聚类
数学知识基础
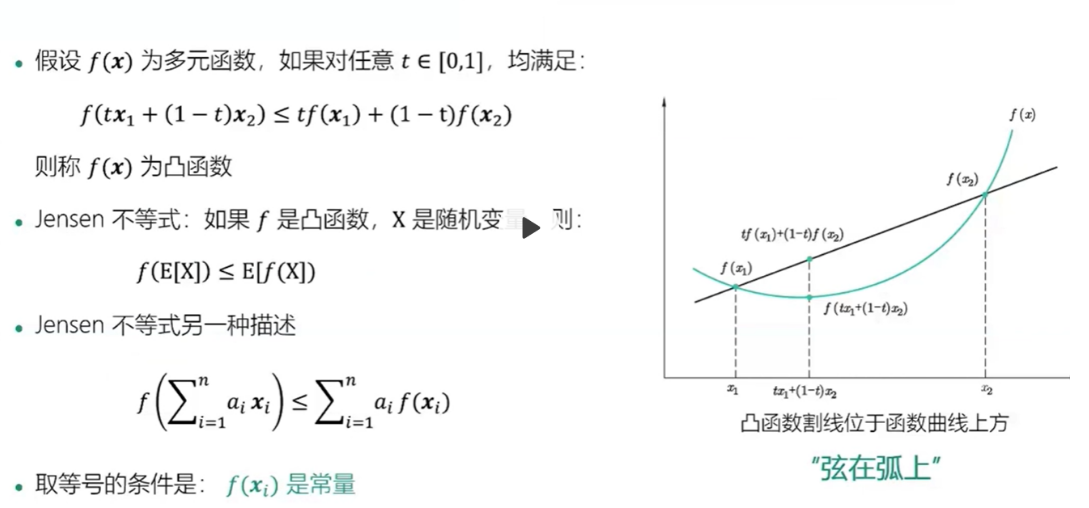
- 凸函数 和 Jensn不等式
聚类
-
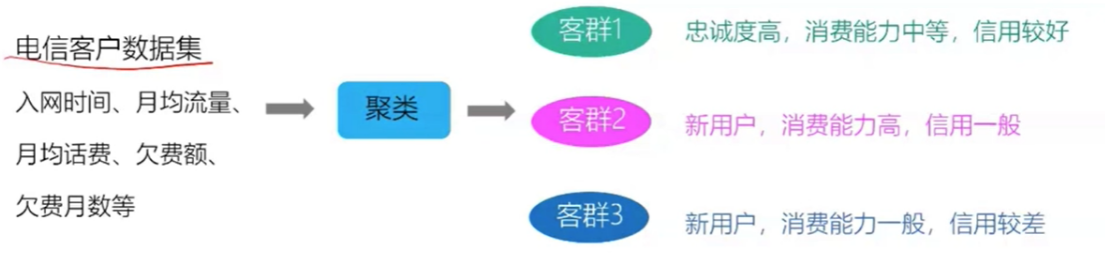
聚类的本质:将数据集中相似的样本进行分组的过程。
-
每个组称为一个簇(cluster),每个簇的样本对应一个潜在的类别
-
样本没有类别标签,因此是聚类一种典型的无监督学习方法
-
这些族满足以下两个条件:
- 相同簇的样本之间距离较近
- 不同簇的样本之间距离较远
-
聚类方法:层次聚类,K-Means,谱聚类等
K-Means模型

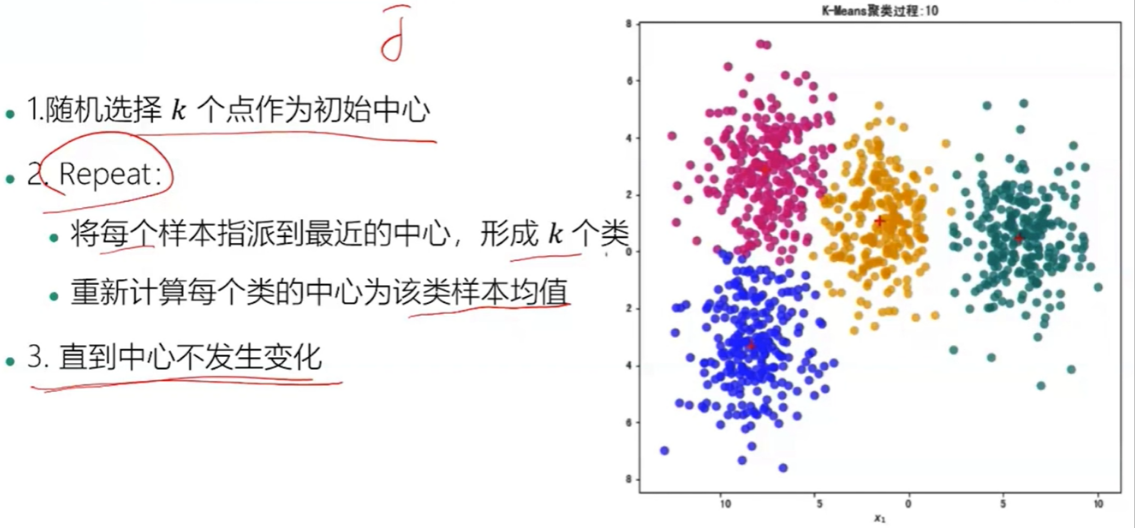
- 算法流程
高斯混合模型(GMM)

K-Means算法实现
使用iterrows遍历实现K-Means算法
#使用iterrows遍历实现K-Means算法
##计算一个样本到中心的距离
import numpy as np
def point_dist(x,c): #定义距离计算函数
return np.linalg.norm(x-c)
##使用iterrows方法遍历样本计算样本到中心的距离,定义一个函数方法实现K-Means算法
def k_means1(X,k):
centers = X.sample(k).values #从数据集随机选择 K 个样本作为初始化的类中心,k 行 d 列
X_labels = np.zeros(len(X)) #样本的类别
error = 10e10
while(error > 1e-6):
for i,x in X.iterrows():#指派样本类标签
X_labels[i] = np.argmin([point_dist(x,centers[i,:]) for i in range(k)])
centers_pre = centers
centers = X.groupby(X_labels).mean().values #更新样本均值,即类中心
error = np.linalg.norm(centers_pre - centers)#计算error
return X_labels, centers
##使用sklearn.datasets.make_blobs获取一个用于测试聚类算法的随机数据集
from sklearn import datasets
import pandas as pd
X, y = datasets.make_blobs(n_samples=5000, n_features=8, cluster_std = 0.5,centers=3,random_state=99)
X_df = pd.DataFrame(X)
##在该数据集上使用定义好的函数方法运行K-Means聚类,用%time记录运行时间
%time labels,centers = k_means1(X_df,3) # for 循环
使用apply遍历实现K-Means算法
#使用apply遍历实现K-Means算法
def k_means2(X,k):
#初始化 K 个中心,从原始数据中选择样本
centers = X.sample(k).values
X_labels = np.zeros(len(X)) #样本的类别
error = 10e10
while(error > 1e-6):
#********#
X_labels = X.apply(lambda r : np.argmin([point_dist(r,centers[i,:]) for i in range(k)]),axis=1)
centers_pre = centers
