游双Linux高性能服务器编程第八章代码解读
功能:Http请求的读取和分析
代码模块:
代码模块一:http.c


1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <libgen.h> 5 #include <sys/types.h> 6 #include <sys/socket.h> 7 #include <netinet/in.h> 8 #include <arpa/inet.h> 9 #include <unistd.h> 10 #include <assert.h> 11 #include <errno.h> 12 13 #include "http.h" 14 15 /* 读缓冲区大小 */ 16 #define BUFSIZE 4096 17 /* 为了简化问题,我们没有给客户端发送一个完整的HTTP应答报文,而只是根据服务器的处理结果发送如下成功或失败的信息 */ 18 static const char *szret[] = {"I get a correct result\n", "Something wrong\n"}; 19 20 /* main函数 */ 21 int main(int argc, char *argv[]){ 22 if (argc < 3) { 23 fprintf(stderr, "Usage: %s <ip_address> <port_number>\n", basename(argv[0])); 24 return 1; 25 } 26 const char *ip = argv[1]; 27 int port = atoi(argv[2]); 28 struct sockaddr_in address; 29 address.sin_family = AF_INET; 30 inet_pton(AF_INET, ip, &address.sin_addr); 31 address.sin_port = htons(port); 32 33 int sock = socket(AF_INET, SOCK_STREAM, 0); 34 assert(sock >= 0); 35 36 int ret = bind(sock, (struct sockaddr *)&address, sizeof(address)); 37 assert(ret != -1); 38 39 ret = listen(sock, 5); 40 assert(ret != -1); 41 42 struct sockaddr_in client; 43 socklen_t client_addrlength = sizeof(client); 44 int connfd = accept(sock, (struct sockaddr *)&client, &client_addrlength); 45 if (connfd < 0) { 46 perror("accept()"); 47 } 48 else { 49 char buffer[BUFSIZE]; /* 读缓存区,大小为4096 */ 50 memset(buffer, '\0', sizeof(char) * BUFSIZE); 51 int data_read = 0; 52 int read_index = 0; /* 当前已经读取了多少个字节的客户数据 */ 53 int checked_index = 0; /* 当前已经分析完了多少字节的客户数据 */ 54 int start_line = 0; /* 行在buffer中的起始位置 */ 55 /* 设置主状态机的初始状态 */ 56 enum CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE; 57 while (1) { /* 循环读取客户数据并分析之 */ 58 data_read = recv(connfd, buffer + read_index, BUFSIZE - read_index, 0); 59 if (data_read == -1) { 60 perror("recv()"); 61 break; 62 } else if (data_read == 0) { 63 printf("remote client has closed the connection\n"); 64 break; 65 } 66 read_index += data_read; 67 /* 分析目前已经获得的所有客户数据 */ 68 enum HTTP_CODE result = parse_content(buffer, &checked_index, &checkstate, read_index, &start_line); 69 if (result == NO_REQUEST) { /* 尚未得到一个完整的HTTP请求 */ 70 continue; 71 } else if (result == GET_REQUEST) { /* 得到一个完整的、正确的HTTP请求 */ 72 send(connfd, szret[0], strlen(szret[0]), 0); 73 break; 74 } else { /* 其他情况表示发生错误 */ 75 send(connfd, szret[1], strlen(szret[1]), 0); 76 break; 77 } 78 } 79 close(connfd); 80 } 81 close(sock); 82 return 0; 83 } 84 85 /* 分析HTTP请求的入口函数 */ 86 enum HTTP_CODE parse_content(char *buffer, int *checked_index, enum CHECK_STATE *checkedstate, int read_index, int *start_line){ 87 enum LINE_STATUS linestatus = LINE_OK; /* 记录当前行的读取状态 */ 88 enum HTTP_CODE retcode = NO_REQUEST; /* 记录HTTP请求的处理结果 */ 89 /* 主状态机,用于从buffer中取出所有完整的行 */ 90 while ((linestatus = parse_line(buffer, checked_index, read_index)) == LINE_OK) { 91 char *temp = buffer + (*start_line); /* start_line是行在buffer中的起始位置 */ 92 (*start_line) = (*checked_index); /* 记录下一行的起始位置 */ 93 switch ((*checkedstate)) { 94 case CHECK_STATE_REQUESTLINE: { /* 第一个状态,分析请求行 */ 95 retcode = parse_requestline(temp, checkedstate); 96 if (retcode == BAD_REQUEST) return BAD_REQUEST; 97 break; 98 } 99 case CHECK_STATE_HEADER: { /* 第二个状态,分析头部字段 */ 100 retcode = parse_headers(temp); 101 if (retcode == BAD_REQUEST) { 102 return