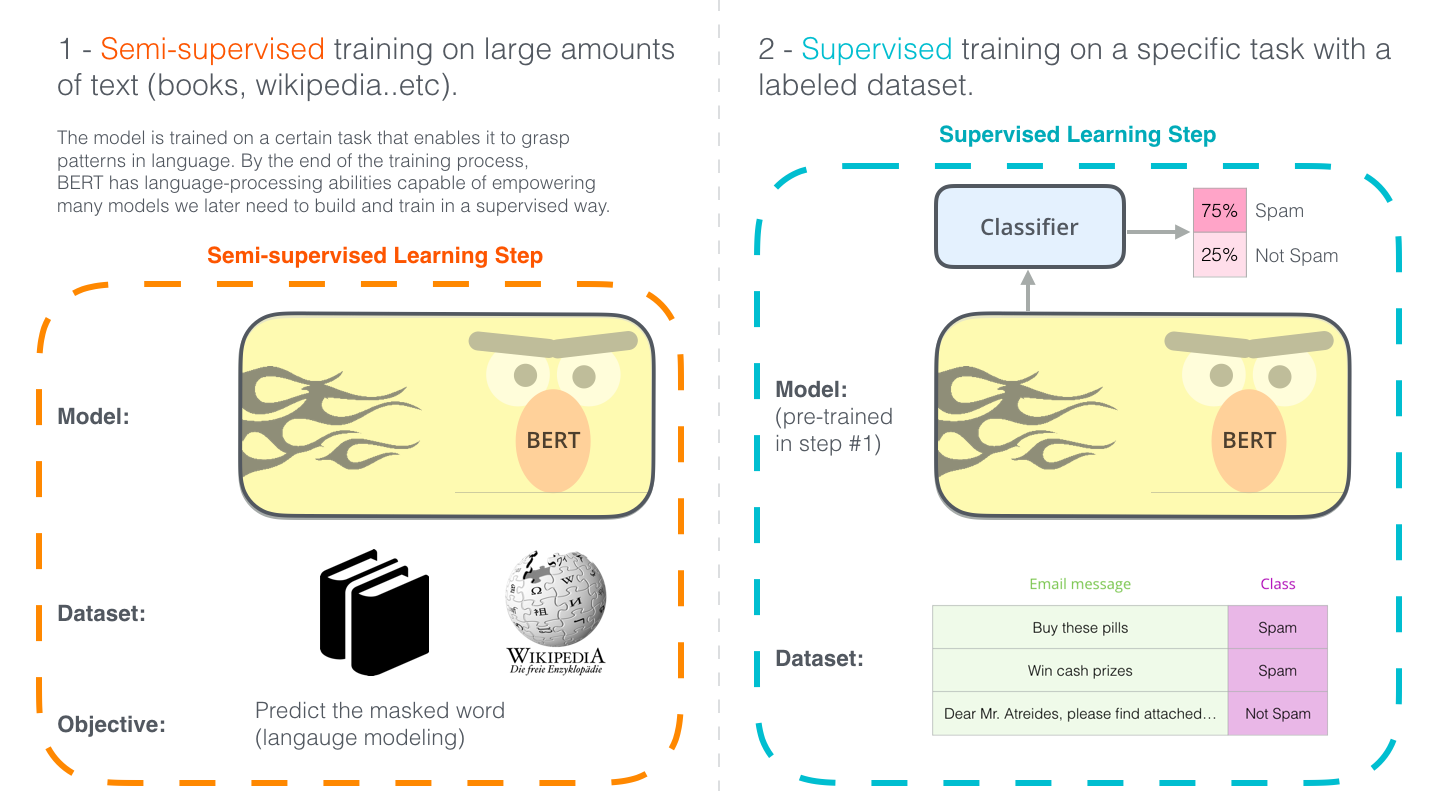
概述
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT的应用步骤
模型结构
- BERT BASE:和OPENAI Transformer大小差不多
- 12个encoder layers(Transformer Blocks)
- 768个隐藏单元的前向网络
- 12个attention heads
- BERT LARGE:State of Art
- 24个encoder layers(Transformer Blocks)
- 1024个隐藏单元的前向网络
- 16个attention heads
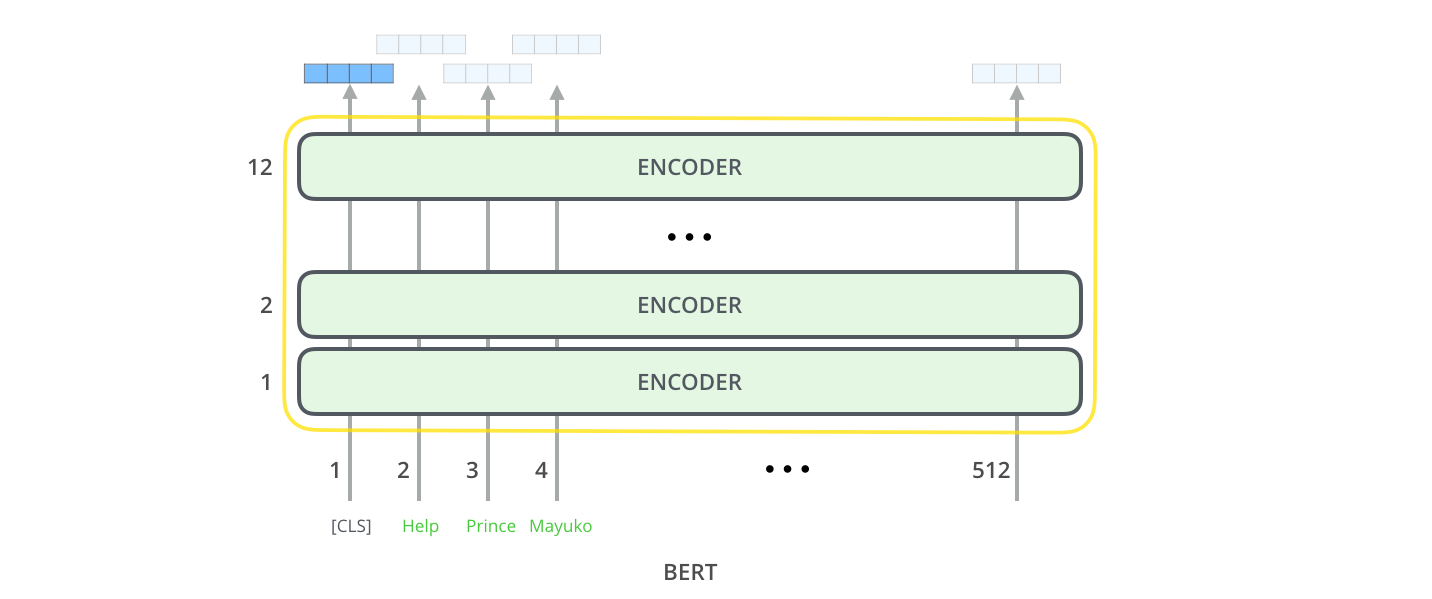
模型输入输出
Inputs
这里的Embedding由三种Embedding求和而成
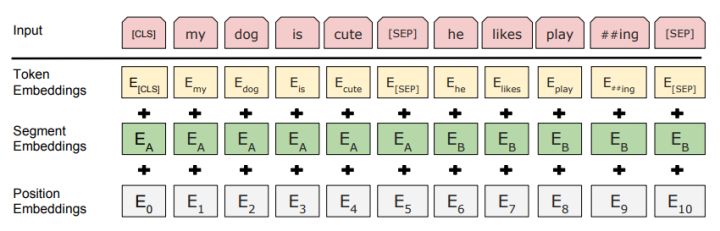
