目标
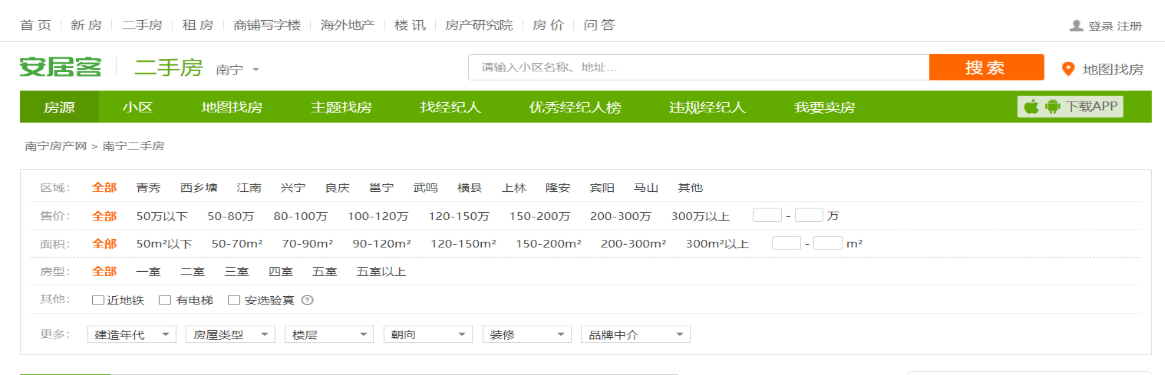
1 打开安居客二手房页面,如 https://nanning.anjuke.com/sale/?from=navigation 。得到如下页面。
通过分析发现,每个主页有60个二手房信息。一共有50个主页(一般类似网站都只提供50个主页)。
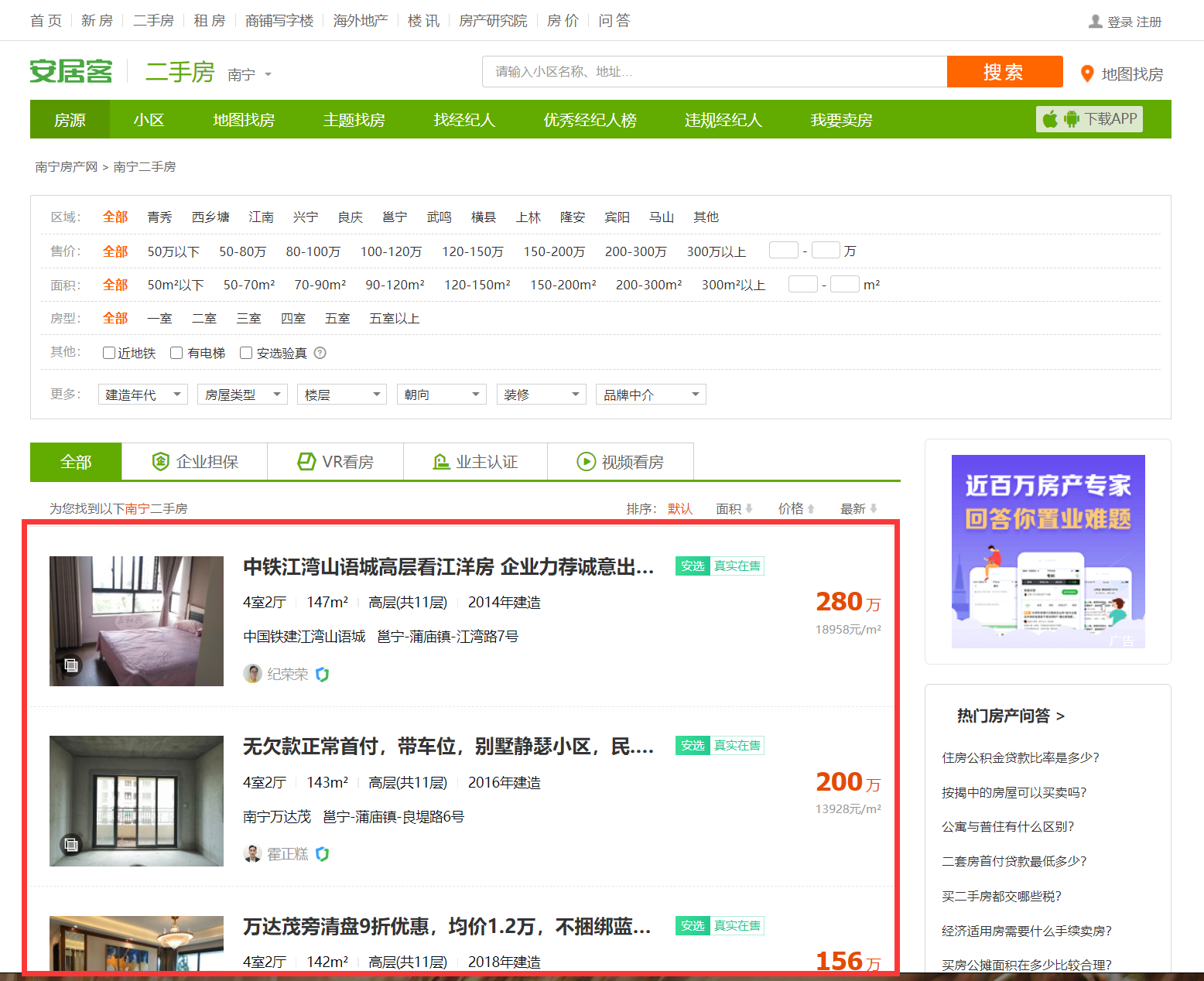
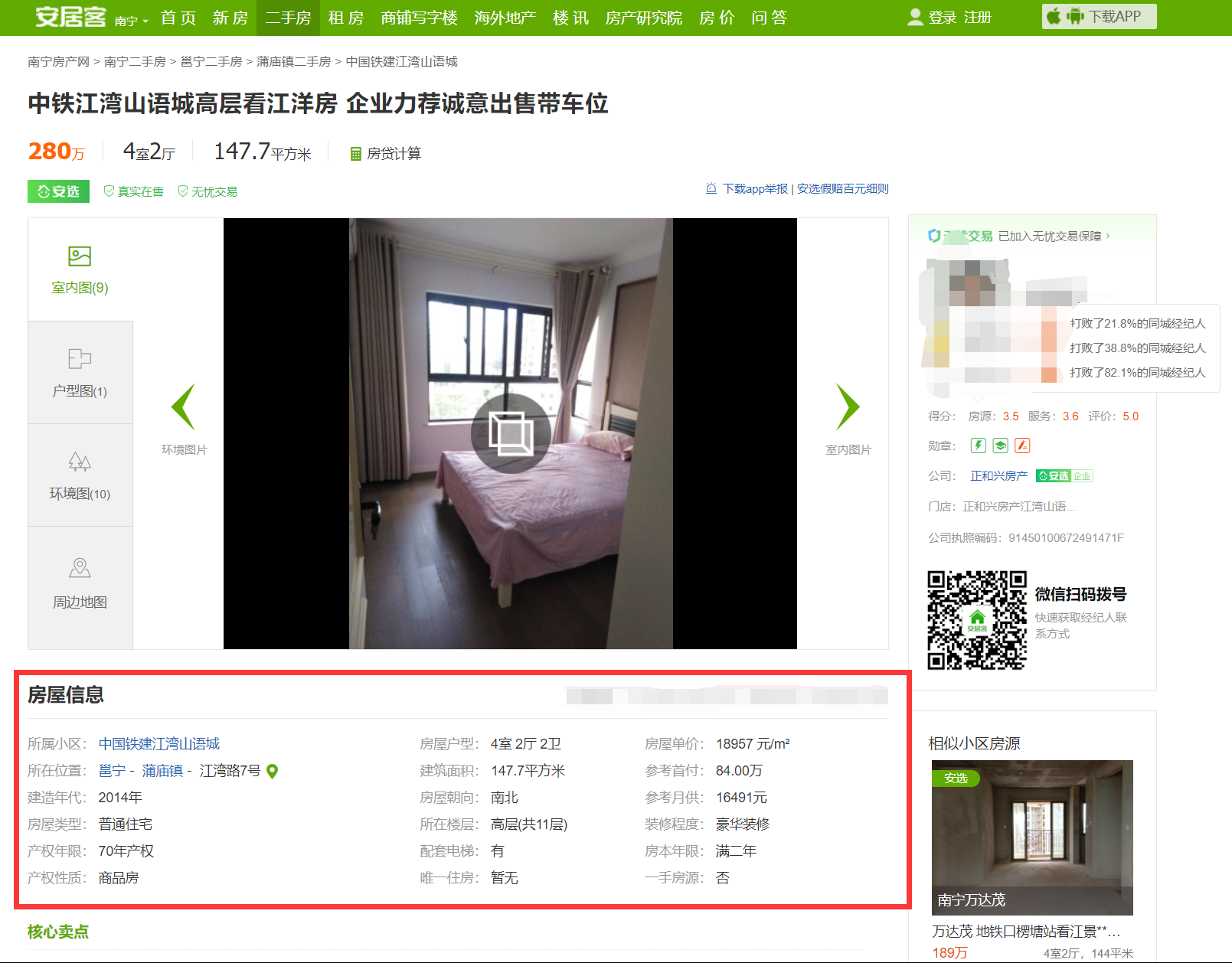
2 打开其中一个二手房的信息后,跳转到如下页面。我们的目标是要得到下图所示框起来的“房屋信息”的内容。
也就是我们需要爬取 50 * 60 = 3000 个“房屋信息”
思路
1 获取50个主页源码。
如果使用本机ip进行reques请求主页源码后,安居客的反爬机制会检测出我们的请求,提示如下页面。为了解决这个问题,应该使用代理IP代替本机ip。

本次使用蘑菇隧道代理IP,并且对官方接口进行了部分修改。在定义的接口函数中,使用while循环和 try : ... except : ... 的目的是为了能够在请求url失败的时候重新进行请求。使用 if 语句来判断请求的次数是否超过8次,如果超过8次那么就退出请求。请求安居客的页面时,有时候虽然请求失败了(即请求到的内容不是我们需要的内容),但是程序也不会报错,而是返回一个无效的页面,这个无效的页面的字符串长度小于1000。因此可以使用 if 语句来判断请求到的内容的字符串长度是否大于1000,如果大于1000就说明获取到的内容是我们所需要的。注意:当蘑菇隧道代理的代理IP每秒请求(并发)为1时,如果请求失败,需要重新请求,需要在重新请求前延时等待一秒。即添加 time.sleep(1)
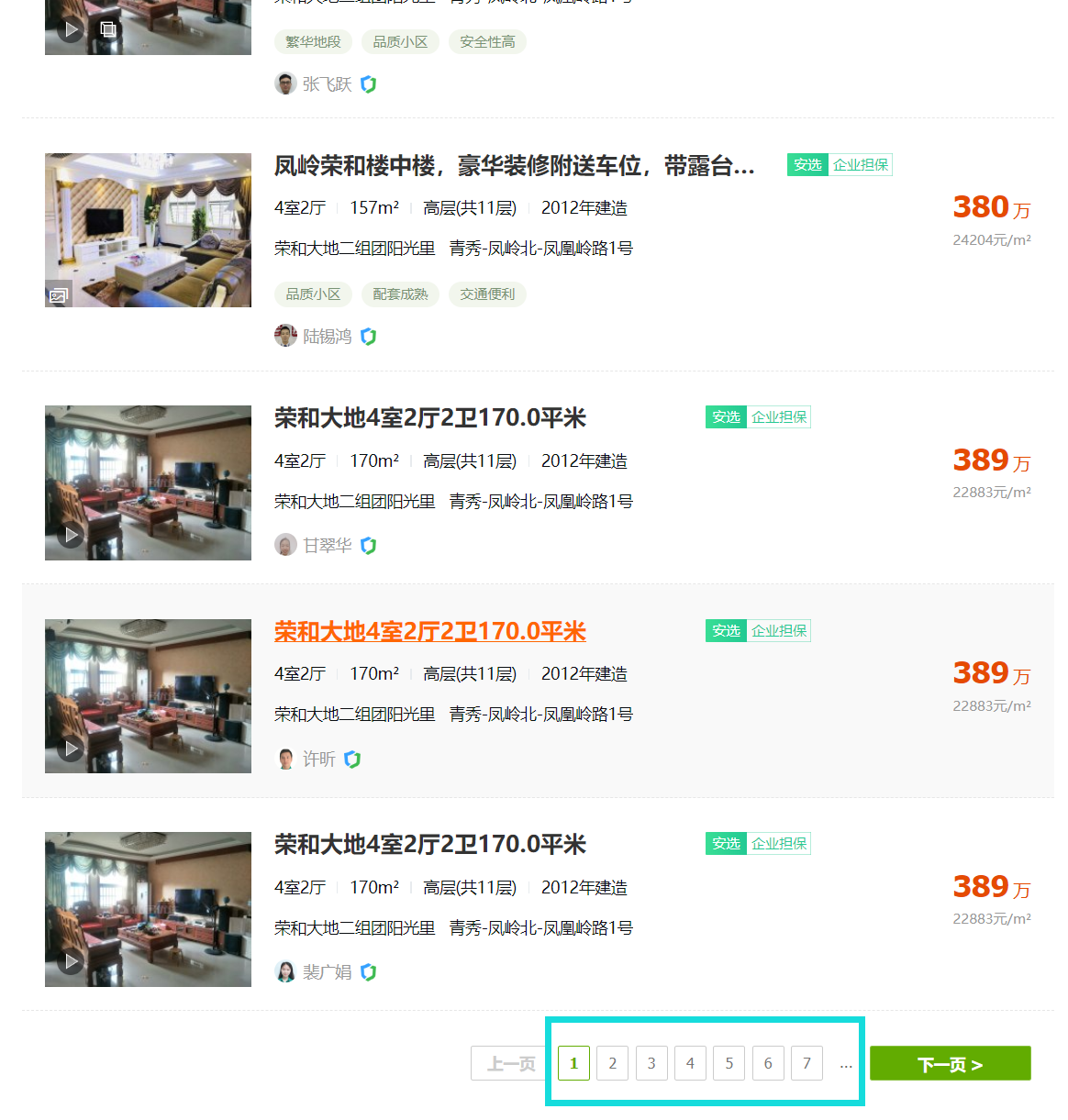
2 获取主页源码后,使用xpath抓取每个主页的60个二手房的跳转链接。如下图所示。
