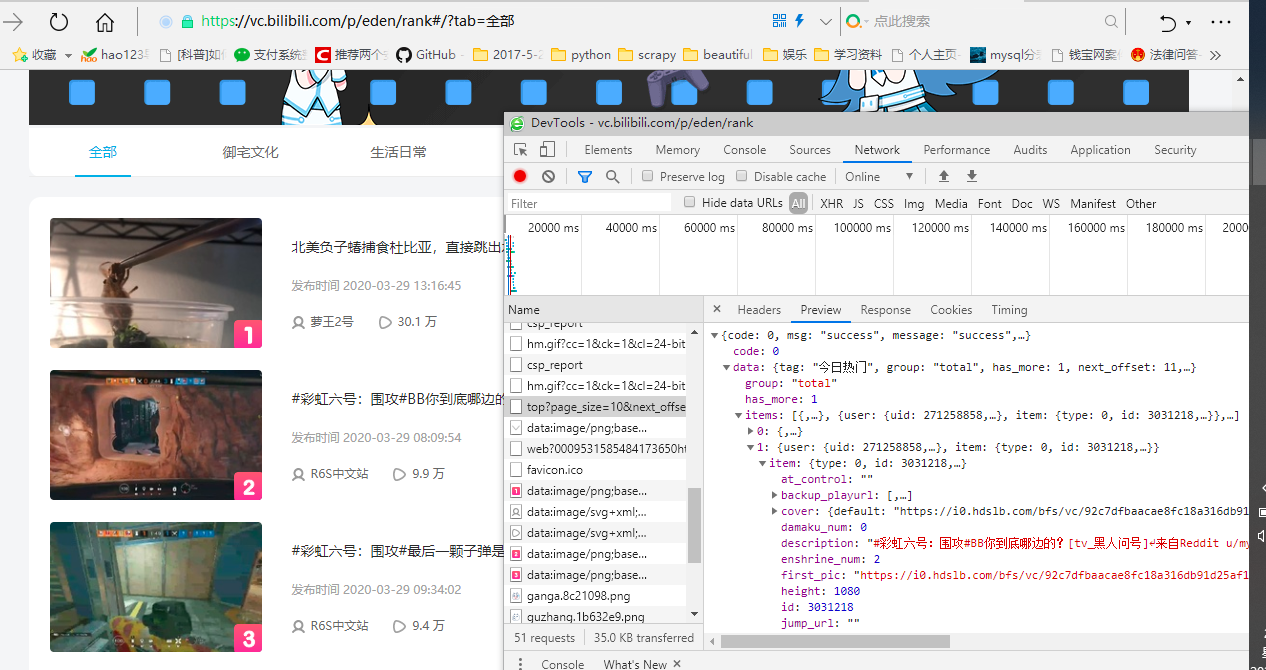
排行榜视频直接把所有排行榜视频存储在服务器,直接把视频排行的服务器视频地址暴露在preview中 直接在试图中找到此链接的json串 遍历出来即可
1 用户 - > url 2 用户 - > server 也属于数据挖掘的一种方式
四、代码
import requests
# 可自动生成浏览器UserAgent请求头
from fake_useragent import UserAgent
headers = {
# 浏览器类型 (有的网址服务器检测浏览器 反扒其中的一种) 可随机生成浏览器类型
'User-Agent': UserAgent().random
}
# 获取服务器视频url地址
def top_video():
url = 'https://api.vc.bilibili.com/board/v1/ranking/top?page_size=10&next_offset=&tag=%E4%BB%8A%E6%97%A5%E7%83%AD%E9%97%A8&platform=pc'
response = requests.get(url).json()
data = response['data']['items']
for i in data:
ite = i['item']
video_url = ite['video_playurl']
dowloads_video(video_url)
count = 1
# 下载本地
def dowloads_video(video_url):
global count
response = requests.get(video_url, stream=True, headers = headers)
# 每次下载视频数据大小
chunk_size = 1024
with open('bili/{}.mp4'.format(count), 'ab') as f:
for data in response.iter_content(chunk_size=chunk_size):
f.write(data)
count += 1
top_video()