一、Fiddler的安装与设置
Fiddler官网:https://www.telerik.com/download/fiddler
电子邮件随便填一下就可以了,按照安装提示一直点确定即可安装。

打开Fiddler,在Tools---Options处进行设置,如图:
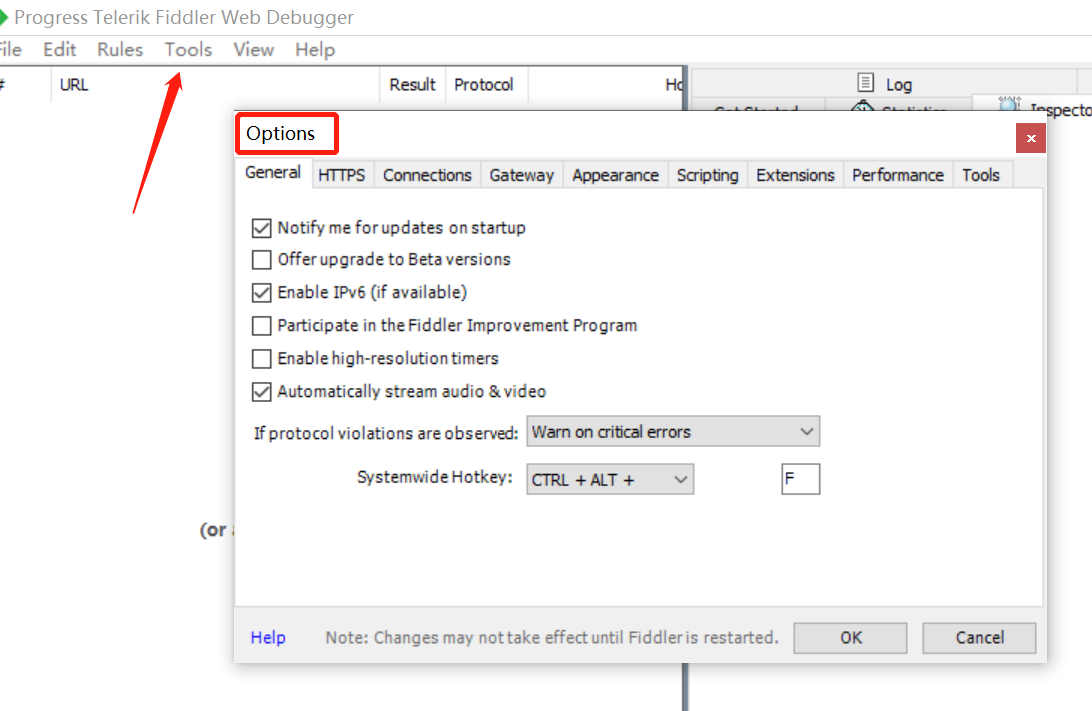
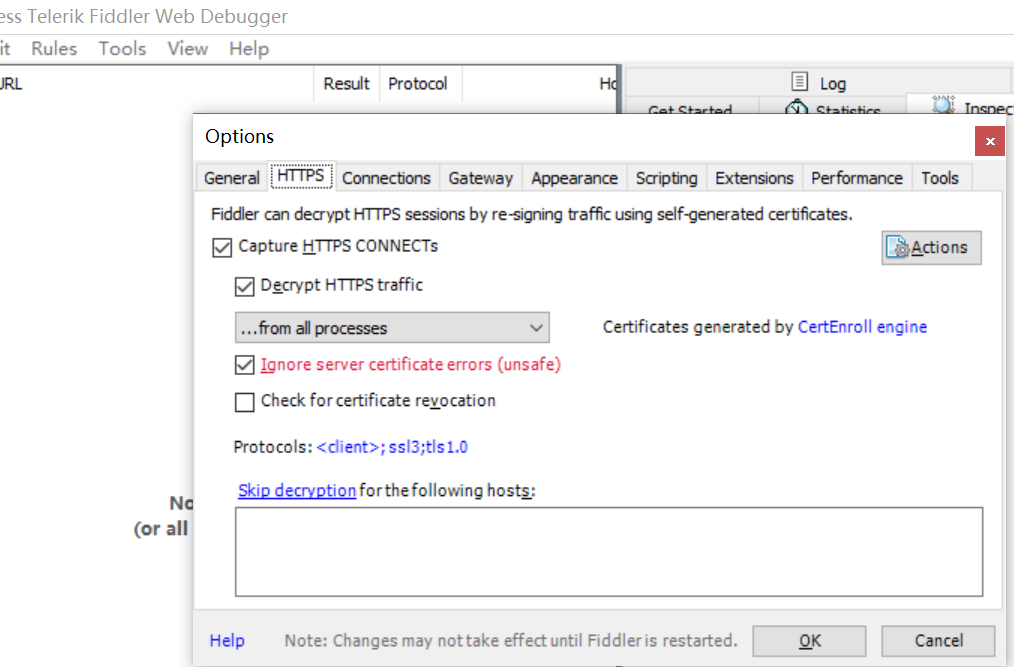
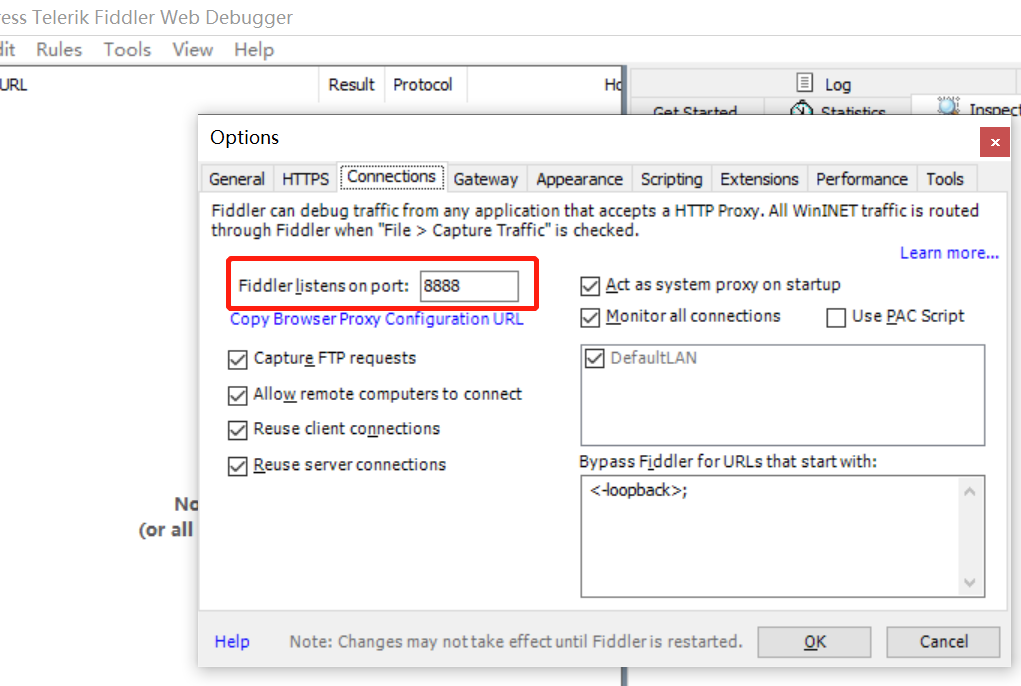
ps:这里的端口8888,是待会与手机/模拟器进行连接要使用到的(手机也可以,这里用模拟器示范)
在电脑下载一个手机模拟器,这里我用的是夜神模拟器
下载地址:https://www.yeshen.com/,下载后安装即可
打开模拟器,进入设置-----WLAN,会发现已经连上了一个网络,鼠标长按,选择修改网络
选择高级选项,代理改为手动,然后输入你电脑的ip和8888端口号保存即可

在模拟器中打开浏览器,输入:http://你的电脑ip地址:8888,如图所示,下载证书并打开安装
证书名随便取一个名字就好了,若没有安装证书,将无法抓取HTPPS请求

二、抓取抖音数据包
