之前本人说过一款非关系型数据库的代表 Redis 的 《 Redis 小记 》文章,觉得意犹未尽,今天就来介绍一款数据库 MongoDB ,先来看一下
MongoDB是一款基于分布式文件存储的数据库,是一种文档型数据库,是介于关系型和非关系型数据库之间的产品,是最接近关系型数据库的数据库。MongoDB中的每一条记录就是一个文档,是一个数据结构,由字段和值对组成,字段的值可能其他文档,数组,以及文档数组。一般用作离线数据分析使用,放在内网居多,提供高性能的数据持久化。
以上为网上对于 MongoDB 的解释,总结起来就是一句话:好!
老规矩,话不多说,直接开撸。
关于 MongoDB 的安装就不介绍了,大家根据电脑版本型号自行搜索安装。
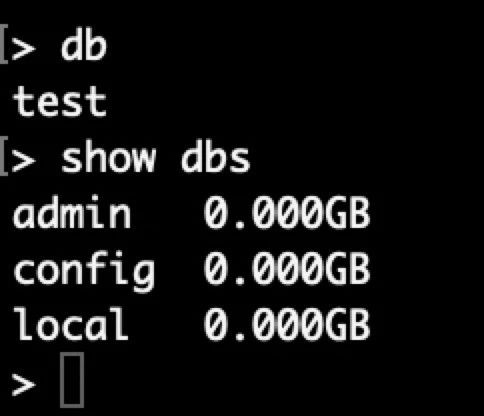
安装并配置好 MongoDB 后我们在终端输入 db 及 show dbs 出现以下内容说明安装成功。MongoDB 默认数据库为 test 数据库,我们也可以自己创建数据库,如下。
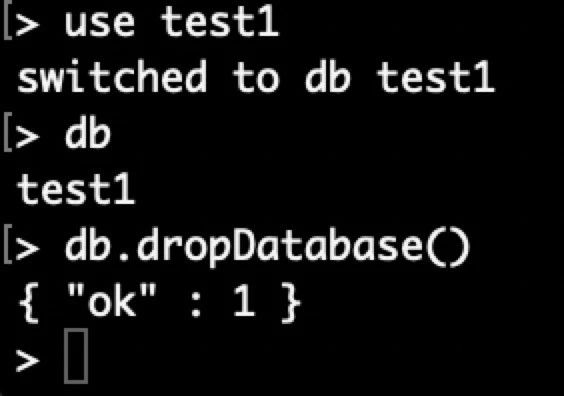
MongoDB 在创建数据库上还是很方便的,如上图,use test1 表示如果有 test1 这个数据库就切换到该数据库,如果没有则创建并切换到该数据库,通过 db 命令查看当前使用的数据库并且可以删除该数据库。

如上图,db.createCollection( name , options ) 可以创建集合,其中 name 为必填项,为集合的名称,options 为可选项,选项中 capped 默认值为 false 表示不设置上限,值为 true 表示设置上限;当 capped 值为 true 时需设置 size 值,size 值为集合的上限,当超过上限时再插入数据会将之前的数据覆盖,单位为字节。

如上图,MongoDB 通过 db.集合名称.insert( ) 向集合中添加数据,可以通过 db.集合名称.update( ) 对集合进行数据更新,db.集合名称.find() 对数据进行查找,操作中其实还有很多选填项,这个稍后会说。

