李航《统计学习方法》第一章阅读笔记
1* 监督学习
监督学习是从标注数据中学习模型的机器学习问题
1.1统计学习
统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。统计学习也称为统计机器学习。
统计学习的对象是 :数据。
统计学习总目标是考虑学习什么样的模型和如何学习模型,以使模型能对数据进行准确的预测与分析,同事也要考虑尽可能地提高学习效率。
1.2统计学习方法分类
统计学习方法的三要素:模型,策略和算法。
基本分类:监督学习、无监督学习、强化学习、半监督学习与主动学习。
监督学习的问题形式化如下图:
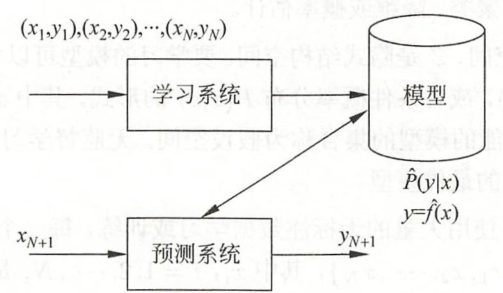
无监督学习的问题形式化如下图:

强化学习中,智能系统与环境的互动如下图:
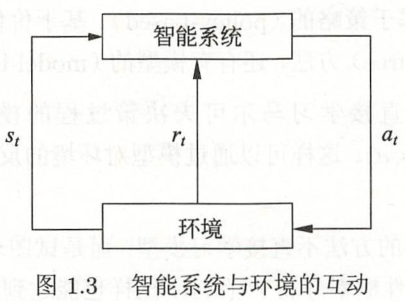
强化学习的马尔可夫决策过程是状态、奖励、动作序列上的随机过程,由五元组 <S,A,P,r,y>组成。
S是有限状态的集合。
S是有限动作的集合。
P是状态转移概率函数。
r是奖励函数。
y是衰减系数。
强化学习的目标是在所有可能的策略中选出价值函数最大的策略π*。
强化学习方法中有基于策略的、基于价值的,这两种属于无模型的方法,还有有模型的方法。
半监督学习是指利用标注数据 和未标注数据学习预测模型的机器学习问题。通常有少量标注数据、大量未标注数据,因为标注数据的构建往往需要人工,成本较高,未标注数据的手机不需太多成本。半监督学习旨在利用未标注数据中的信息,辅助标注数据,进行监督学习,以较低的成本达到较好的学习效果。
主动学习是指机器不断主动给出实例让教师进行标注,然后利用标注数据学习预测模型的机器学习问题。
按照模型的种类进行分类:概率模型和非概率模型(确定性模型)。
1.在监督学习中,概率模型是生成模型,非概率模型是判别模型。
概率模型有:决策树、朴素贝叶斯、隐马尔可夫模型、条件随机场、概率潜在语义分析、潜在狄利克雷分配、高斯混合模型等。
非概率模型有:感知机、支持向量机、k近邻、AdaBoost、k均值、潜在语义分析,以及神经网络等。
逻辑斯谛回归既可以看做概率模型,又可以看做非概率模型。
概率模型的代表是概率图模型,概率图模型是联合概率分布由有向图或者无向图表示的概率模型,而联合概率分布合一根据图的结构分解为因子乘积的形式。
贝叶斯网络、马尔可夫随机场、条件随机场是概率图模型。

2.线性模型和非线性模型
非概率模型,可以分为线性模型和非线性模型。
感知机、线性支持向量机、k近邻、潜在语义分析是线性模型。
核函数支持向量机、AdaBoost、神经网络是非线性模型。
深度学习是复杂的非线性模型的学习。