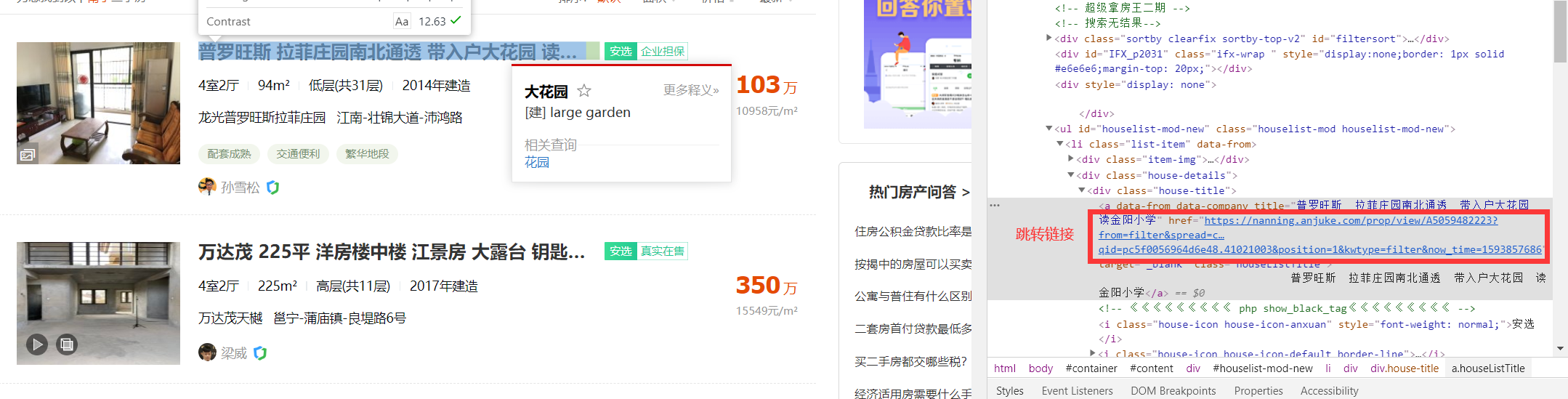
3 使用requests请求获取到的跳转链接。
4 使用xpath对跳转链接的源码获取房屋信息的内容。
获取到详细页的源码后,通过观察发现,房屋信息的每一个小信息(包括字段和对应内容)都存放在一个<li>标签里。这个小信息的字段是<li>标签里的第一个<div>标签的文本,字段对应的内容是<li>标签里的第二个<div>标签的文本。
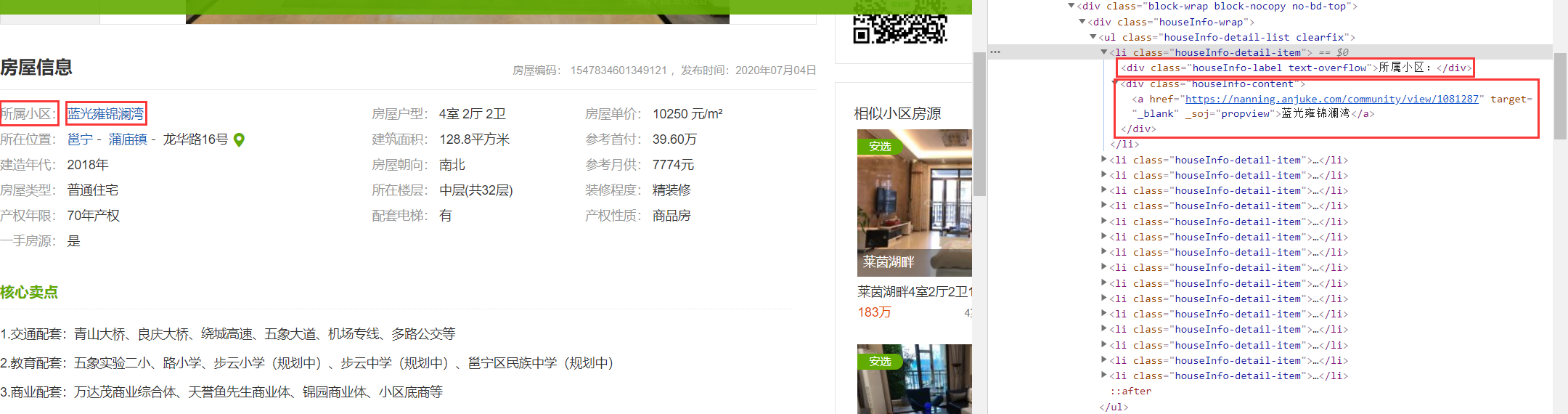
我们需要成对地将一个小信息的字段和内容爬取出来,做法是:
①将小信息的标签用xpath定位。
我第一次在对应代码位置通过点击右键的Copy的Cope XPath定位的路径,得到定位的路径 " //*[@id="content"]/div[3]/div[1]/div[3]/div/div[1]/ul/li[1] ",这个路径是通过id来定位的,但是使用xpath查找这个路径时,获取不到结果。因此后面我改为使用class定位就能获取到结果,即" //*//li[@class="houseInfo-detail-item"] "。总结:xpath有时候如果使用id定位不到,建议换其他属性定位。
因为每一个小信息的class属性都是一样的,所以获取到一个列表,这个列表的元素是每一个小信息。
②对获取到的列表进行遍历,每次遍历的结果是一个小信息。对这个小信息用xpath方法获取第一个div文本(字段)和第二个div文本(对应的内容)。
③对得到的字段和对应的内容进行数据的清洗。然后以键值对的形式添加到一个空字典。
5 通过多个详情页观察发现,存在一些详情页的房屋信息的小信息个数不同。详情页的小信息最多有18个。有的详情页小信息个数少于18个。针对这个问题,解决的方法是:
创建一个列表,这个列表有18个字段。对这个列表进行遍历,使用 not in 方法判断每次遍历出的字段是否在字典的键里,如果不在,那么就以键值对的方式给字典添加这个不在的字段和对应的内容 '暂无' 。