db.集合名称.remove( ) 可以对集合进行删除,第一个 { } 表示要删除数据的匹配项,第二个 { } 表示删除多个还是一个,true 表示只删除匹配到的第一个,false 表示删除匹配到的所有数据,db.集合名称.remove( { } ) 表示删除所有数据。
从上面对 MongoDB 增删改查的基本操作我们发现其语法很接近 JavaScript 这类语言,对于我们这种初学者还是很友好的。但是语法上要比之前说过的 Redis 复杂一些,所以接下来的操作就不在终端进行操作了,移驾 Robo 3T (萝卜) 软件。

图标就是上面这个长得跟萝卜似的大眼仔,直接下载安装即可。打开软件我们先进行如下配置。
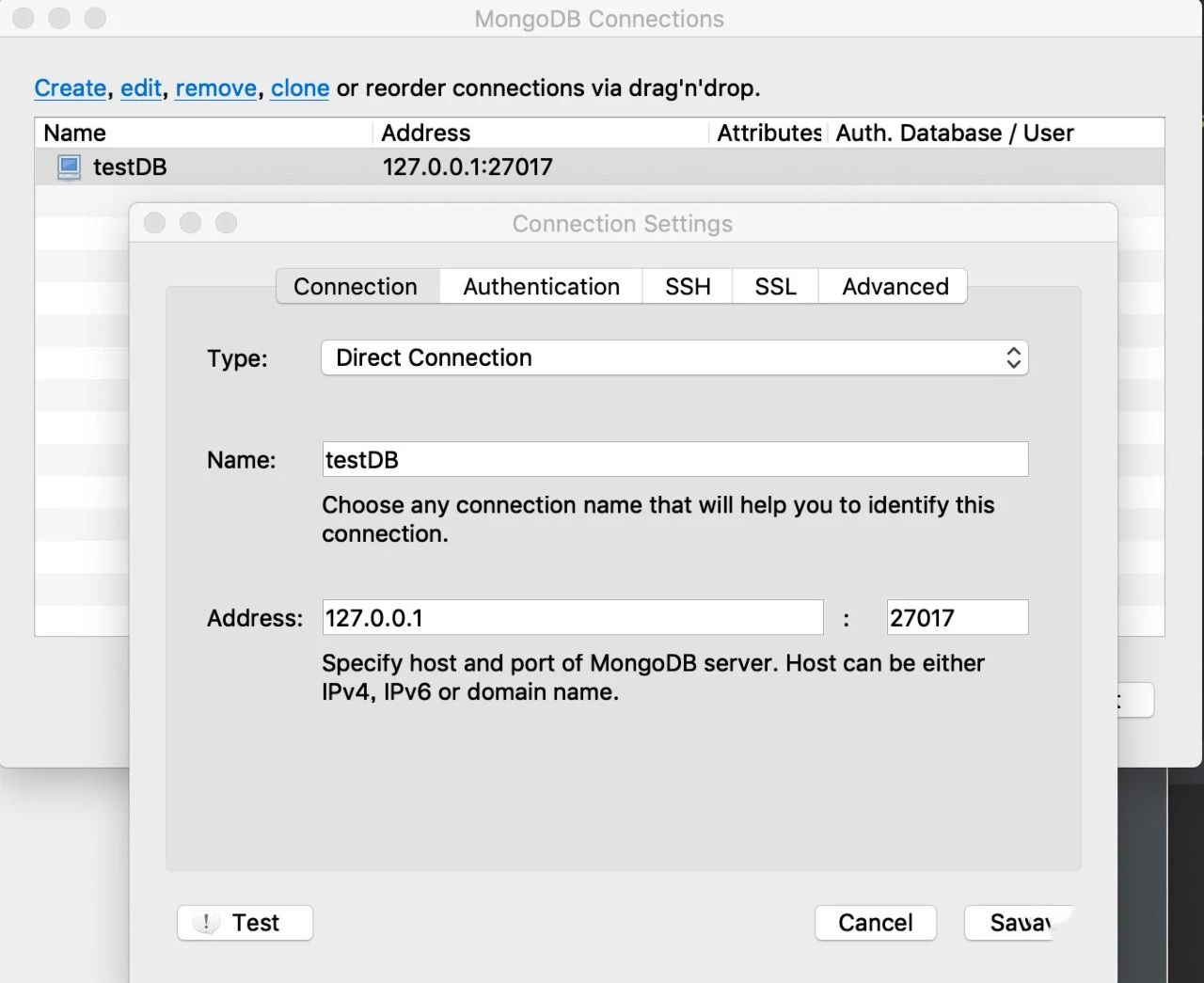
因为我们是在本地测试,所以 ip 为 127.0.0.1,端口号用 MongoDB 默认的 27017 端口。点击 Save 保存之后点击 Connect 进行连接即可。

进来之后我们发现在错侧栏我们之前在终端创建的 test2 数据库还在,我们可以选中右键对其进行操作。我们也可以选中下方的 Collections 对其进行集合的操作,这些大家安装之后操作一下就可以了,很方便。右侧最上面黑条内可以输入我们想要的操作,对应的在下方会看到操作的输出结果,话不多说,操作起来。
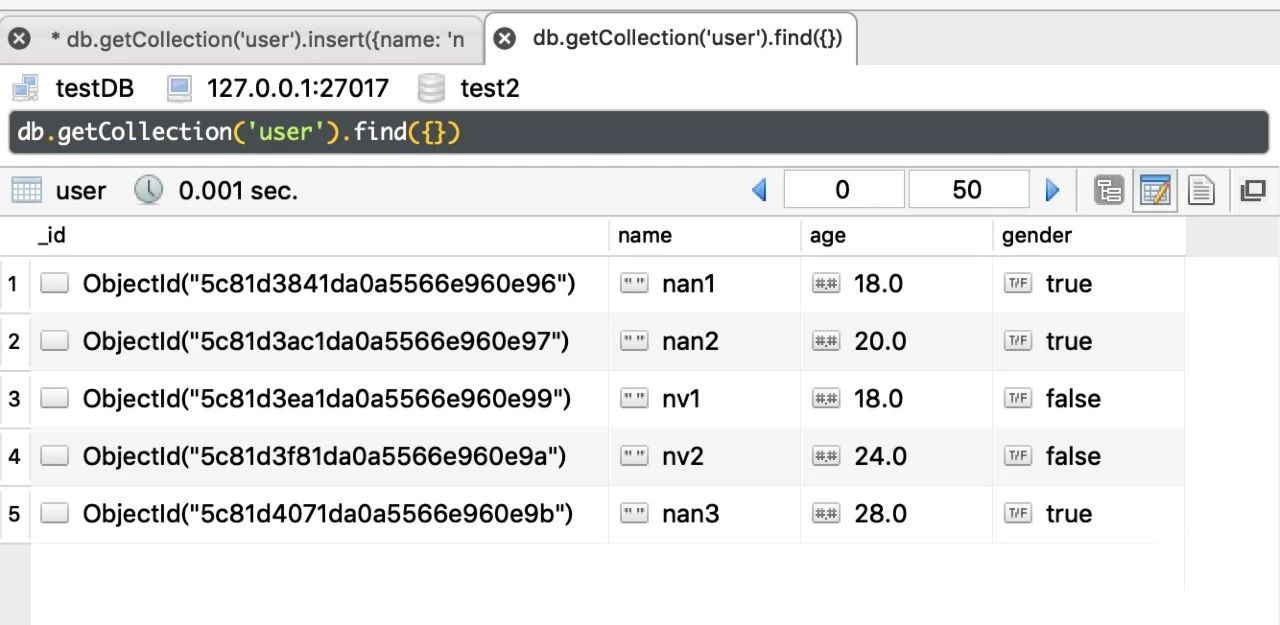
我们在之前终端创建的集合内插入 5 条数据,在软件右上角除可以对数据的显示状态进行切换。
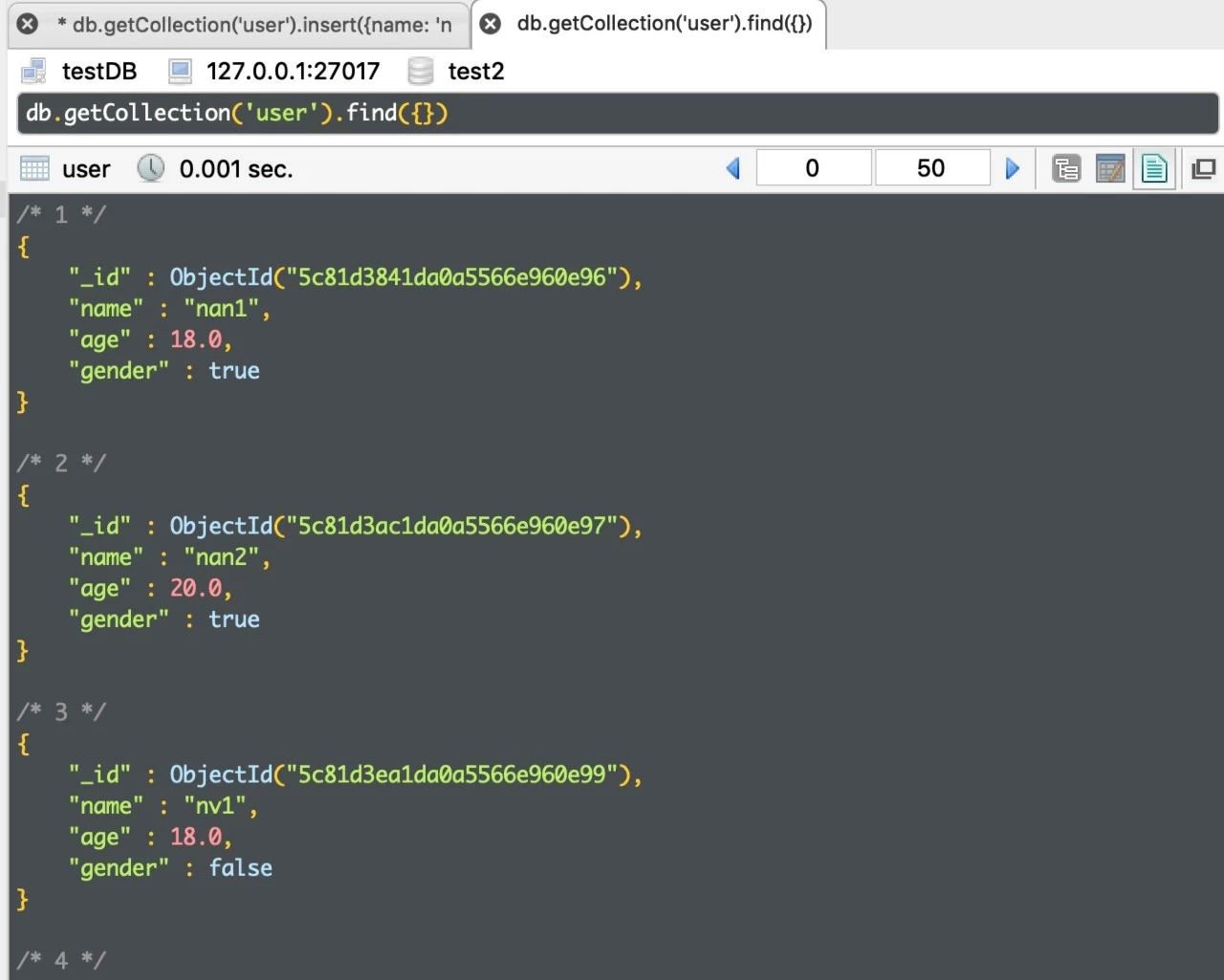
我们将其展示为直观的 json 数据格式。我们可以看出,在使用 MySQL 等关系型数据库时,主键都是设置自增的,但是在分布式环境下,这种方法就不可行了,会产生冲突,为此,MongoDB 采用了一个称之为 ObjectId 的类型来做主键,是一个随机生成的 BSON 类型的字符串,具体含义大家自行百度,不是重点。
