1、值数据类型
在进程的虚拟内存中,有一个区域称为堆栈。堆栈存储不是对象成员的值数据类型。另外,在调用一个方法时,也使用堆栈存储传递给方法的所有参数的复本。为了理解堆栈的工作原理,需要注意在C#中变量的作用域。如果变量a在变量b之前进入作用域,b就会先出作用域。下面的代码:
{ int a; // do something { int b; // do something else } }
首先声明a。在内部的代码块中声明了b。然后内部的代码块终止,b就出作用域,最后a出作用域。所以b的生存期会完全包含在a的生存期中。在释放变量时,其顺序总是与给它们分配内存的顺序相反,这就是堆栈的工作方式。
我们不知道堆栈在地址空间的什么地方,这些信息在进行C#开发是不需要知道的。堆栈指针(操作系统维护的一个变量) 表示堆栈中下一个自由空间的地址。程序第一次运行时,堆栈指针指向为堆栈保留的内存块末尾。堆栈实际上是向下填充的,即从高内存地址向低内存地址填充。当数据入栈后,堆栈指针就会随之调整,以始终指向下一个自由空间。这种情况如图下所示。在该图中,显示了堆栈指针800000(十六进制的0xC3500),下一个自由空间是地址799999。
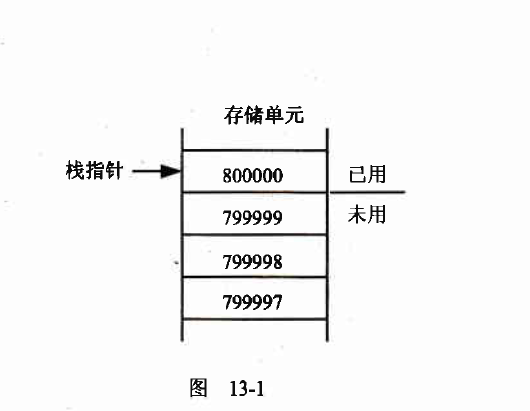
下面的代码会告诉编译器,需要一些存储单元以存储一个整数和一个双精度浮点数,这些存储单元会分别分配给nRacingCars和engineSize,声明每个变量的代码表示开始请求访问这个变量,闭合花括号表示这两个变量出作用域的地方。
{
int nRacingCars = 10;
double engineSize = 3000.0;
// do calculations;
}
假定使用如上图所示的堆栈。变量nRacingCars进入作用域,赋值为10,这个值放在存储单元799996~799999上,这4个字节就在堆栈指针所指空间的下面。有4个字节是因为存储int要使用4个字节。为了容纳该int,应从堆栈指针中减去4,所以它现在指向位置799996,即下一个自由空间 (799995)。
下一行代码声明变量engineSize(这是一个double),把它初始化为3000.0。double要占用8个字节,所以值3000.0占据栈上的存储单元799988~799995上,堆栈指针减去8,再次指向堆栈上的下一个自由空间。
当engineSize出作用域时,计算机就知道不再需要这个变量了。因为变量的生存期总是嵌套的,当engineSize在作用域中时,无论发生什么情况,都可以保证堆栈指针总是会指向存储engineSize的空间。为了从内存中删除这个变量,应给堆栈指针递增8,现在指向engineSize使用过的空间。此处就是放置闭合花括号的地方。当nRacingCars也出作用域时,堆栈指针就再次递增4,此时如果内存中又放入另一个变量,从799999开始的存储单元就会被覆盖,这些空间以前是存储nRacingCars的。
如果编译器遇到像int i、j这样的代码,则这两个变量进入作用域的顺序就是不确定的:两个变量是同时声明的,也是同时出作用域的。此时,变量以什么顺序从内存中删除就不重要了。编译器在内部会确保先放在内存中的那个变量后删除,这样就能保证该规则不会与变量的生存期冲突。
2 引用数据类型
堆栈有非常高的性能,但对于所有的变量来说还是不太灵活。变量的生存期必须嵌套,在许多情况下,这种要求都过于苛刻。通常我们希望使用一个方法分配内存,来存储一些数据,并在方法退出后的很长一段时间内数据仍是可以使用的。只要是用new运算符来请求存储空间,就存在这种可能性——例如所有的引用类型。此时就要使用托管堆。
如果以前编写过需要管理低级内存的C++代码,就会很熟悉堆(heap)。托管堆和C++使用的堆不同,它在垃圾收集器的控制下工作,与传统的堆相比有很显著的性能优势。
托管堆(简称为堆)是进程的可用4GB中的另一个内存区域。要了解堆的工作原理和如何为引用数据类型分配内存,看看下面的代码:
void DoWork() { Customer arabel; arabel = new Customer(); Customer otherCustomer2 = new EnhancedCustomer(); }
这段代码中,假定存在两个类Customer 和 EnhancedCustomer。EnhancedCustomer类扩展了Customer类。
首先,声明一个Customer引用arabel,在堆栈上给这个引用分配存储空间,但这仅是一个引用,而不是实际的Customer对象。arabel引用占用4个字节的空间,包含了存储Customer对象的地址(需要4个字节把内存地址表示为0到4GB之间的一个整数值)。
然后看下一行代码:
arabel = new Customer();
这行代码完成了以下操作:首先,分配堆上的内存,以存储Customer实例(一个真正的实例,不只是一个地址)。然后把变量arabel的值设置为分配给新Customer对象的内存地址(它还调用合适的Customer()构造函数初始化类实例中的字段,但我们不必担心这部分)。
Customer实例没有放在堆栈中,而是放在内存的堆中。在这个例子中,现在还不知道一个Customer对象占用多少字节,但为了讨论方便,假定是32字节。这32字节包含了Customer实例字段,和.NET用于识别和管理其类实例的一些信息。
为了在堆上找到一个存储新Customer对象的存储位置,.NET运行库在堆中搜索,选取第一个未使用的、32字节的连续块。为了讨论方便,假定其地址是200000,arabel引用占用堆栈中的799996~799999位置。这表示在实例化arabel对象前,内存的内容应如下图所示。

给Customer对象分配空间后,内存内容应如下图所示。注意,与堆栈不同,堆上的内存是向上分配的,所以自由空间在已用空间的上面。
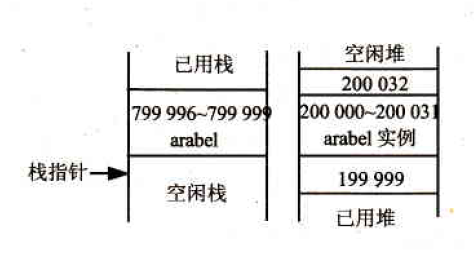
下一行代码声明了一个Customer引用,并实例化一个Customer对象。在这个例子中,需要在堆栈上为mrJones引用分配空间,同时,也需要在堆上为它分配空间:
Customer otherCustomer2 = new EnhancedCustomer();
该行把堆栈上的4字节分配给otherCustomer2引用,它存储在799992~799995位置上,而otherCustomer2对象在堆上从200032开始向上分配空间。
从这个例子可以看出,建立引用变量的过程要比建立值变量的过程更复杂,且不能避免性能的降低。实际上,我们对这个过程进行了过分的简化,因为.NET运行库需要保存堆的状态信息,在堆中添加新数据时,这些信息也需要更新。尽管有这些性能损失,但仍有一种机制,在给变量分配内存时,不会受到堆栈的限制。把一个引用变量的值赋予另一个相同类型的变量,就有两个引用内存中同一对象的变量了。当一个引用变量出作用域时,它会从堆栈中删除,如上一节所述,但引用对象的数据仍保留在堆中,一直到程序停止,或垃圾收集器删除它为止,而只有在该数据不再被任何变量引用时,才会被删除。
这就是引用数据类型的强大之处,在C#代码中广泛使用了这个特性。这说明,我们可以对数据的生存期进行非常强大的控制,因为只要有对数据的引用,该数据就肯定存在于堆上。
3 垃圾收集
由上面的讨论和图可以看出,托管堆的工作方式非常类似于堆栈,在某种程度上,对象会在内存中一个挨一个地放置,这样就很容易使用指向下一个空闲存储单元的堆指针,来确定下一个对象的位置。在堆上添加更多的对象时,也容易调整。但这比较复杂,因为基于堆的对象的生存期与引用它们的基于堆栈的变量的作用域不匹配。
在垃圾收集器运行时,会在堆中删除不再引用的所有对象。在完成删除动作后,堆会立即把对象分散开来,与已经释放的内存混合在一起,如下图所示。
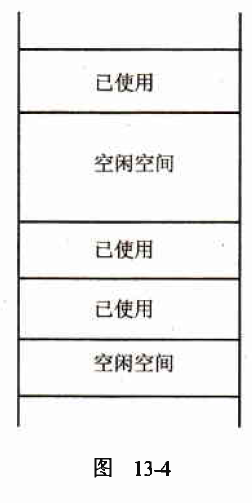