1 import requests 2 from lxml import etree 3 import re 4 5 # 该函数请求网页时使用的代理IP是蘑菇隧道代理,该函数用于请求网页源代码。 6 def mogu_suidaodaili(url,appKey): 7 # 蘑菇隧道代理服务器地址 8 ip_port = 'secondtransfer.moguproxy.com:9001' 9 proxy = {"http": "http://" + ip_port, "https": "https://" + ip_port} 10 headers = { 11 "Proxy-Authorization": 'Basic ' + appKey, 12 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0", 13 "Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4"} 14 num = 0 15 while 1: 16 if num != 8: 17 try: 18 r = requests.get(url=url, headers=headers, proxies=proxy, verify=False, allow_redirects=False) 19 if r.status_code == 302 or r.status_code == 301: 20 loc = r.headers['Location'] 21 print(loc) 22 url_f = loc 23 r = requests.get(url_f, headers=headers, proxies=proxy, verify=False, allow_redirects=False) 24 return r.content.decode('utf-8') 25 if len(r.content.decode('utf-8')) > 1000 : 26 return r.content.decode('utf-8') 27 else: 28 num = num + 1 29 print('当前代理ip请求失败,正在进行第' + str(num) + '次重新请求') 30 except: 31 num = num + 1 32 print('当前代理ip请求失败,正在进行第'+str(num)+'次重新请求') 33 else: 34 return '请求8次失败,退出请求' 35 36 def get_jump_url(home_page): 37 etree_object = etree.HTML(home_page) 38 jump_url = etree_object.xpath('//*[@id="houselist-mod-new"]/li/div[2]/div[1]/a/@href') 39 return jump_url 40 41 def get_information(detail_page): 42 etree_object = etree.HTML(detail_page) 43 # 因为我使用在对应代码位置通过点击右键的Copy的Cope XPath定位的路径,即//*[@id="content"]/div[3]/div[1]/div[3]/div/div[1]/ul/li[1]。这个路径是通过id来定位的,但是这个路径获取不到内容,所以改为使用class属性定位。有时候如果使用id定位不到,建议换其他属性定位。 