数据库中大部分操作都是围绕查询来进行操作的,这里我们着重看一下 MongoDB 在数据查询方面的写法。
基本查询
方法find():查询
db.集合名称.find({条件文档})
方法findOne():查询,只返回第一个
db.集合名称.findOne({条件文档})
方法pretty():将结果格式化
db.集合名称.find({条件文档}).pretty()
比较运算符
-
等于,默认是等于判断,没有运算符
-
小于$lt
-
小于或等于$lte
-
大于$gt
-
大于或等于$gte
-
不等于$ne
-
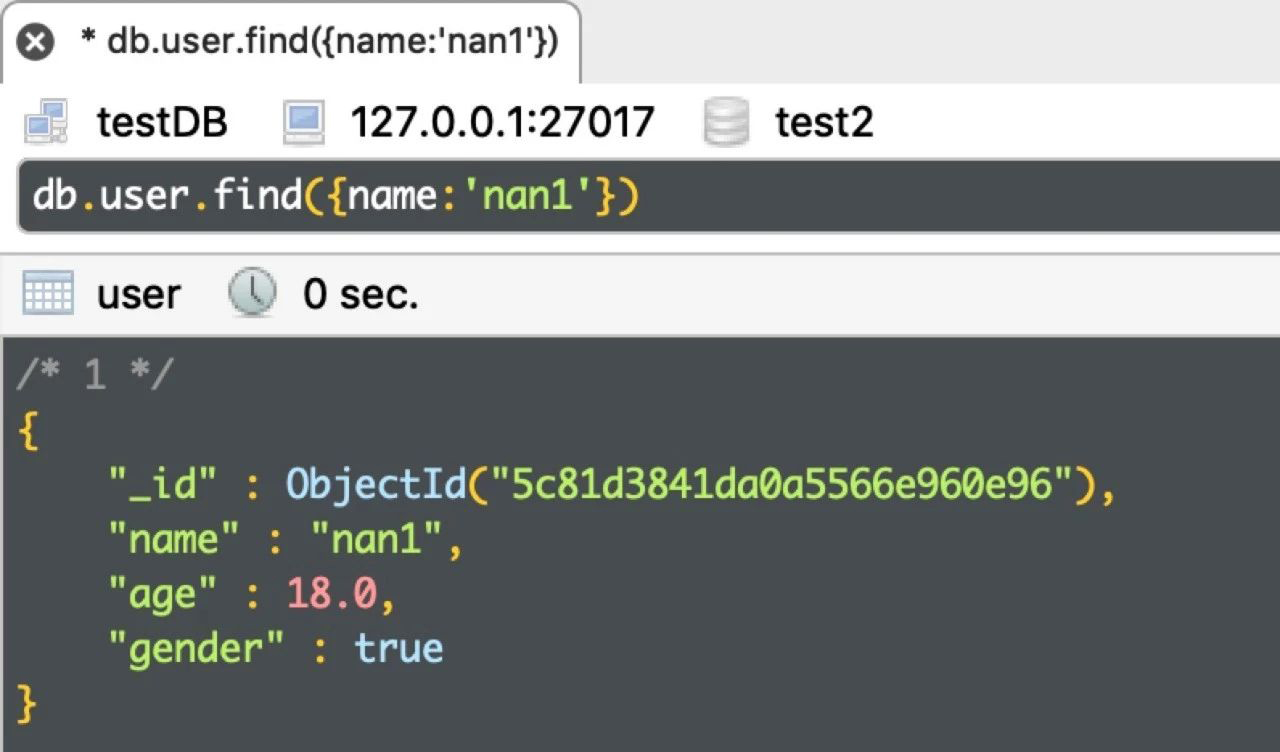
例1:查询名称等于'nan1'的人
db.user.find({name:'nan1'})
运行结果如下:
例2:查询年龄大于或等于18的人
db.user.find({age:{$gte:18}})
逻辑运算符
-
查询时可以有多个条件,多个条件之间需要通过逻辑运算符连接
-
逻辑与:默认是逻辑与的关系
-
例3:查询年龄大于或等于20,并且性别为true的人
db.user.find({age:{$gte:18},gender:true})
逻辑或:使用$or
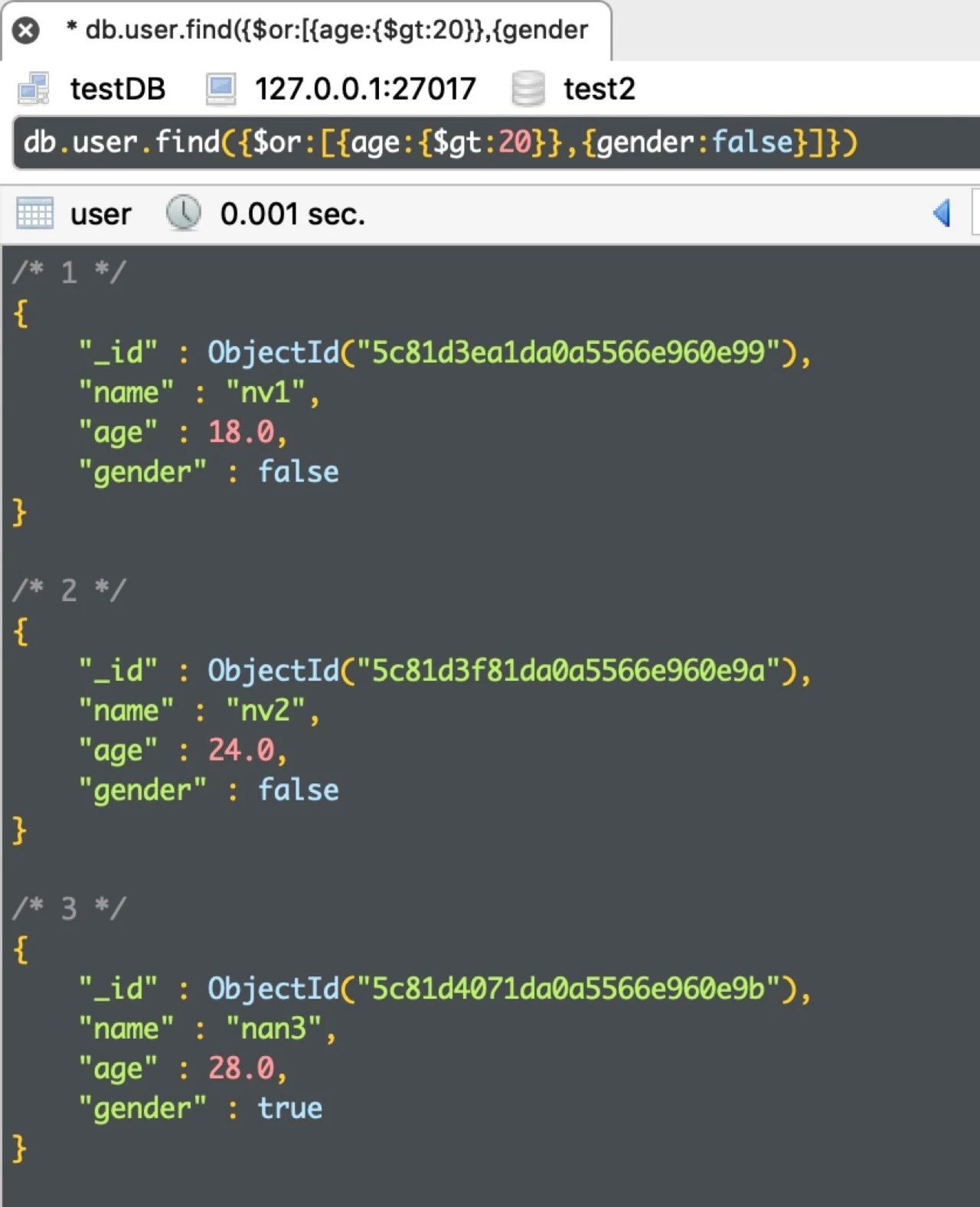
例4:查询年龄大于20,或性别为 false 的人
db.user.find({$or:[{age:{$gt:18}},{gender:false}]})
运行结果如下:
and和or一起使用
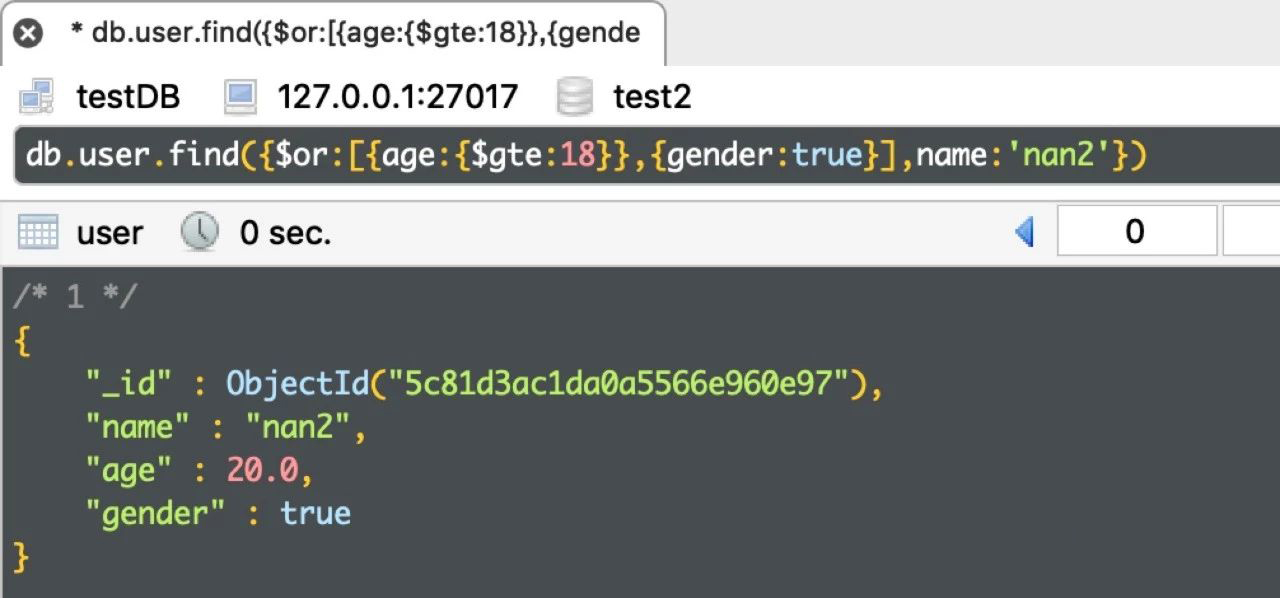
例5:查询年龄大于18或性别为 true 的人,并且人的姓名为nan2
db.user.find({$or:[{age:{$gte:18}},{gender:true}],name:'nan2'})
