近期师兄发给我一个压缩包让我整理文献,而我发现压缩包里的内容是这样:

这样:
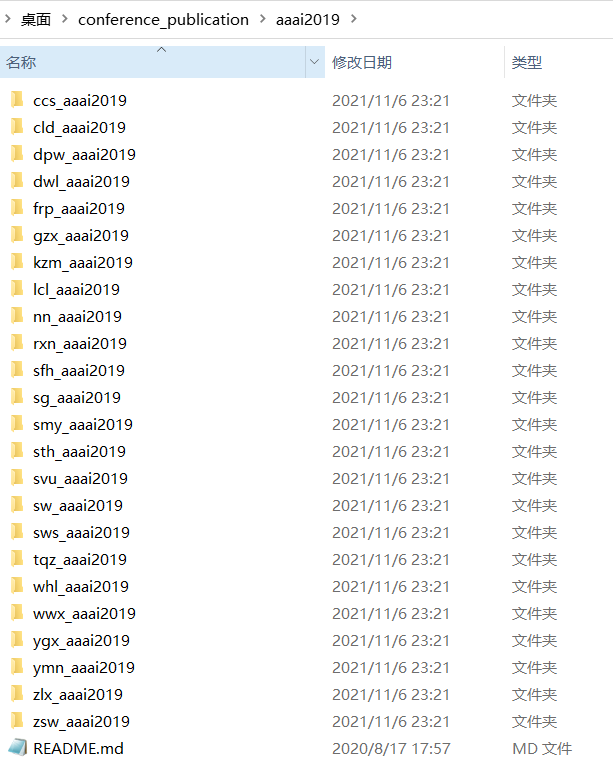
和这样的:


我大概看了一下,可能有270多篇文章是这种格式,俗话说的好,没有困难的工作,只有勇敢的研究僧。所以决定用Python自己写一个脚本。
尽管这个程序还有许多不足之处:
1)在部分网站对于文件很大的时候,可能会只下载一个18kb左右的无法打开文件;
2)程序运行时可能会出现网络或者文件异常,没有对异常进行处理;
3)因为md文件里面的pdf文章地址,有的打开是网站、有的打开可以直接下载,有的打开是pdf文件......,所以还需要人工去分一下哪一类域名下的网址可以直接下载或是pdf文件,一共可能也就20种以内,打印一下选几个关键词判断一下就行。
这个程序的主要思想:
1)利用Python对文件夹和文件进行遍历;
2)读取md文件内容并且根据# 标识识别文章标题,利用“pdf”和正则表达式识别出pdf下载的地址;
3)使用urllib库的urlretrieve对指定网址的资源文件进行下载到指定文件夹。
结果:实现260+篇文章的自动下载,并将无法下载的文章名和网址保存在相关的文件内。最后希望能够对你产生帮助,如果有帮助可以点个赞。
具体如下:
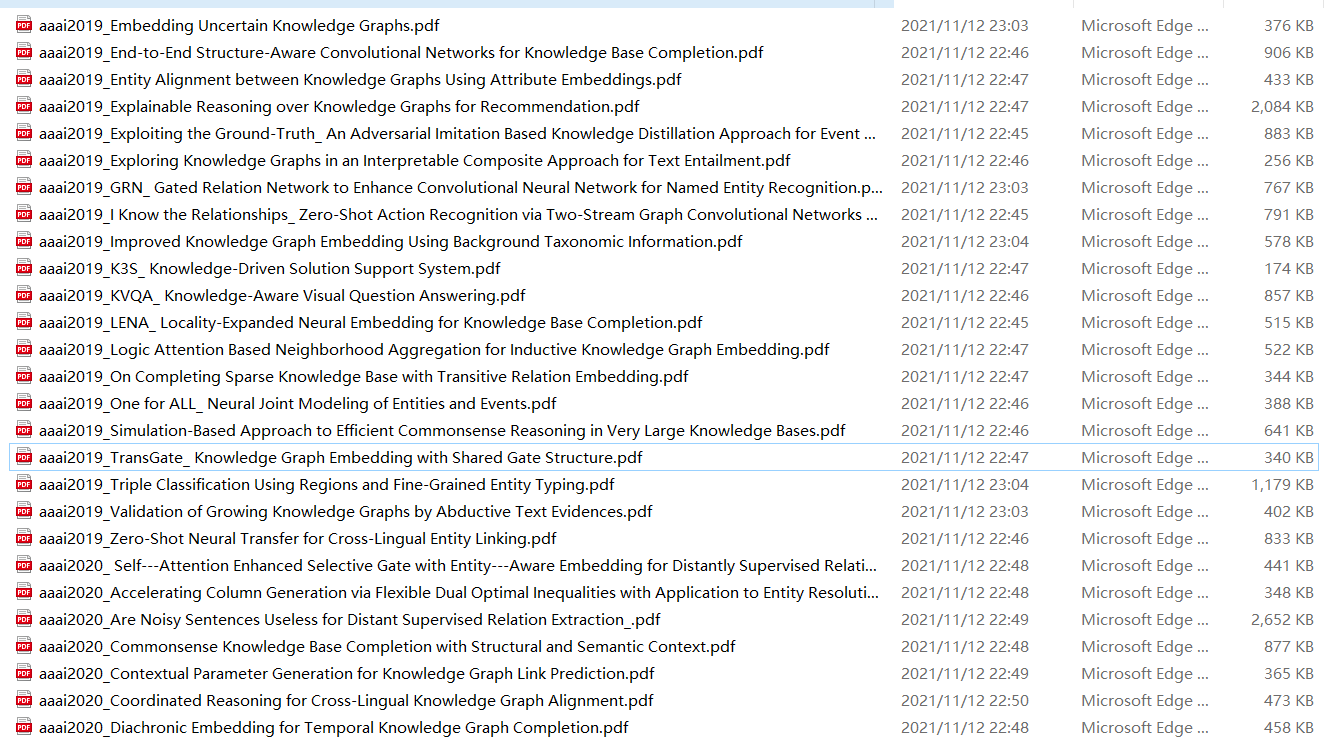