44 informations = etree_object.xpath('//*//li[@class="houseInfo-detail-item"]') 45 46 dict = {} 47 for information in informations: 48 ziduan = information.xpath('div[1]//text()')[0] 49 content = information.xpath('div[2]//text()') 50 # str.strip(str) 这个方法移除字符串头尾指定的字符或字符序列 51 ziduan = ziduan.strip(':') 52 53 # '指定分隔符'.join(seq) 这个方法将序列中的元素以指定分隔符连接生成一个新的字符串 54 content = ''.join(content) 55 56 # re.sub(pattern, repl, string, count) 替换函数,将规则表达式pattern匹配到的字符串替换为repl指定的字符串,参数count用于指定最大替换次数。正则表达式中 s 用于匹配任意空白字符(包括 fv) 57 pattern = 's' 58 content = re.sub(pattern,'',content) 59 60 # 因为遍历出的一个content值的尾部有ue003,所以需要用到strip方法去掉。 61 content = content.strip('ue003') 62 63 #dict.update(dict2) 这个方法把字典dict2的键/值对更新到dict里。 64 dict.update({ziduan:content}) 65 66 list = ['所属小区','房屋户型','房屋单价','所在位置','建筑面积','参考首付','建造年代','房屋朝向','房屋类型','所在楼层','装修程度','产权年限','配套电梯','房本年限','产权性质','唯一住房','一手房源','测试'] 67 for i in list: 68 # dict.keys() 这个方法以列表返回一个字典所有的键。 