其中:
- Token Embeddings:是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings:用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings:和之前文章中的Transformer不一样,不是三角函数而是学习出来的
模型的每一层运行self-attention,然后将结果交给前向网络,再传输给下一个编码器
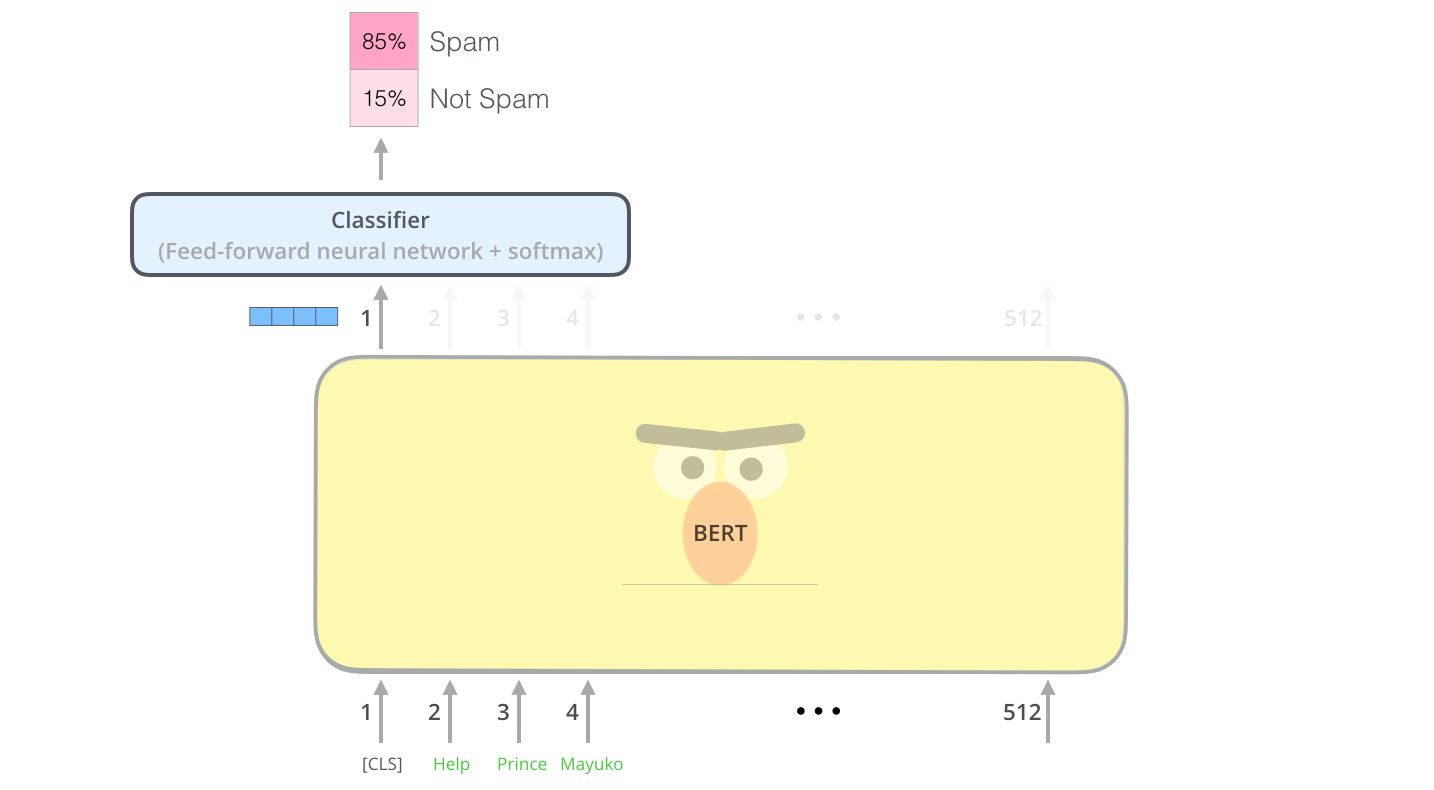
Outputs
每个位置输出一个(hidden\_size)大小的向量,对于分类任务,我们只关注第一个位置的输出([CLS]的位置)
其他方法
ElMo
在对于预训练的词向量,每个词的词向量是固定的。但是ElMo的基本思想是,对于不同的上下文,同一个词有不同的含义。因此ElMo是感知语境的词向量。
ElMo使用一个双向LSTM基于特定的任务来得到上述词嵌入。通常的做法是,在大量的数据集上训练ElMo LSTM,然后将它作为其它模型的一个组件。