代码如下:
import os import re from urllib.request import urlretrieve import ssl from urllib import request opener = request.build_opener() opener.addheaders = ([('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36')]) request.install_opener(opener) # 关闭证书验证,方便下载 ssl._create_default_https_context = ssl._create_unverified_context # md根路径 ori_path=r'D:\conference_publication' pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') # 网页地址匹配模式 listdir=os.listdir(ori_path) # print(listdir) # 文章名和网页地址 paper_title='' pdf_path='' # 文献保存路径 save_dir=r'D:\conference paper' # 可访问的地址 # aclweb可以在手机热点访问 access_strings=['aaai.org','dl.acm.org','playbiqdata','pasinit','platanios','muhaochen.github.io','aclweb.org', 'arxiv.org','openreview.net','proceedings.mlr.press','semantic-web-journal.net','aidanhogan.com'] # 保存下载失败的地址 fail_file=os.path.join(save_dir,'fail_down.txt') for son_path in listdir: # 遍历每个会议文件夹 new_dir=os.path.join(ori_path,son_path) # 生成会议文件夹路径 # print('会议文件夹路径:',new_dir) son_listdir=os.listdir(os.path.join(ori_path,son_path)) # 会议文件夹下文章文件夹数组 # print('会议文章:',son_listdir) for new_son_path in son_listdir: # 遍历 每个会议文件夹下,每个文章文件夹 if new_son_path != 'README.md': # 不访问会议文件夹下的README.md文件 file_dir = os.path.join(new_dir, new_son_path) # 生成文章文件夹路径 print('文章文件夹路径:',file_dir) file_name=os.listdir(file_dir) # 获取README文件名称,发现有一些文件命名不是很统一 # print(file_name) # print(len(file_name)) # 如果不是一个文件,理论上是一个md文件 if len(file_name)>1: print('该文件夹下不止一个文件?',file_dir) # 如果文件夹下没有md文件 if len(file_name)==0: print('该文件夹下没有文件:',file_dir) continue md_file = os.path.join(file_dir, file_name[0]) # print('文章README文件路径:',md_file) f=open(md_file,encoding='utf-8') for line in f: # print(line) if '# ' in line: paper_title=line[2:] print('Paper Title: ',paper_title) # 打印一下文章名 if '**pdf**' in line: url = re.findall(pattern, line) if url[0][-1]=='f': pdf_path=url[0] else: pdf_path=url[0][:-1] print('PDF DownPath: ',pdf_path) # 匹配到的第一个字符串,去除最后面的 ) exist=False for sub_string in access_strings: if sub_string in pdf_path: exist=True if 'ijcai.org' in pdf_path and 'pdf' in pdf_path: exist=True if 'ijcai.org' in pdf_path and 'pdf' not in pdf_path: exist=True tail_str=pdf_path[-3:] pdf_path=pdf_path[:-3]+'0'+tail_str+'.pdf' print('ijcai not pdf new path: ',pdf_path) if exist==True: paper_title=paper_title.rstrip() paper_title=paper_title.replace('\n','') paper_title=paper_title.replace(':','_').replace('?','_').replace('!','_').replace('/','_') save_file_path=save_dir+'\\'+str(son_path)+'_'+paper_title+'.pdf' # 判断文件是否存在: if os.path.exists(save_file_path) == True: print('已存在') continue request.urlretrieve(pdf_path,save_file_path) # 请求下载 else: print('下载失败...') print(paper_title,' ',pdf_path) print(exist) failop = open(fail_file, 'a', encoding='utf-8') failop.write(paper_title.replace('\n','')) failop.write('\n') failop.write(pdf_path) failop.write('\n') failop.write('\n') failop.close() f.close()