运行结果如下:
范围运算符
使用"$in","$in" 判断是否在某个范围内
例6:查询年龄为18、28的人
db.user.find({age:{$in:[18,28]}})
支持正则表达式
使用//或$regex编写正则表达式
例7:查询姓nan的人
db.user.find({name:/^nan/})
db.user.find({name:{$regex:'^nan'}}})
自定义查询
使用$where后面写一个函数,返回满足条件的数据
例7:查询年龄大于20的人
db.user.find({$where:function(){return this.age>20}})
Limit
方法limit():用于读取指定数量的文档
语法:
db.集合名称.find().limit(NUMBER)
参数NUMBER表示要获取文档的条数
如果没有指定参数则显示集合中的所有文档
例1:查询2条信息
db.user.find().limit(2)
skip
方法skip():用于跳过指定数量的文档
语法:
db.集合名称.find().skip(NUMBER)
参数NUMBER表示跳过的记录条数,默认值为0
例2:查询从第3条开始的user信息
db.user.find().skip(2)
一起使用
方法limit()和skip()可以一起使用,不分先后顺序
创建数据集
for(i=0;i<15;i++){db.user.insert({_id:i})}
查询第2至3条数据
db.user.find().limit(2).skip(1)
或
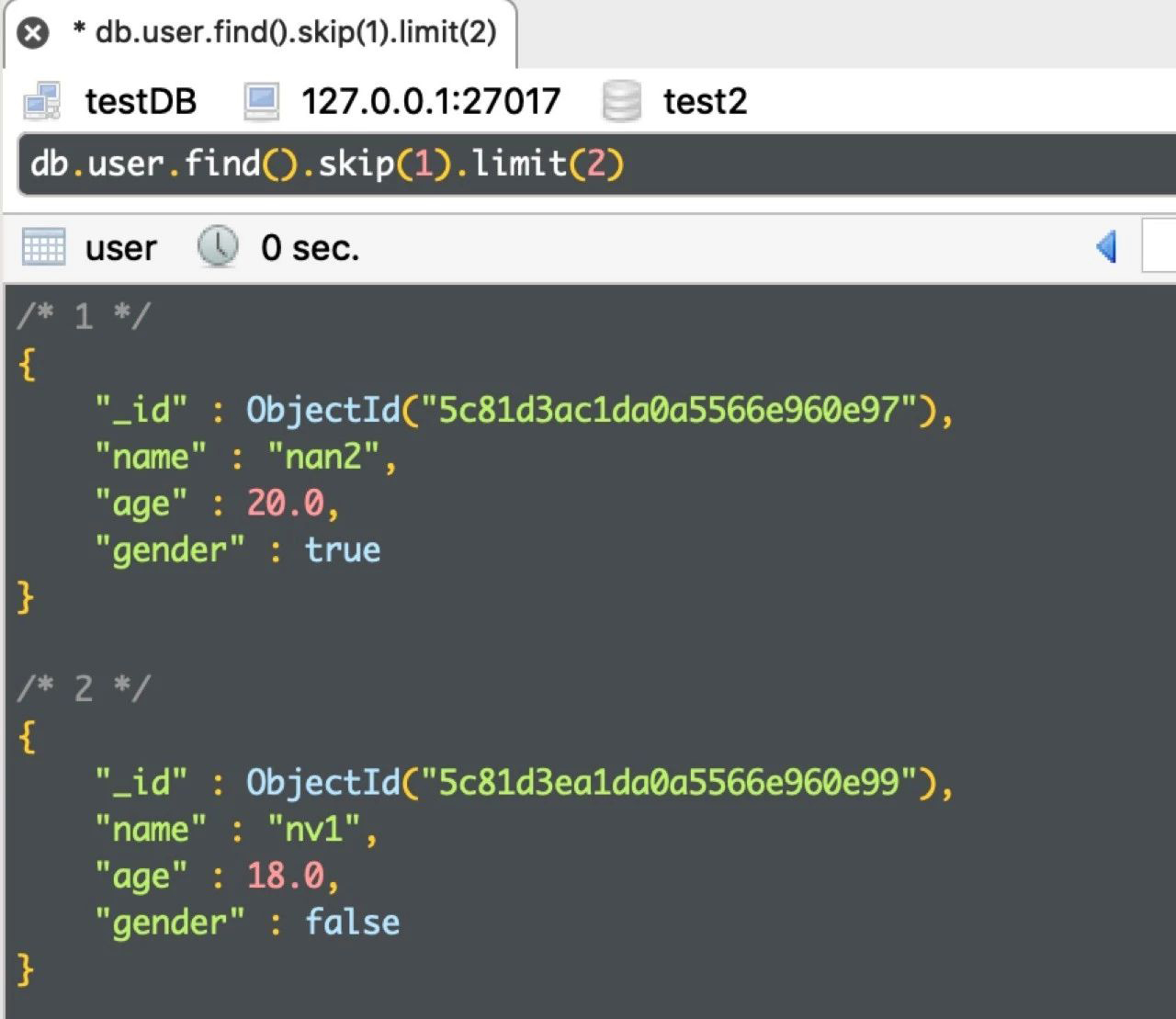
db.user.find().skip(1).limit(2)
运行结果如下:
投影
在查询到的返回结果中,只选择必要的字段,而不是选择一个文档的整个字段
如:一个文档有5个字段,需要显示只有3个,投影其中3个字段即可
语法:
参数为字段与值,值为1表示显示,值为0不显示