ElMo是通过预测序列的下一个词进行训练的,这个任务被称为语言建模(Language Modeling),这能充分利用大量的无标注数据。而且,ElMo训练了一个双向的LSTM,因此它的语言模型不仅能感知下一个词,也能感知上一个词。最终的上下文感知词嵌入是通过将隐藏状态加权求和而来的。如下图所示:

ULM-FiT
介绍了在各种任务上进行fine-tune的语言模型和流程,不仅仅是词向量和上下文感知的嵌入。
OpenAI Transformer
OpenAI Transformer只考虑了Transformer的decoder部分,叠加了12层的decoder层。
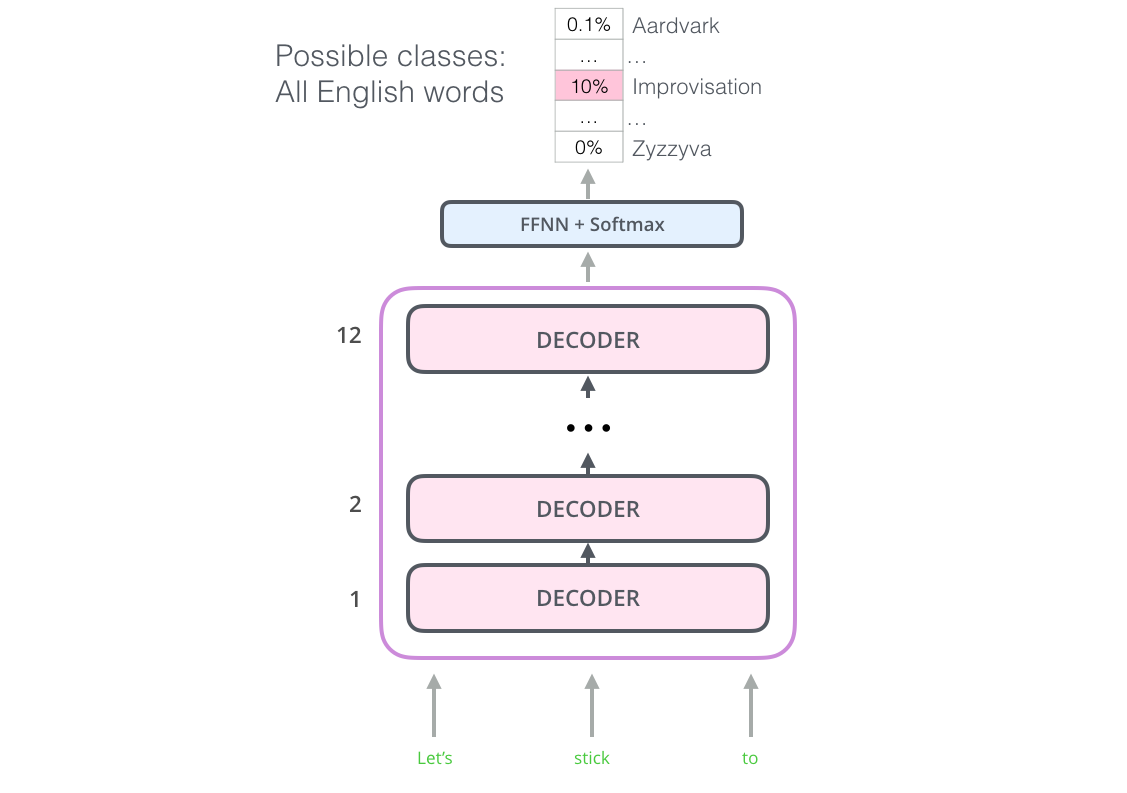
在预训练之后,OpenAI Transformer就能够用于夏有任务的迁移学习,对于不同任务的不同输入,OpenAI模型拥有不同的输入,下图是不同的任务:
几种模型的比较