centers = X.groupby(X_labels).mean().values #更新样本均值,即类中心
error = np.linalg.norm(centers_pre - centers)#计算error
return X_labels, centers
%time labels,centers = k_means2(X_df,3) # apply 运算
使用矩阵运算方式实现K-Means算法
#使用矩阵运算方式实现K-Means算法
import pandas as pd
import numpy as np
def k_means(X,k):
C = X.sample(k).values #从数据集随机选择 K 个样本作为初始化的类中心,k 行 d 列
X_labels = np.zeros(len(X)) #记录样本的类别
error = 10e10 #停止迭代的阈值
while(error > 1e-6):
D = np.zeros((len(X),k)) #样本到每一个中心的距离,n 行 k 列
for i in range(k):
D[:,i] = np.sqrt(np.sum(np.square(X - C[i,:]),axis=1))
#使用argmin方法将其指派到最近的类
labels = np.argmin(D,axis=1)
C_pre = C
temp_C = X.groupby(labels).mean() #更新样本均值,即类中心
C = np.zeros((k,X.shape[1]))
for i in temp_C.index:
C[i,:] = temp_C.loc[i,:].values
if C.shape == C_pre.shape:
error = np.linalg.norm(C_pre - C)#计算error
else:
print(C.shape, C_pre.shape)
return labels, C
%time labels,centers = k_means(X_df,3) # 矩阵运算
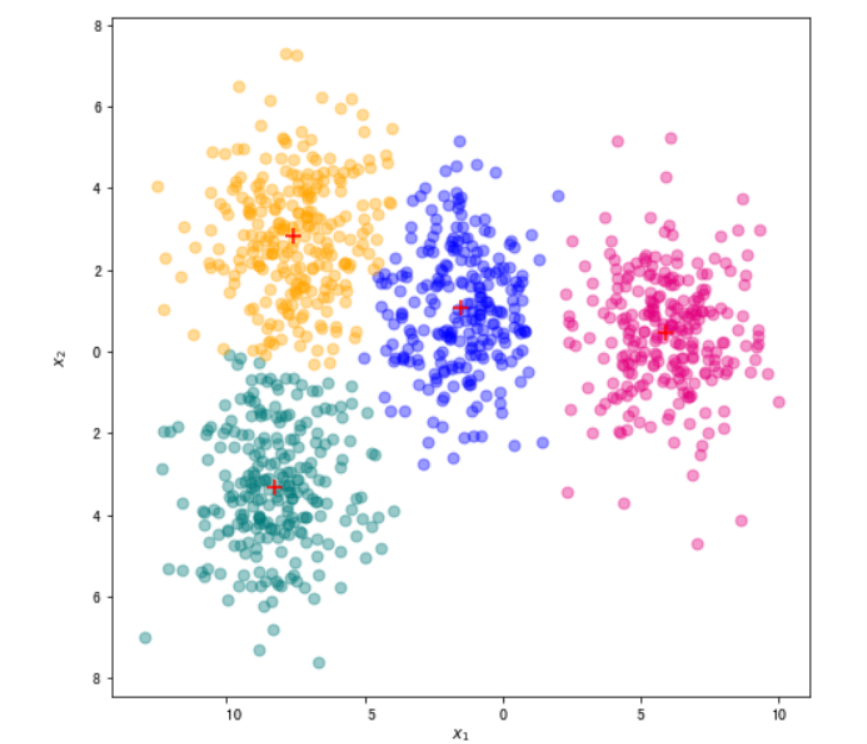
聚类结果可视化
#可视化
##设置颜色
color_dict = {0:"#E4007F",1:"#007979",2:"blue",3:"orange"} #洋红,深绿,蓝色,橘色
##再次使用make_blobs随机生成二维数据集
from sklearn import datasets
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
X, y = datasets.make_blobs(n_samples=1000, n_features=2, cluster_std = 1.5,centers=4,random_state=999)
X_df = pd.DataFrame(X,columns=["x1","x2"])
labels,centers= k_means(X_df,4)
fig, ax = plt.subplots(figsize=(8, 8)) #设置图片大小
for i in range(len(centers)):
ax.scatter(X_df[labels == i]["x1"],X_df[labels == i]["x2"],color=color_dict[i],s=50,alpha=0.4)
ax.scatter(centers[int(i),0],centers[int(i),1],color="r",s=100,marker="+")
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
K-Means实现图像分割