db.集合名称.find({},{字段名称:1,...})
对于需要显示的字段,设置为1即可,不设置即为不显示
特殊:对于_id列默认是显示的,如果不显示需要明确设置为0
例1
db.user.find({},{name:1,gender:1})
例2
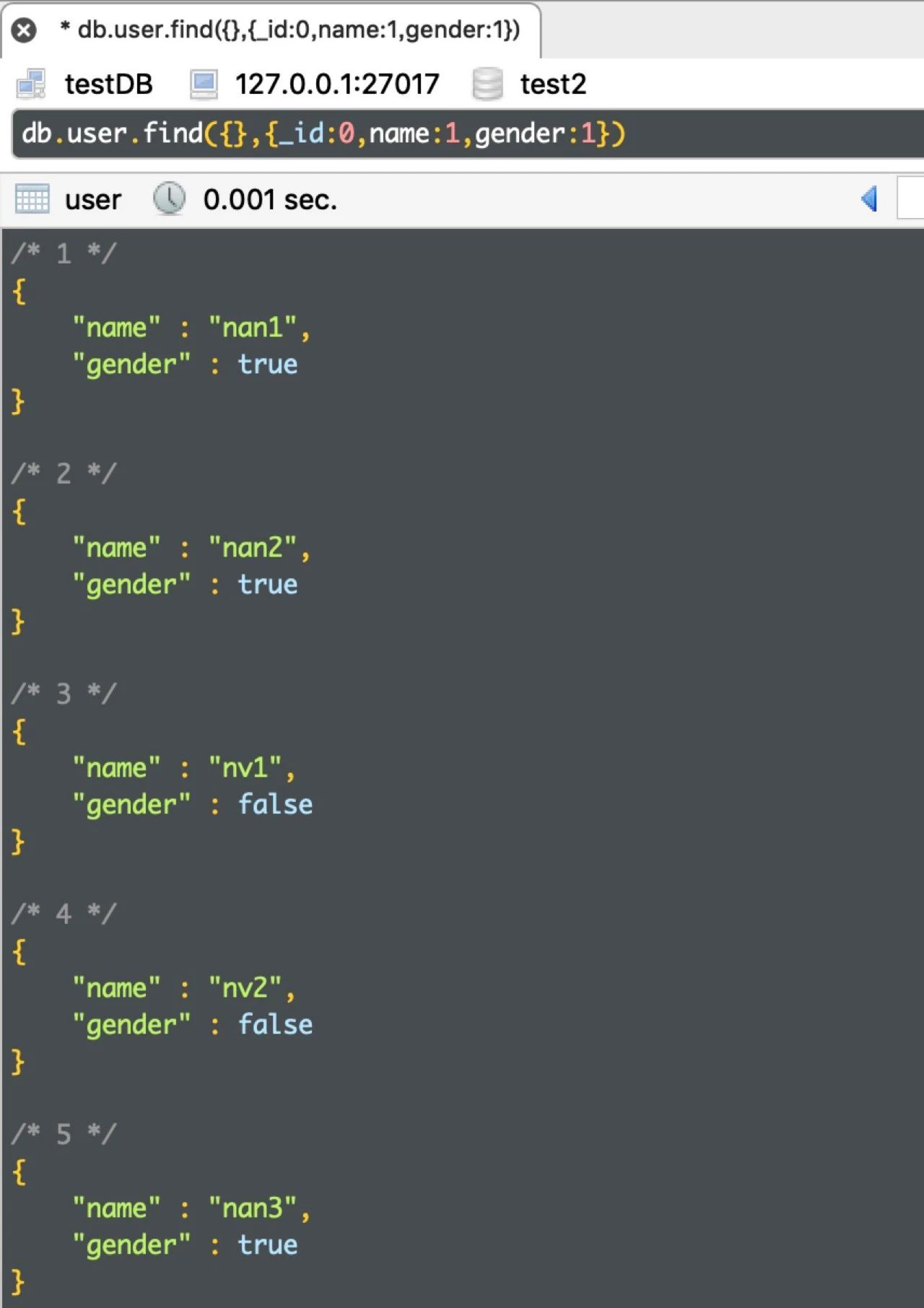
db.user.find({},{_id:0,name:1,gender:1})
运行结果如下:
排序
方法sort(),用于对结果集进行排序
语法
db.集合名称.find().sort({字段:1,...})
参数1为升序排列
参数-1为降序排列
例1:根据性别降序,再根据年龄升序
db.user.find().sort({gender:-1,age:1})
统计个数
方法count()用于统计结果集中文档条数
语法
db.集合名称.find({条件}).count()
也可以与为
db.集合名称.count({条件})
例1:统计男人数
db.user.find({gender:true}).count()
例2:统计年龄大于20的男人数
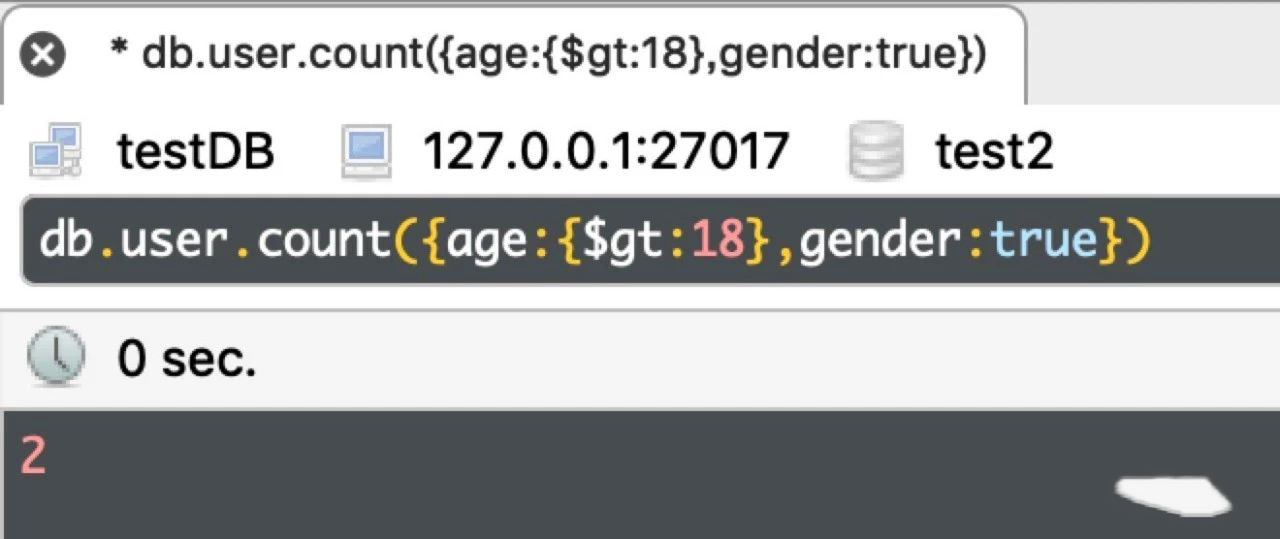
db.user.count({age:{$gt:20},gender:true})
运行结果如下
消除重复
方法distinct()对数据进行去重
语法
db.集合名称.distinct('去重字段',{条件})
例:查找年龄大于18的性别(去重)
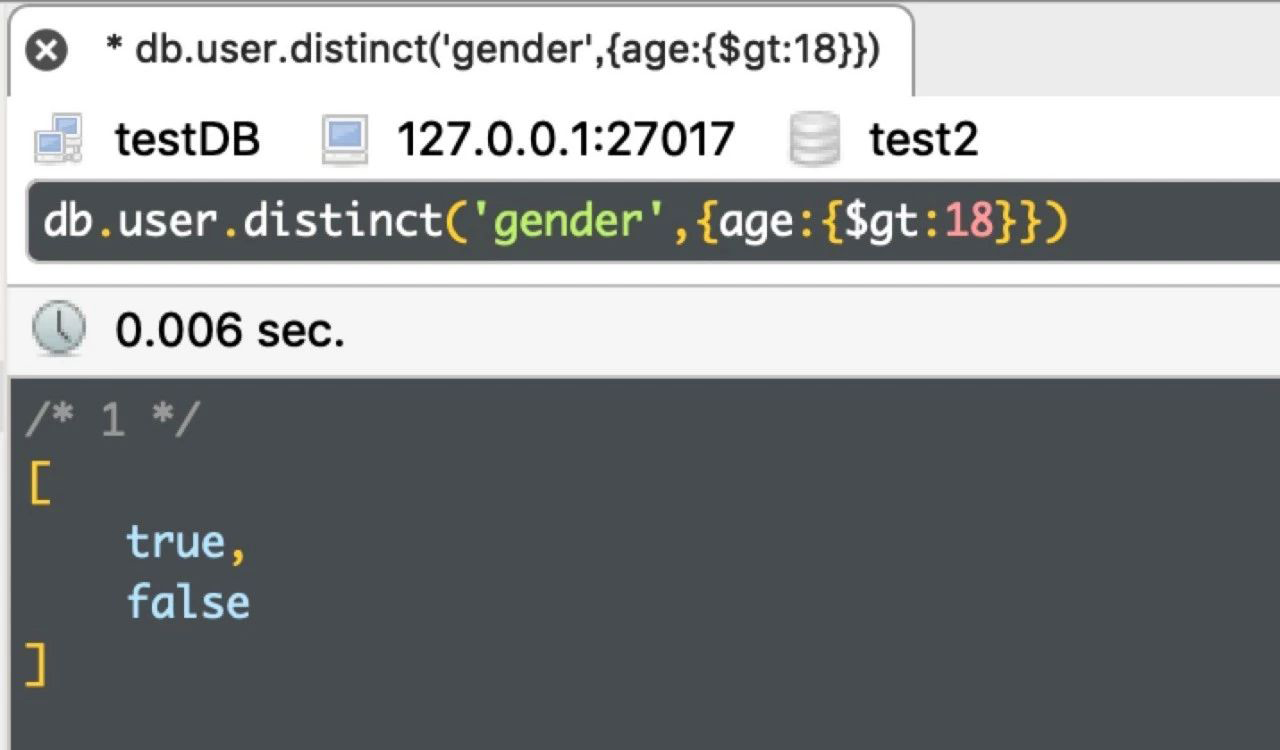
db.user.distinct('gender',{age:{$gt:18}})
运行结果如下:
以上就是 MongoDB 在数据查询方面的基本操作,基本够我们的操作使用了。
接下来我们说一下 MongoDB 语法中的高级应用 aggregate(聚合)。聚合主要用于计算数据,类似于 sql 中的 sum( ),avg( )。