如果托管的堆也是这样,在其上给新对象分配内存就成为一个很难处理的过程,运行库必须搜索整个堆,才能找到足够大的内存块来存储每个新对象。但是,垃圾收集器不会让堆处于这种状态。只要它释放了能释放的所有对象,就会压缩其他对象,把它们都移动回堆的端部,再次形成一个连续的块。因此,堆可以继续像堆栈那样确定在什么地方存储新对象。当然,在移动对象时,这些对象的所有引用都需要用正确的新地址来更新,但垃圾收集器也会处理更新问题。
垃圾收集器的这个压缩操作是托管的堆与旧未托管的堆的区别所在。使用托管的堆,就只需要读取堆指针的值即可,而不是搜索链接地址列表,来查找一个地方来放置新数据。因此,在.NET下实例化对象要快得多。有趣的是,访问它们也比较快,因为对象会压缩到堆上相同的内存区域,这样需要交换的页面较少。Microsoft相信,尽管垃圾收集器需要做一些工作,压缩堆,修改它移动的所有对象引用,致使性能降低,但这些性能会得到弥补。
注意:
一般情况下,垃圾收集器在.NET运行库认为需要时运行。可以通过调用System. GC.Collect(),强迫垃圾收集器在代码的某个地方运行,System.GC是一个表示垃圾收集器的.NET基类, Collect()方法则调用垃圾收集器。但是,这种方式适用的场合很少,例如,代码中有大量的对象刚刚停止引用,就适合调用垃圾收集器。但是,垃圾收集器的逻辑不能保证在一次垃圾收集过程中,所有未引用的对象都从堆中删除。
4、释放未托管的资源
垃圾收集器的出现意味着,通常不需要担心不再需要的对象,只要让这些对象的所有引用都超出作用域,并允许垃圾收集器在需要时释放资源即可。但是,垃圾收集器不知道如何释放未托管的资源(例如文件句柄、网络连接和数据库连接)。托管类在封装对未托管资源的直接或间接引用时,需要制定专门的规则,确保未托管的资源在回收类的一个实例时释放。
在定义一个类时,可以使用两种机制来自动释放未托管的资源。这些机制常常放在一起实现,因为每个机制都为问题提供了略为不同的解决方法。这两个机制是:
- ● 声明一个析构函数(或终结器),作为类的一个成员
- ● 在类中执行System.IDisposable接口
下面依次讨论这两个机制,然后介绍如何同时实现它们,以获得最佳的效果。
11.2.1 析构函数
前面介绍了构造函数可以指定必须在创建类的实例时进行的某些操作,在垃圾收集器删除对象之前,也可以调用析构函数。由于执行这个操作,所以析构函数初看起来似乎是放置释放未托管资源、执行一般清理操作的代码的最佳地方。但是,事情并不是如此简单。
注意:
在讨论C#中的析构函数时,在底层的.NET结构中,这些函数称为终结器(finalizer)。在C#中定义析构函数时,编译器发送给程序集的实际上是Finalize()方法。这不会影响源代码,但如果需要查看程序集的内容,就应知道这个事实。
C++开发人员应很熟悉析构函数的语法,它看起来类似于一个方法,与包含类同名,但前面加上了一个发音符号(~)。它没有返回类型,不带参数,没有访问修饰符。下面是一个例子:
class MyClass { ~MyClass() { // destructor implementation } }
C#编译器在编译析构函数时,会隐式地把析构函数的代码编译为Finalize()方法的对应代码,确保执行父类的Finalize()方法。下面列出了编译器为~MyClass()析构函数生成的IL的对应C#代码:
protected override void Finalize() { try { // destructor implementation } finally { base. Finalize(); } }
如上所示,在~MyClass()析构函数中执行的代码封装在Finalize()方法的一个try块中。对父类Finalize()方法的调用放在finally块中,确保该调用的执行。第13章会讨论try块和finally块。