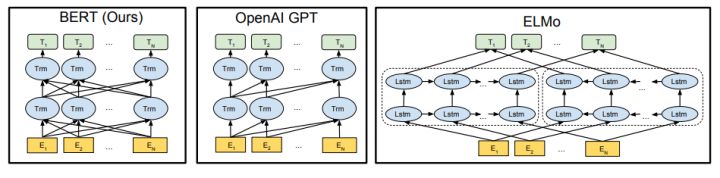
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ElMo,虽然都是“双向”,但目标函数其实是不同的。ElMo是分别以(P(w_i| w_1,cdots w_{i-1}))和(P(w_i|w_{i+1}, cdots w_n))作为目标函数,独立训练处两个representation然后拼接,而BERT则是以(P(w_i|w_1, cdots ,w_{i-1}, w_{i+1},cdots,w_n))作为目标函数训练语言模型
BERT: From Decoders to Encoders
OpenAI虽然基于Transformer给出了一个可以fine-tune的预训练模型,但是因为没有使用LSTM,丢失了部分信息(比如双向信息)。而ElMO利用双向LSTM,但是很复杂。因此BERT的想法就是,既基于Transformer模型,又能在语言模型中捕捉到前向和后向的信息。
Task 1: Masked Language Model
第一步预训练的目标就是做语言模型,从上文模型结构中看到了这个模型的不同,即bidirectional。关于为什么要如此的bidirectional,作者在reddit上做了解释,意思就是如果使用预训练模型处理其他任务,那人们想要的肯定不止某个词左边的信息,而是左右两边的信息。而考虑到这点的模型ELMo只是将left-to-right和right-to-left分别训练拼接起来。直觉上来讲我们其实想要一个deeply bidirectional的模型,但是普通的LM又无法做到。
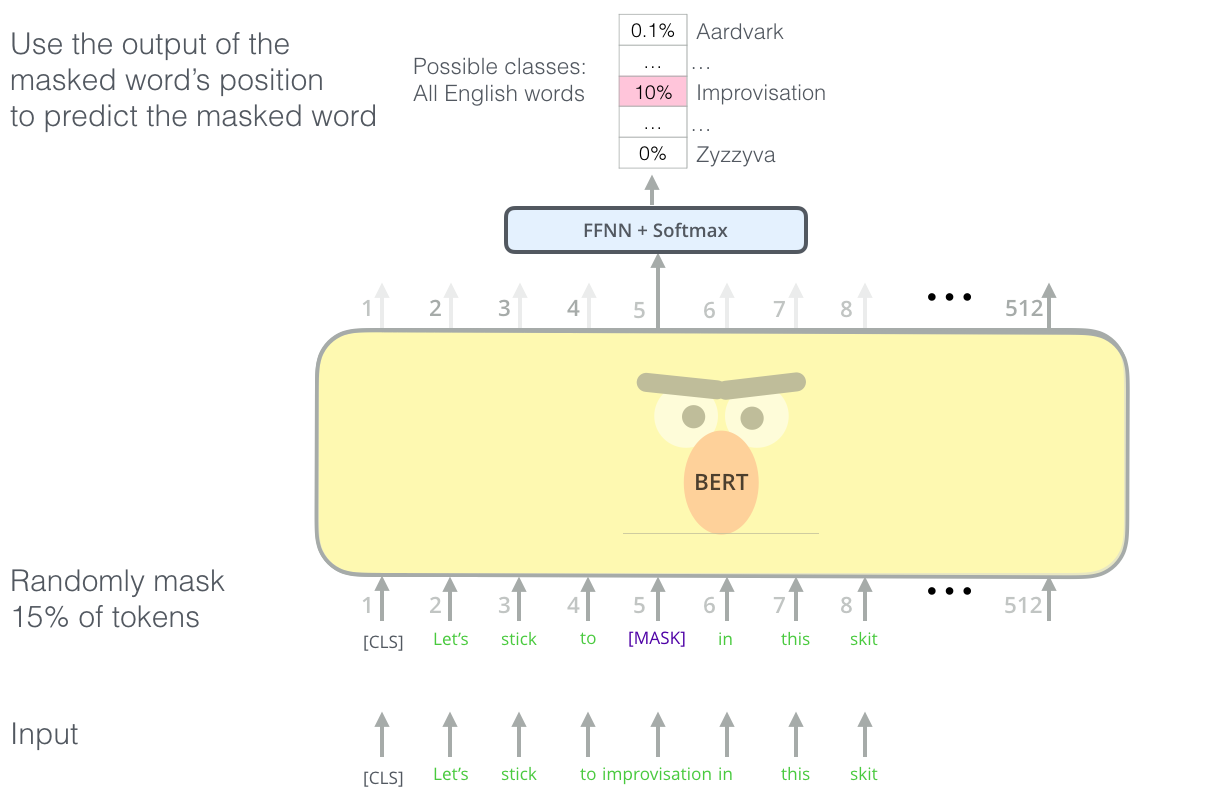
在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token
Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。具体为什么这么分配,作者没有说。要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