#加载一张测试图片,使用PIL.Image.Open打开图片,使用matplotlib.imshow将图片可视化
from PIL import Image
fig, ax = plt.subplots(figsize=(6, 5)) #设置图片大小
path = './input/timg.jpg'
img = Image.open(path)
plt.imshow(img)
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴

#将该图片转换成表格形式
import pandas as pd
def image_dataframe(image): #将图片转换成DataFrame,每个像素对应每一行,每一行包括三列
rbg_values = []
for i in range(image.size[0]):
for j in range(image.size[1]):
x,y,z= image.getpixel((i,j)) # 获取图片的每一个像素 (i,j)(i,j) 的 RBG 值
rbg_values.append([x,y,z])
return pd.DataFrame(rbg_values,columns=["R","B","G"]),img.size[0],img.size[1]
img_df,m,n = image_dataframe(img)
#输出
#img_df.head()
#使用K-Means算法进行聚类,2表示0,1标签
labels, _ = k_means(img_df,2)
#将生成的灰度图可视化
fig, ax = plt.subplots(figsize=(6, 5)) #设置图片大小
labels = labels.reshape((m,n))
pic_new = Image.new("L",(m,n))
#根据类别向图片中添加灰度值
for i in range(m):
for j in range(n):
pic_new.putpixel((i,j),int(256/(labels[i][j] + 1)))
plt.imshow(pic_new)
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴

#将像素聚类类别标签,转换成一张灰度图
def img_from_labels(labels,m,n):
labels = labels.reshape((m,n))
pic_new = Image.new("L",(m,n))
#根据类别向图片中添加灰度值
for i in range(m):
for j in range(n):
pic_new.putpixel((i,j),int(256/(labels[i][j] + 1)))
return pic_new
#不同聚类数量k展示的效果不同
fig, ax = plt.subplots(figsize=(18, 10)) #设置图片大小
img = Image.open(path) #显示原图
plt.subplot(2,3,1)
plt.title("原图")
plt.imshow(img)
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
for i in range(2,7):
plt.subplot(2,3,i)
plt.title("k=" + str(i))
labels, _ = k_means(img_df,i)
pic_new = img_from_labels(labels,m,n)
plt.imshow(pic_new)
plt.box(False) #去掉边框
plt.axis("off")#不显示坐标轴