打开Fiddler软件,Rules------Customize Rules进入Fiddler ScriptEditor页面
定位到OnBeforeResponse函数下面,编写抓取数据的规则

1处是Fiddler中捕捉到的抖音数据包的路径,抖音官方可能时不时会更改路径,具体以实际分析为准
2处是保存地址,更改为你们自己的保存地址。代码放在下面,方便复制。
if (oSession.uriContains("https://api3-core-c-hl.amemv.com/aweme/v1/aweme/post/")){ var strBody=oSession.GetResponseBodyAsString(); var sps = oSession.PathAndQuery.slice(-58,); //FiddlerObject.alert(sps) var filename = "H:/software/fid" + "/" + sps + ".json"; var curDate = new Date(); var sw : System.IO.StreamWriter; if (System.IO.File.Exists(filename)){ sw = System.IO.File.AppendText(filename); sw.Write(strBody); } else{ sw = System.IO.File.CreateText(filename); sw.Write(strBody); } sw.Close(); sw.Dispose(); }
打开模拟器中的抖音,搜索刀某刀进入个人页面,滑动抖音,使屏幕整个浏览完全部作品
这个时候Fiddler加载出了js对象,被我们前面编写的抓取规则捕捉到,保存在本地
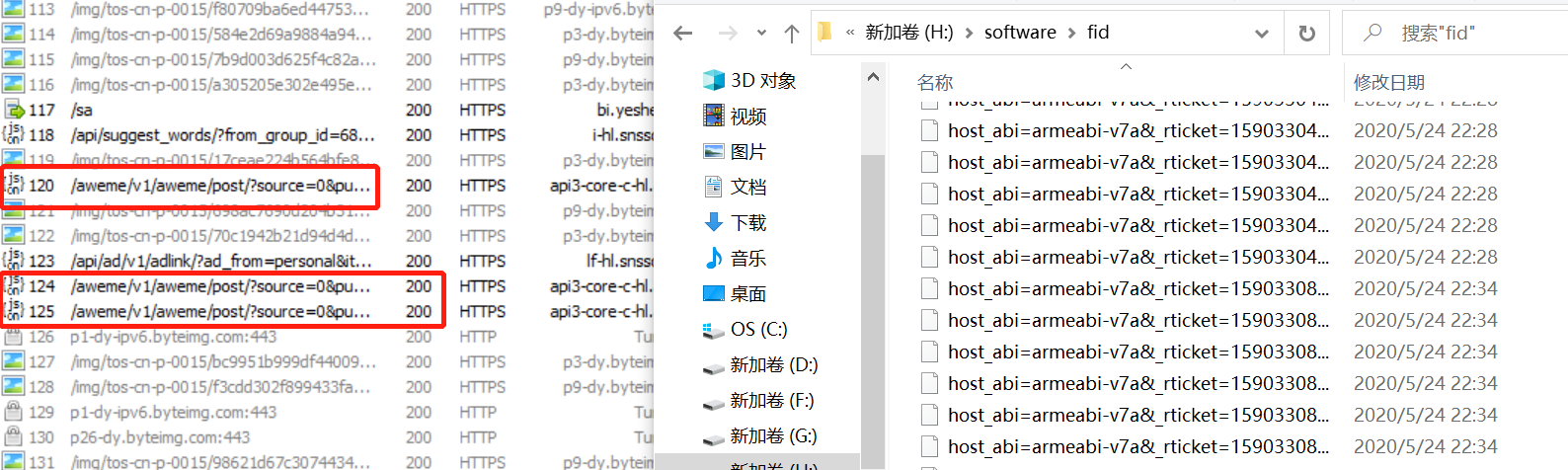
分析得到的json文件,找出视频url的位置,接下来用python代码下载视频就轻松多了
下载成功结果如图,刀某刀的个人主页视频就保存下来了,而且还是无水印视频
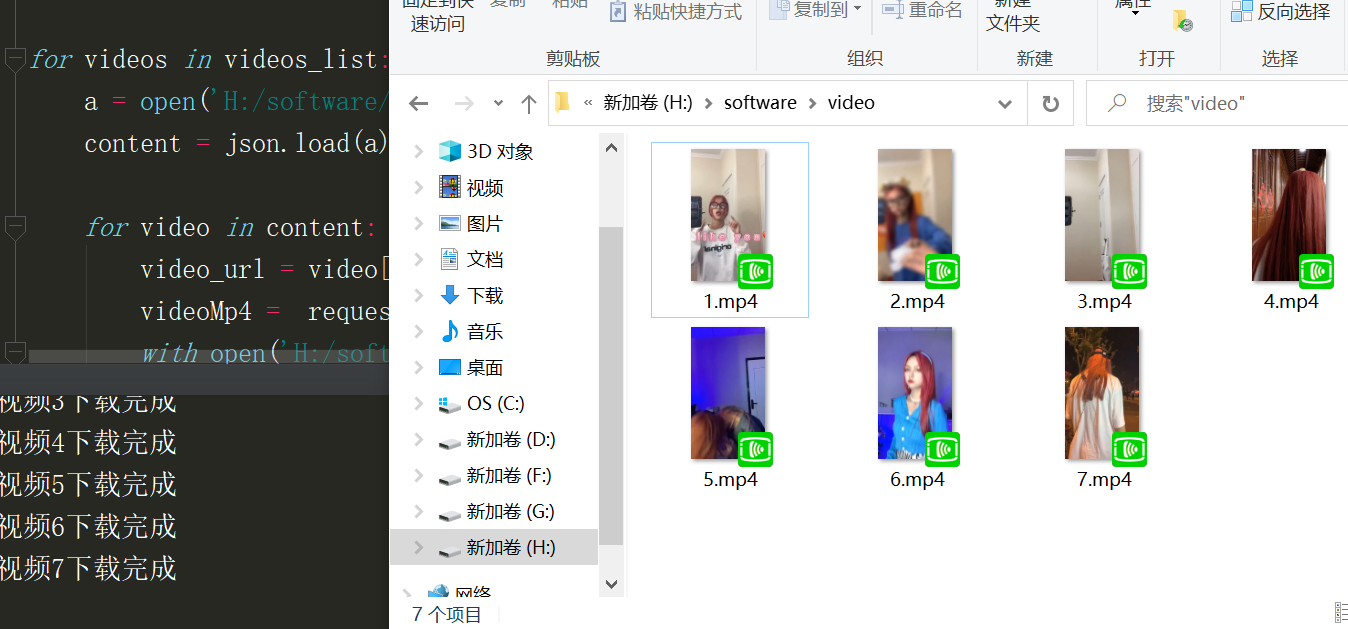
下面附上python代码,保存路径记得改为自己电脑的
import os,json,requests # 请求头 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'} videos_list = os.listdir('H:/software/fid/') #获取文件夹内所有json包名 count = 1 #计数,用来作为视频名字 for videos in videos_list: #循环json列表,对每个json包进行操作 a = open('H:/software/fid/{}'.format(videos),encoding='utf-8') #打开json包 content = json.load(a)['aweme_list'] #取出json包中所有视频 for video in content: #循环视频列表,选取每个视频 video_url = video['video']['play_addr']['url_list'][1] #获取视频url,每个视频有4个url,我选的第2个 videoMp4 = requests.get(video_url,headers=headers).content #获取视频二进制代码 with open('H:/software/video/{}.mp4'.format(count),'wb') as f: #以二进制方式写入路径,记住要先创建路径 f.write(videoMp4) #写入 print('视频{}下载完成'.format(count)) #下载提示 count += 1 #计数+1
至此,Python结合Fiddler爬取抖音视频就完成了
如有疑问,欢迎在下面评论,或者私信我