通过一些HASH算法或者工具实现将一张数据表垂直或者水平进行物理切分
适用场景
1、单表记录条数达到百万或千万级别时
2、解决表锁的问题
分表方式
水平分表:表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询次数

适用场景
1、表中的数据本身就有独立性,例如表中分表记录各个地区的数据或者不同时期的数据,特别是有些数据常用,有些不常用。
2、需要把数据存放在多个介质上。
例子:qq登录, 由于qq号特别多, 现在通过取模算法, 来对sql优化, 分99张表, 通过100取模, 余数就是这条数据判定的表!!!
水平切分的缺点
1、给应用增加复杂度,通常查询时需要多个表名,查询所有数据都需UNION操作
2、在许多数据库应用中,这种复杂度会超过它带来的优点,查询时会增加读一个索引层的磁盘次数
垂直分表
把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中
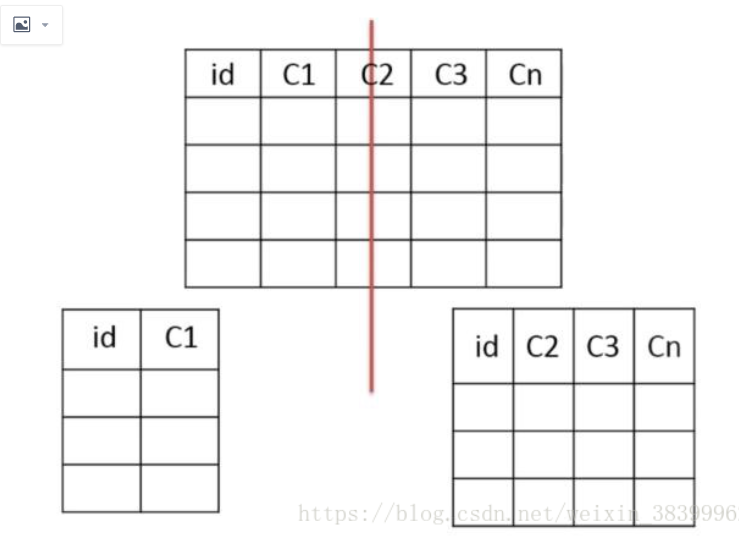
适用场景
1、如果一个表中某些列常用,另外一些列不常用
2、可以使数据行变小,一个数据页能存储更多数据,查询时减少I/O次数
例子: 上图是垂直分割, 有一张成绩表, 里面有学生id,学生姓名,学生题目, 学生答案, 但是你会发现sql语句是
select * from tt where id ="8"; 这时候查全表, 会有题目 和 答案, 这个表就比较大, 这时候把题目,和答案分出去, 留一张信息表就可以了, 查询的时候直接查询信息表, 而不用查询题目和答案, 不过大型企业项目都会把一些大文件存放在专门的图片或者文件服务器中,所以这些我们都不需要考虑了
缺点
分表缺点
有些分表的策略基于应用层的逻辑算法,一旦逻辑算法改变,整个分表逻辑都会改变,扩展性较差
对于应用层来说,逻辑算法增加开发成本
MySQL的复制原理及负载均衡
MySQL主从复制工作原理
在主库上把数据更高记录到二进制日志
从库将主库的日志复制到自己的中继日志
从库读取中继日志的事件,将其重放到从库数据中
MySQL主从复制解决的问题
数据分布:随意开始或停止复制,并在不同地理位置分布数据备份
负载均衡:降低单个服务器的压力
高可用和故障切换:帮助应用程序避免单点失败
升级测试:可以用更高版本的MySQL作为从库
解题方法
充分掌握分区分表的工作原理和适用场景,在面试中,此类题通常比较灵活,会给一些现有公司遇到问题的场景,大家可以根据分区分表,MySQL复制、负载均衡的适用场景来根据情况进行回答
真题
设定网站用户数量在千万级,但是活跃用户数量只有1%,如何通过优化数据库提高活跃用户访问速度?
答:
可以使用 ,把活跃用户分在一个区,不活跃用户分在另外一个区,本身活跃用户区数据量比较少,因此可以提高活跃用户访问速度。
还可以水平分表,把活跃用户分在一张表,不活跃用户分在另一张表,可以提高活跃用户访问速度。