db.集合名称.aggregate([{管道:{表达式}}])
管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的输入
ps ajx | grep mongo
在mongodb中,管道具有同样的作用,文档处理完毕后,通过管道进行下一次处理
常用管道
-
$group:将集合中的文档分组,可用于统计结果
-
$match:过滤数据,只输出符合条件的文档
-
$project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
-
$sort:将输入文档排序后输出
-
$limit:限制聚合管道返回的文档数
-
$skip:跳过指定数量的文档,并返回余下的文档
-
$unwind:将数组类型的字段进行拆分
表达式
处理输入文档并输出
语法
表达式:'$列名'
-
常用表达式
-
$sum:计算总和,$sum:1同count表示计数
-
$avg:计算平均值
-
$min:获取最小值
-
$max:获取最大值
-
$push:在结果文档中插入值到一个数组中
-
$first:根据资源文档的排序获取第一个文档数据
-
$last:根据资源文档的排序获取最后一个文档数据
我们先看看之前我们添加进去的数据,我们在 user 集合中添加了五条数据,有 name ,age,gender 字段,其中 gender 字段 true 表示男,false 表示女。

$group
将集合中的文档分组,可用于统计结果
_id表示分组的依据,使用某个字段的格式为'$字段'
例:统计男人、女人的总人数
db.user.aggregate([ {$group: { _id:'$gender', counter:{$sum:1} } } ])
运行结果如下:

Group by null
将集合中所有文档分为一组
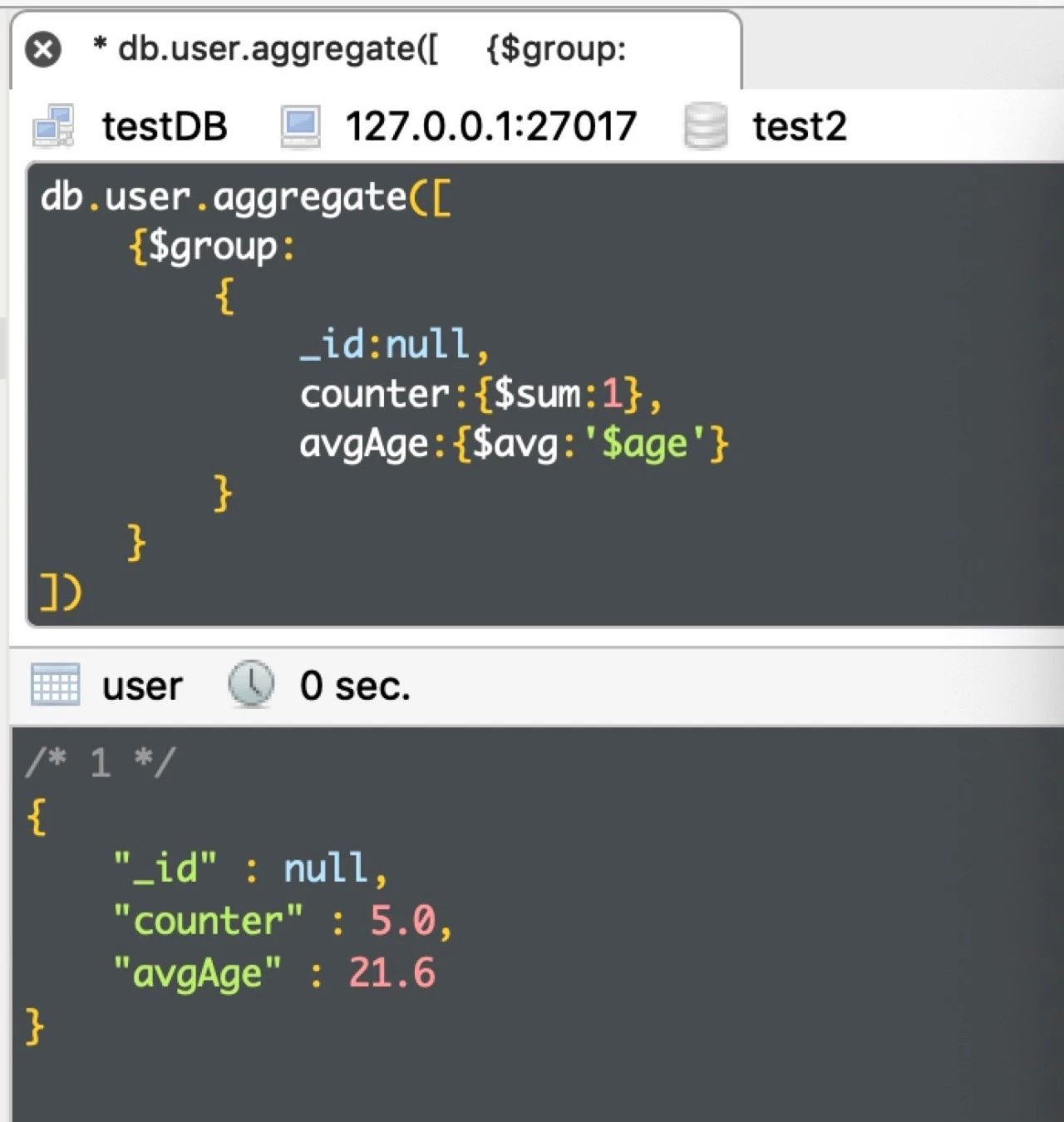