69 if i not in dict.keys(): 70 dict[i] = '暂无' 71 return dict 72 73 if __name__ == '__main__': 74 appKey = ****** 75 for page in range(50): 76 page = page + 1 77 url = 'https://nanning.anjuke.com/sale/p'+str(page)+'/#filtersort' 78 print('=============================现在请求的是第'+str(page)+'页================================') 79 home_page = mogu_suidaodaili(url=url,appKey=appKey) 80 jump_urls = get_jump_url(home_page) 81 for jump_url in jump_urls: 82 detail_page = mogu_suidaodaili(url=jump_url,appKey=appKey) 83 print(get_information(detail_page))
补充
当我们后期如果想做数据分析的话,就会需要大量的信息。我们发现标签为 区域:全部;售价:全部;面积:全部;房型:全部 的50个主页提供的信息并不能满足数据分析的数量。
要想获取更多信息,可以依次抓取标签顺序如下的的50个主页提供的信息:
区域:青秀;售价:50万以下;面积:50²以下;房型:一室
区域:青秀;售价:50万以下;面积:50²以下;房型:二室
。。。
区域:青秀;售价:50万以下;面积:50m²以下;房型:五室以上
区域:青秀;售价:50万以下;面积:50-70m²;房型:一室
。。。
区域:青秀;售价:50万以下;面积:50-70m²;房型:五室以上
。。。
区域:其他;售价:300万以上;面积:300m²以上;房型:五室以上