有经验的C++开发人员大量使用了析构函数,有时不仅用于清理资源,还提供调试信息或执行其他任务。C#析构函数的使用要比在C++中少得多,与C++析构函数相比,C#析构函数的问题是它们的不确定性。在删除C++对象时,其析构函数会立即运行。但由于垃圾收集器的工作方式,无法确定C#对象的析构函数何时执行。所以,不能在析构函数中放置需要在某一时刻运行的代码,也不应使用能以任意顺序对不同类实例调用的析构函数。如果对象占用了宝贵而重要的资源,应尽快释放这些资源,此时就不能等待垃圾收集器来释放了。
另一个问题是C#析构函数的执行会延迟对象最终从内存中删除的时间。没有析构函数的对象会在垃圾收集器的一次处理中从内存中删除,但有析构函数的对象需要两次处理才能删除:第一次调用析构函数时,没有删除对象,第二次调用才真正删除对象。另外,运行库使用一个线程来执行所有对象的Finalize()方法。如果频繁使用析构函数,而且使用它们执行长时间的清理任务,对性能的影响就会非常显著。
11.2.2 IDisposable接口
在C#中,推荐使用System.IDisposable接口替代析构函数。IDisposable接口定义了一个模式(具有语言级的支持),为释放未托管的资源提供了确定的机制,并避免产生析构函数固有的与垃圾函数器相关的问题。IDisposable接口声明了一个方法Dispose(),它不带参数,返回void,Myclass的方法Dispose()的执行代码如下:
class Myclass : IDisposable { public void Dispose() { // implementation } }
Dispose()的执行代码显式释放由对象直接使用的所有未托管资源,并在所有实现IDisposable接口的封装对象上调用Dispose()。这样,Dispose()方法在释放未托管资源的时间方面提供了精确的控制。
假定有一个类ResourceGobbler,它使用某些外部资源,且执行IDisposable接口。如果要实例化这个类的实例,使用它,然后释放它,就可以使用下面的代码:
ResourceGobbler theInstance = new ResourceGobbler(); // do your processing theInstance.Dispose();
如果在处理过程中出现异常,这段代码就没有释放theInstance使用的资源,所以应使用try块(详见第13章),编写下面的代码:
ResourceGobbler theInstance = null; try { theInstance = new ResourceGobbler(); // do your processing } finally { if (theInstance != null) { theInstance.Dispose(); } }
即使在处理过程中出现了异常,这个版本也可以确保总是在theInstance上调用Dispose(),总是释放由theInstance使用的资源。但是,如果总是要重复这样的结构,代码就很容易被混淆。C#提供了一种语法,可以确保在执行IDisposable接口的对象的引用超出作用域时,在该对象上自动调用Dispose()。该语法使用了using关键字来完成这一工作—— 但目前,在完全不同的环境下,它与命名空间没有关系。下面的代码生成与try块相对应的IL代码:
using (ResourceGobbler theInstance = new ResourceGobbler()) { // do your processing }
using语句的后面是一对圆括号,其中是引用变量的声明和实例化,该语句使变量放在随附的语句块中。另外,在变量超出作用域时,即使出现异常,也会自动调用其Dispose()方法。如果已经使用try块来捕获其他异常,就会比较清晰,如果避免使用using语句,仅在已有的try块的finally子句中调用Dispose(),还可以避免进行额外的缩进。
注意:
对于某些类来说,使用Close()方法要比Dispose()更富有逻辑性,例如,在处理文件或数据库连接时就是这样。在这些情况下,常常实现IDisposable接口,再执行一个独立的Close()方法,来调用Dispose()。这种方法在类的使用上比较清晰,还支持C#提供的using语句。
