5.1 Cost Function
假设训练样本为:{(x1),y(1)),(x(2),y(2)),...(x(m),y(m))}
L = total no.of layers in network
sL= no,of units(not counting bias unit) in layer L
K = number of output units/classes
 如图所示的神经网络,L = 4,s1 = 3,s2 = 5,s3 = 5, s4 = 4
如图所示的神经网络,L = 4,s1 = 3,s2 = 5,s3 = 5, s4 = 4
逻辑回归的代价函数:

神经网络的代价函数:
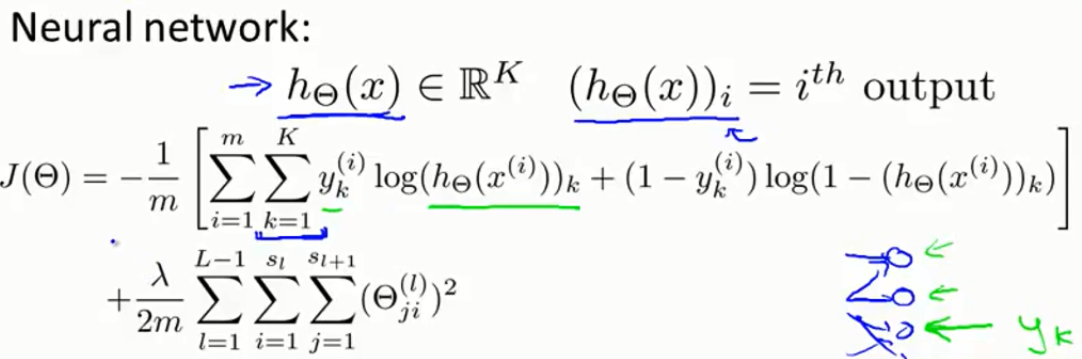
5.2 反向传播算法 Backpropagation
关于反向传播算法的一篇通俗的解释http://blog.csdn.net/shijing_0214/article/details/51923547


5.3 Training a neural network

隐藏层的单元数一般一样,隐藏层一般越多越好,但计算量会较大。
Training a Neural Network
- Randomly initialize the weights
- Implement forward propagation to get hΘ(x(i)) for any x(i)
- Implement the cost function
- Implement backpropagation to compute partial derivatives
- Use gradient checking to confirm that your backpropagation works. Then disable gradient checking.
- Use gradient descent or a built-in optimization function to minimize the cost function with the weights in theta.