例2:求总人数、平均年龄
db.user.aggregate([ {$group: { _id:null, counter:{$sum:1}, avgAge:{$avg:'$age'} } } ])
运行结果如下:
透视数据
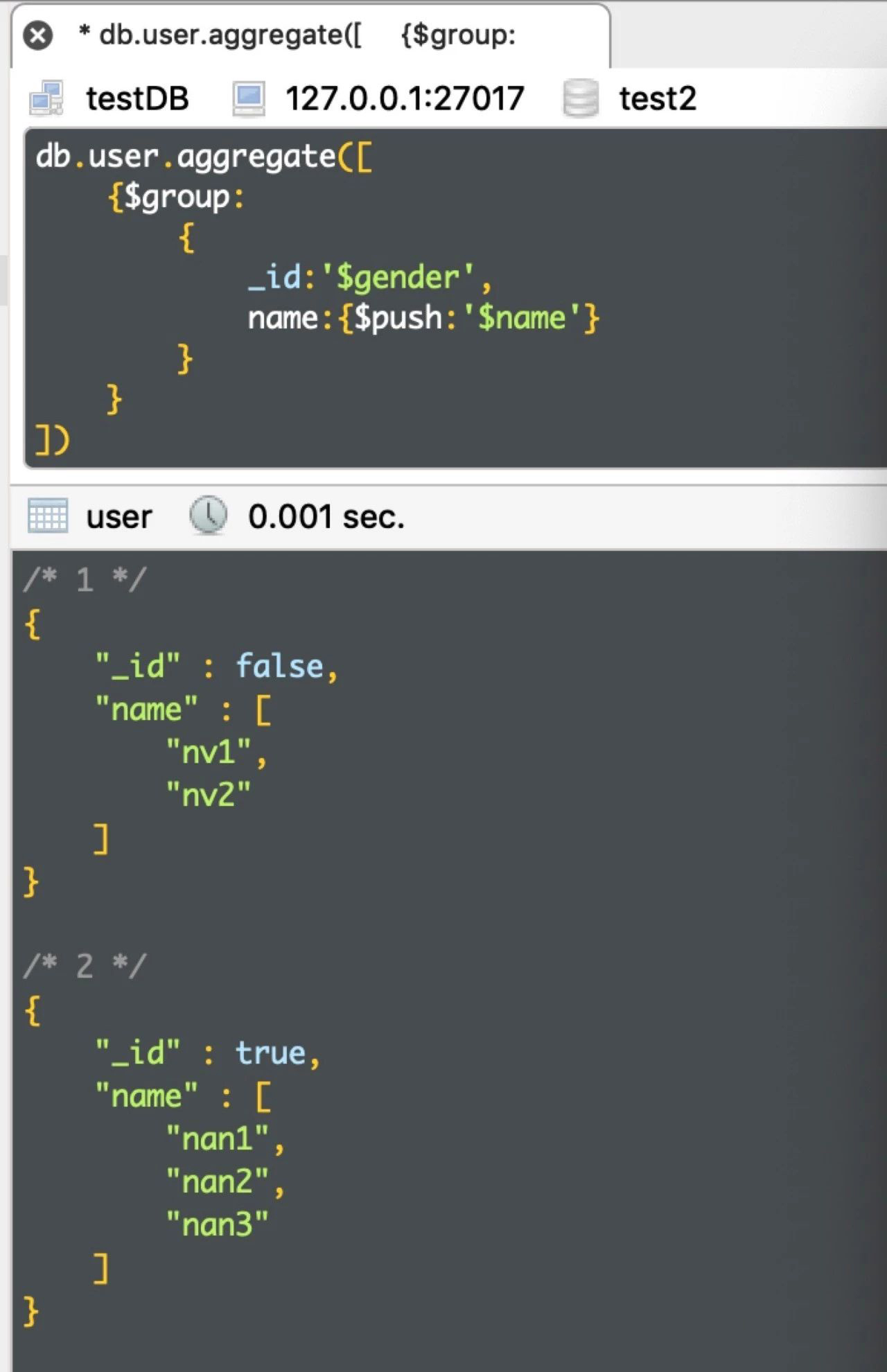
例3:统计 user 性别及姓名
db.user.aggregate([ {$group: { _id:'$gender', name:{$push:'$name'} } } ])
运行结果如下:
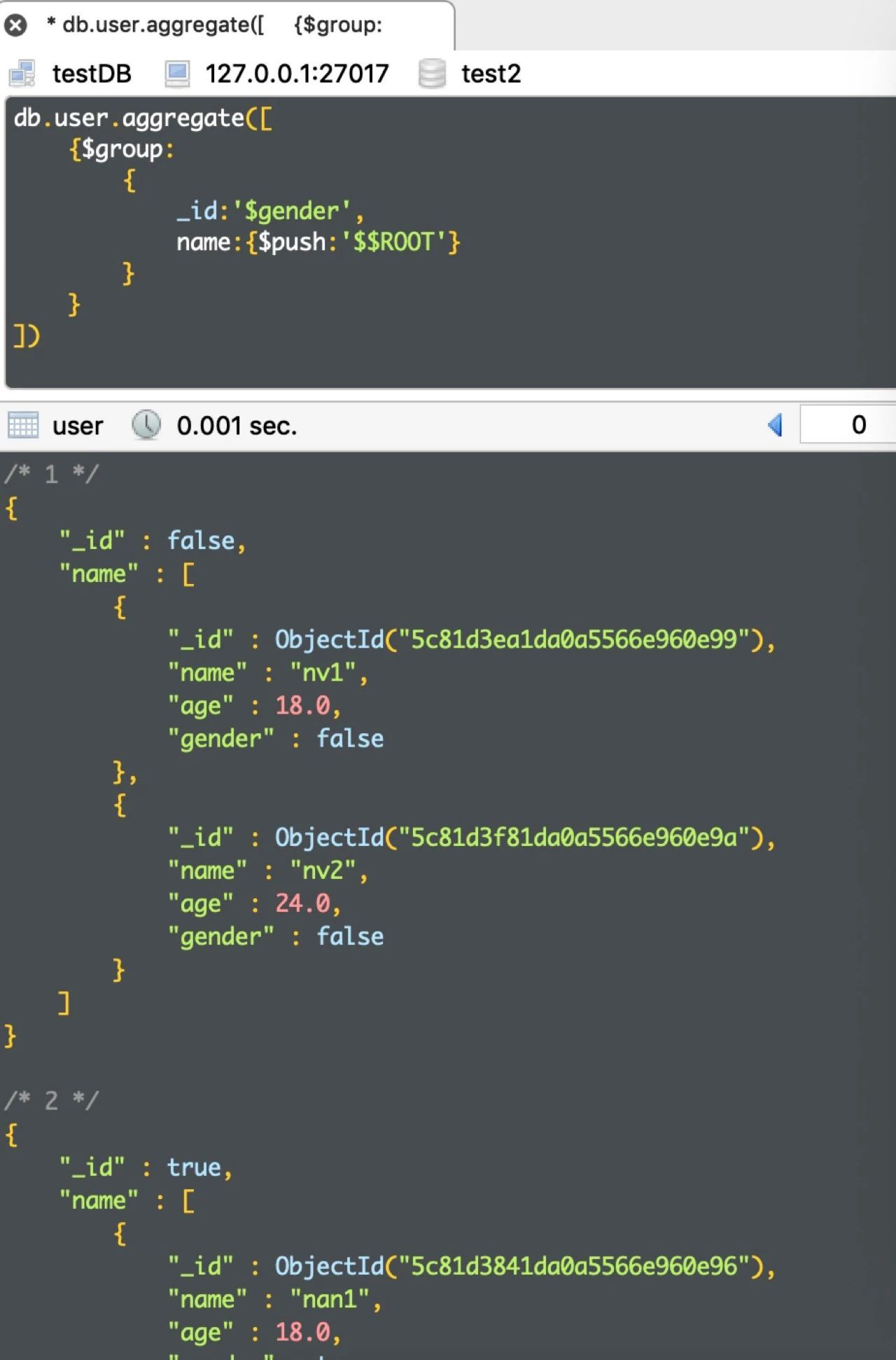
使用$$ROOT可以将文档内容加入到结果集的数组中,代码如下
db.user.aggregate([ {$group: { _id:'$gender', name:{$push:'$$ROOT'} } } ])
运行结果如下:
$match
用于过滤数据,只输出符合条件的文档
使用MongoDB的标准查询操作
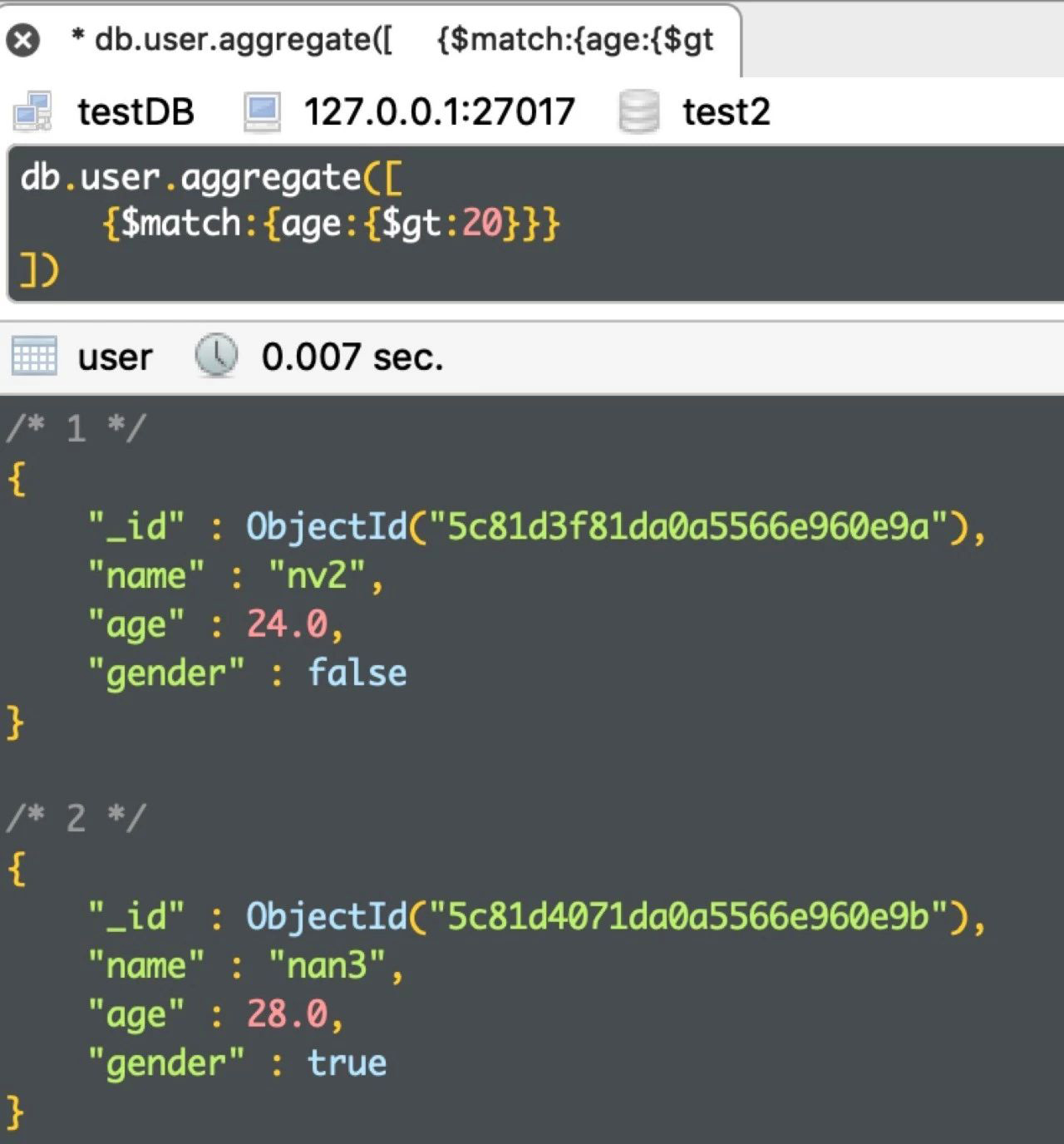
例:查询年龄大于20的人
db.user.aggregate([ {$match:{age:{$gt:20}}} ])
运行结果如下:
例:查询年龄大于20的男人、女人人数
db.user.aggregate([ {$match:{age:{$gt:20}}}, {$group:{_id:'$gender',counter:{$sum:1}}} ])
运行结果如下:

$project
修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
例:查询 user 的姓名、年龄
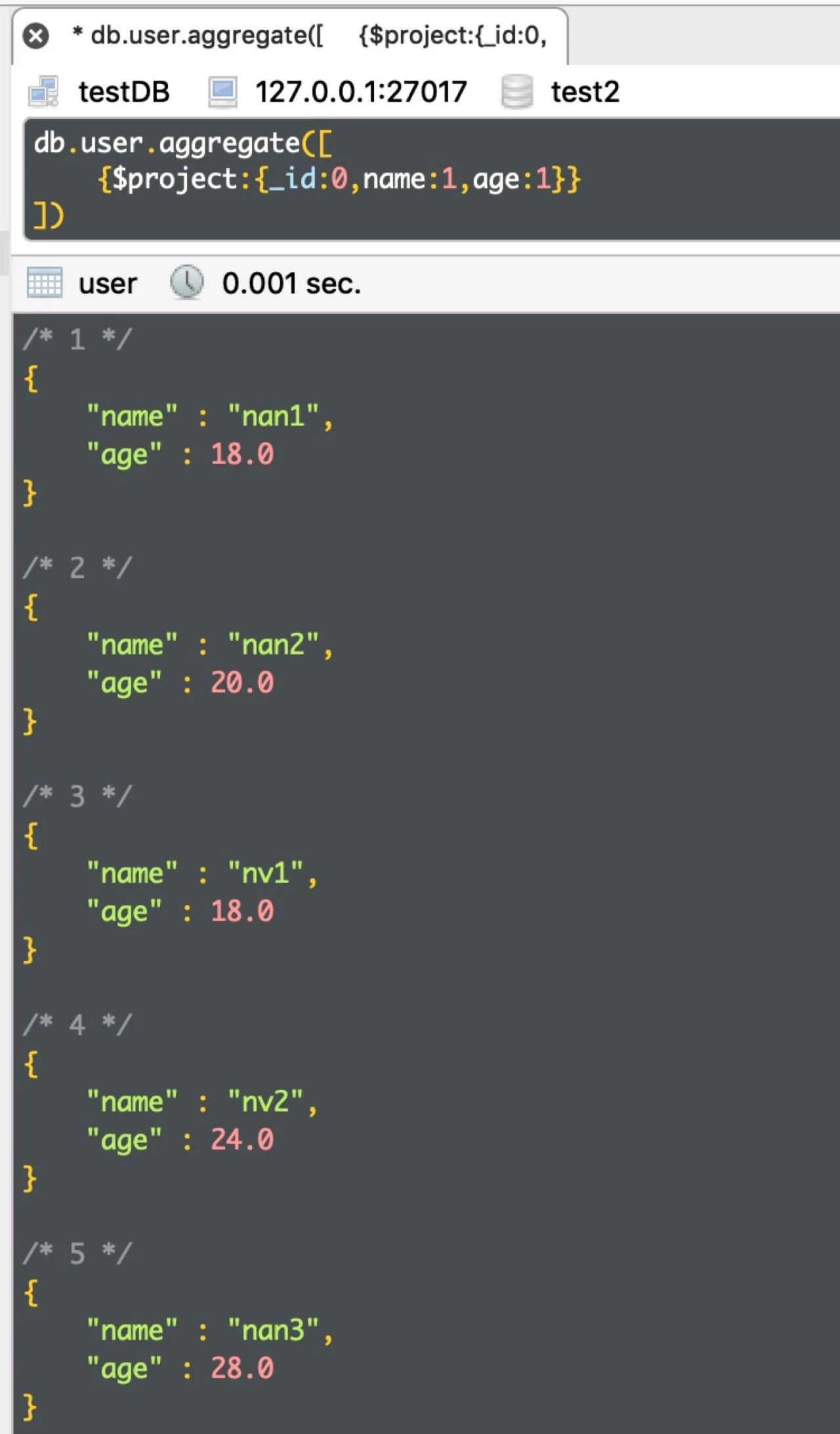
db.user.aggregate([ {$project:{_id:0,name:1,age:1}} ])
运行结果如下:
例:查询男人、女人人数,输出人数
db.user.aggregate([ {$group:{_id:'$gender',counter:{$sum:1}}}, {$project:{_id:0,counter:1}} ])
运行结果如下:

$sort
将输入文档排序后输出
例:查询 user 信息,按年龄升序
db.user.aggregate([{$sort:{age:1}}])
运行结果如下:

例:查询男人、女人人数,按人数降序
db.user.aggregate([ {$group:{_id:'$gender',counter:{$sum:1}}}, {$sort:{counter:-1}} ])
运行结果如下:

$limit
限制聚合管道返回的文档数
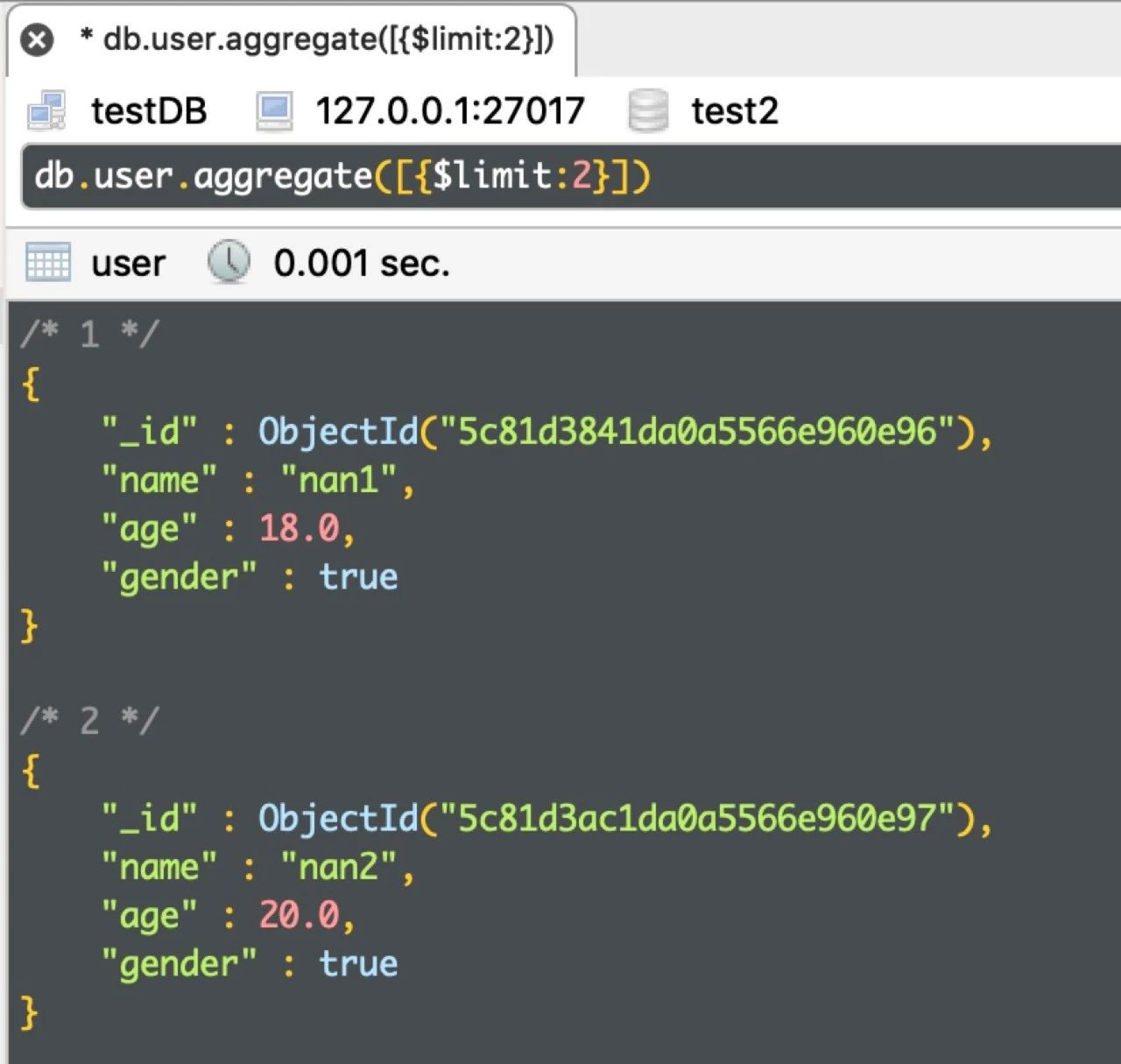
例:查询2条 user 信息
db.user.aggregate([{$limit:2}])
运行结果如下:
$skip
跳过指定数量的文档,并返回余下的文档
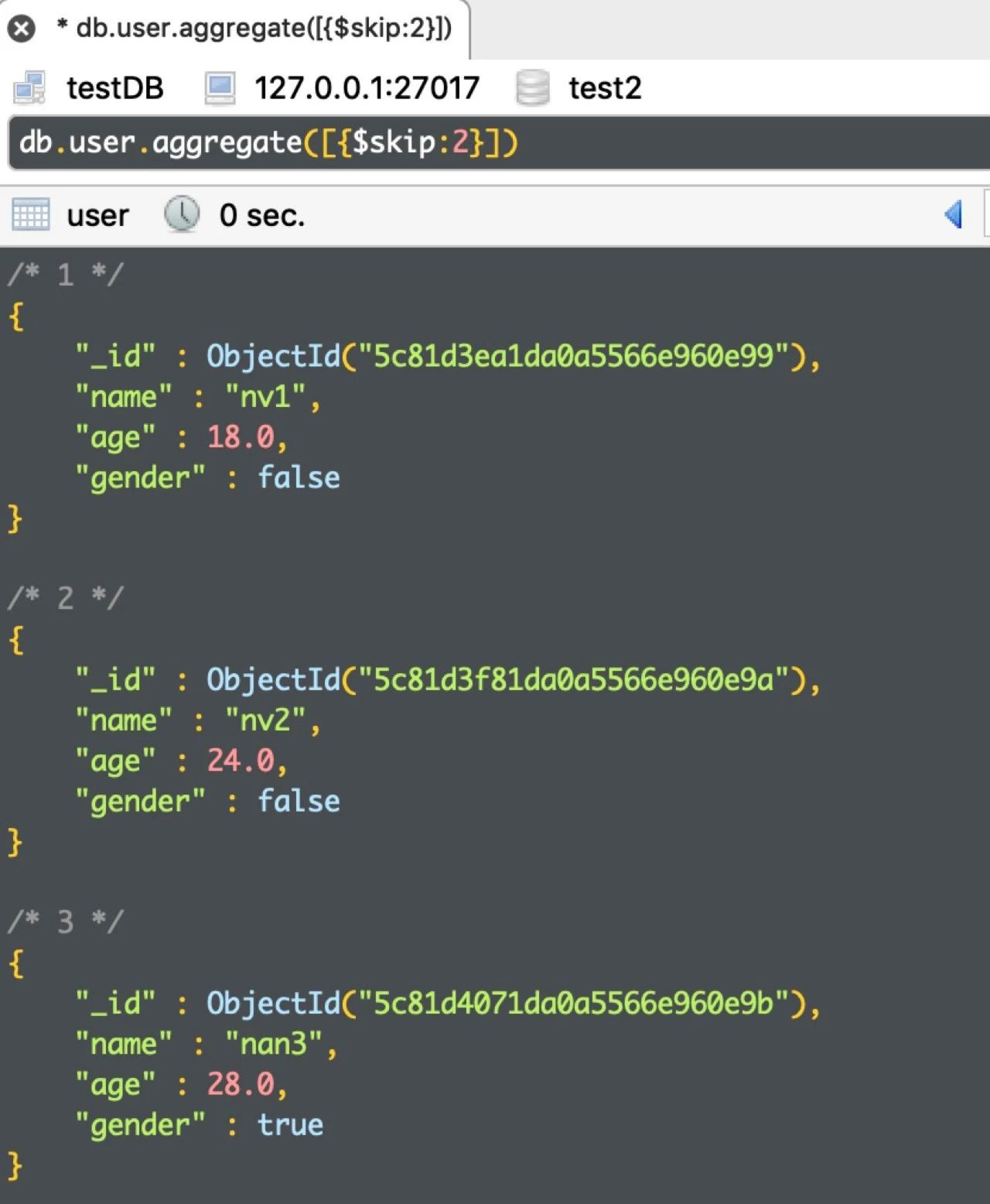
例:查询从第3条开始的 user 信息
db.user.aggregate([{$skip:2}])
运行结果如下:
例3:统计男人、女人人数,按人数升序,取第二条数据
注意顺序:先写skip,再写limit
db.user.aggregate([ {$group:{_id:'$gender',counter:{$sum:1}}}, {$sort:{counter:1}}, {$skip:1}, {$limit:1} ])
运行结果如下:

以上就是关于 MongoDB 聚合的一些操作,MongoDB 还有配置用户管理和设置数据库主从关系等操作,由于此篇幅过长,实在是写的太累了,有机会再说一下吧。
总的来说 MongoDB 在数据的操作方面语法还是很贴切我们的日常操作语法的,用起来也很方便。
好记性不如烂笔头,特此记录,与君共勉!