11.2.3 实现IDisposable接口和析构函数
前面的章节讨论了类所使用的释放未托管资源的两种方式:
- ● 利用运行库强制执行的析构函数,但析构函数的执行是不确定的,而且,由于垃圾收集器的工作方式,它会给运行库增加不可接受的系统开销。
- ● IDisposable接口提供了一种机制,允许类的用户控制释放资源的时间,但需要确保执行Dispose()。
一般情况下,最好的方法是执行这两种机制,获得这两种机制的优点,克服其缺点。假定大多数程序员都能正确调用Dispose(),同时把执行析构函数作为一种安全的机制,以防没有调用Dispose()。下面是一个双重实现的例子:
public class ResourceHolder : IDisposable { private bool isDispose = false; public void Dispose() { Dispose(true); GC.SuppressFinalize(this); } protected virtual void Dispose(bool disposing) { if (!isDisposed) { if (disposing) { // Cleanup managed objects by calling their // Dispose() methods. } // Cleanup unmanaged objects } isDisposed=true; } ~ResourceHolder() { Dispose (false); } public void SomeMethod() { // Ensure object not already disposed before execution of any method if(isDisposed) { throw new ObjectDisposedException("ResourceHolder"); } // method implementation… } }
可以看出,Dispose()有第二个protected重载方法,它带一个bool参数,这是真正完成清理工作的方法。Dispose(bool)由析构函数和IDisposable.Dispose()调用。这个方式的重点是确保所有的清理代码都放在一个地方。
传递给Dispose(bool)的参数表示Dispose(bool)是由析构函数调用,还是由IDisposable. Dispose()调用—— Dispose(bool)不应从代码的其他地方调用,其原因是:
- ● 如果客户调用IDisposable.Dispose(),该客户就指定应清理所有与该对象相关的资源,包括托管和非托管的资源。
- ● 如果调用了析构函数,原则上所有的资源仍需要清理。但是在这种情况下,析构函数必须由垃圾收集器调用,而且不应访问其他托管的对象,因为我们不再能确定它们的状态了。在这种情况下,最好清理已知的未托管资源,希望引用的托管对象还有析构函数,执行自己的清理过程。
isDisposed成员变量表示对象是否已被删除,并允许确保不多次删除成员变量。它还允许在执行实例方法之前测试对象是否已释放,如SomeMethod()所示。这个简单的方法不是线程安全的,需要调用者确保在同一时刻只有一个线程调用方法。要求客户进行同步是一个合理的假定,在整个.NET类库中反复使用了这个假定(例如在集合类中)。第18章将讨论线程和同步。
最后,IDisposable.Dispose()包含一个对System.GC.SuppressFinalize()方法的调用。GC 表示垃圾收集器,SuppressFinalize()方法则告诉垃圾收集器有一个类不再需要调用其析构函数了。因为Dispose()已经完成了所有需要的清理工作,所以析构函数不需要做任何工作。调用SuppressFinalize()就意味着垃圾收集器认为这个对象根本没有析构函数。