Task 2: Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。

注意,作者特意说了语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。
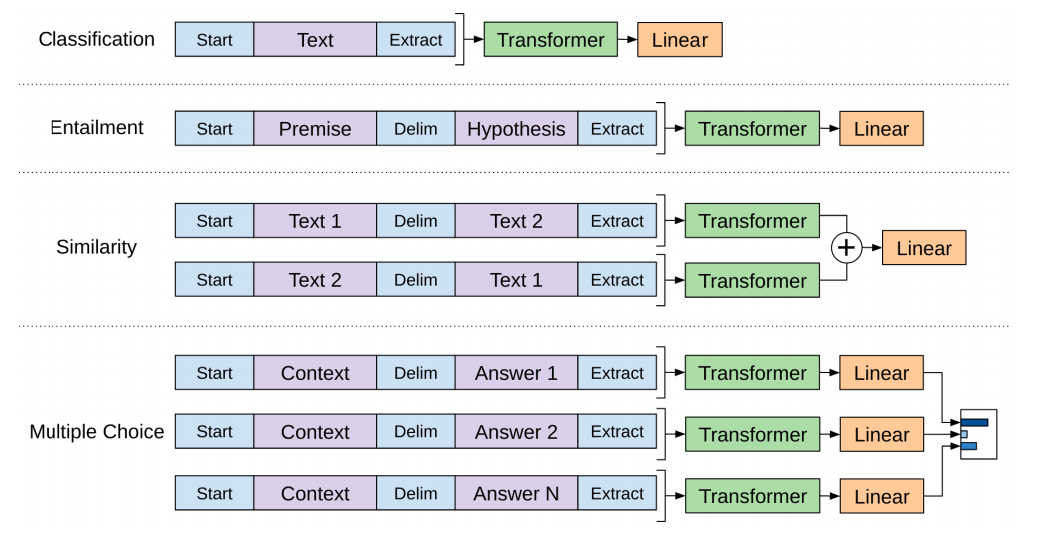
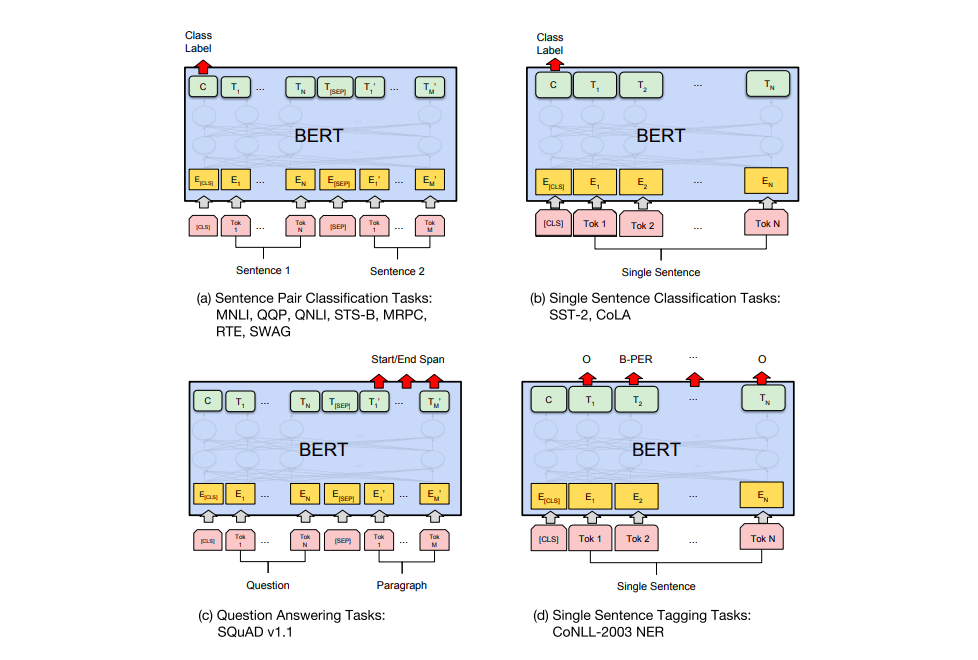
Task specific-Models
对于不同的任务,BERT模型结构的使用有不同的方式,如下图所示:
BERT for feature extraction
fine-tuning不是利用BERT的唯一方式。和ElMo一样,也可以使用BERT创建上下文感知的词向量,然后将这些向量feed到现有模型中使用。

究竟该用哪个向量作为上下文感知的嵌入,这应该取决于具体的任务。比如说高层特征和低层特征的区别。