BAD_REQUEST; 103 } else if (retcode == GET_REQUEST) { 104 return GET_REQUEST; 105 } 106 break; 107 } 108 default: { 109 return INTERNAL_ERROR; 110 } 111 } 112 } 113 /* 若没有读取到一个完整的行,则表示还需要继续读取客户数据才能进一步分析 */ 114 if (linestatus == LINE_OPEN) return NO_REQUEST; 115 116 return BAD_REQUEST; 117 } 118 119 /* 从状态机,用于解析出一行内容 */ 120 enum LINE_STATUS parse_line(char *buffer, int *checked_index, int read_index){ 121 char temp; 122 /* checked_index 指向buffer(应用程序的读缓冲区)中当前正在分析的字节,read_index指向buffer中客户数据的尾部的下一个字节 123 * buffer中第0~checked_index字节都已经分析完毕 124 */ 125 for (;(*checked_index) < read_index; ++(*checked_index)) { 126 /* 获取当前需要分析的字节 */ 127 temp = buffer[(*checked_index)]; 128 /* 如果当前的字节是'\r',即回车符,则说明可能读取到一个完整的行 */ 129 if (temp == '\r') { 130 /* 如果'\r'字符碰巧是目前buffer中的最后一个已经被读入的客户数据, 131 * 那么这次分析没有读取到一个完整的行,返回LINE_OPEN表示还需要继续读取客户数据才能进一步分析 132 */ 133 if ((*checked_index) + 1 == read_index) { 134 return LINE_OPEN; 135 } else if (buffer[(*checked_index) + 1] == '\n') { /* 如果下一个字符是'\n',则说明我们成功读取到了一个完整的行 */ 136 buffer[(*checked_index)++] = '\0'; 137 buffer[(*checked_index)++] = '\0'; 138 return LINE_OK; 139 } 140 /* 否则的话,说明客户发送的HTTP请求存在语法问题 */ 141 return LINE_BAD; 142 } else if (temp == '\n') { 143 /* 如果当前的字节是'\n',即换行符,则也说明可能读取到一个完整的行 */ 144 if (((*checked_index) > 1) && buffer[(*checked_index) - 1] == '\r') { 145 buffer[(*checked_index) - 1] = '\0'; 146 buffer[(*checked_index)++] = '\0'; 147 return LINE_OK; 148 } 149 return LINE_BAD; 150 } 151 } 152 return LINE_OPEN; 153 } 154 155 enum HTTP_CODE parse_requestline(char *temp, enum CHECK_STATE *checkstate){ 156 char *url = strpbrk(temp, " \t"); 157 /* 如果请求行中没有空白字符或者'\t'字符,则HTTP请求必有问题 */ 158 if (!url) { 159 return BAD_REQUEST; 160 } 161 /* 后缀++优先级更高,意味着运算符用于pt,而不是*pt,因此对指针递增 162 * 然而后缀运算符意味着将对原来的地址而不是递增后的新地址解除引用 163 */ 164 *url++ = '\0'; 165 166 char *method = temp; 167 /* strcasecmp比较时忽略大小写 */ 168 if (strcasecmp(method, "GET") == 0) { /* 仅支持GET方法 */ 169 printf("The request method is GET\n"); 170 } else { 171 return BAD_REQUEST; 172 } 173 /* strspn() 函数用来计算字符串 str 中连续有几个字符都属于字符串 accept */ 174 url += strspn(url, " \t"); 175 /* C语言strpbrk()函数:返回两个字符串中首个相同字符的位置 */ 176 char *version = strpbrk(url, " \t"); 177 if (!version) { 178 return BAD_REQUEST; 179 } 180 *version++ = '\0'; 181 version += strspn(version, " \t"); 182 /* 仅支持HTTP/1.1 */ 183 if (strcasecmp(version, "HTTP/1.1") != 0) { 184 return BAD_REQUEST; 185 } 186 /* 检查URL是否合法 187 * 例如GET https://blog.csdn.net/u010256388/article/details/68491509 HTTP/1.1 188 * 我的理解是,先去掉"http://"(如果有的话),再定位到"/u010256388/article/details/68491509" 189 */ 190 if (strncasecmp(url, "http://", 7) == 0) { 191 url += 7; 192 url = strchr(url, '/'); 193 } 194 if (!url || url[0] != '/') { 195 return BAD_REQUEST; 196 } 197 printf("The request URL is: %s\n", url); 198 /* 请求行处理完毕,状态转移到头部字段的解析 */ 199 *checkstate = CHECK_STATE_HEADER; 200 return NO_REQUEST; 201 } 202 203 /* 分析头部字段 */ 204 enum HTTP_CODE parse_headers(char *temp){ 205 /* 遇到一个空行,说明我们得到一个正确的HTTP请求 */ 206 if (temp[0] == '\0') { 207 return GET_REQUEST; 208 } else if (strncasecmp(temp, "Host:", 5) == 0) { /* 处理"HOST"头部字段 */ 209 temp += 5; 210 temp += strspn(temp, " \t"); 211 printf("The request host is: %s\n", temp); 212 } else { /* 其他头部字段都不处理 */ 213 printf("I can not handle this header\n"); 214 } 215 return NO_REQUEST; 216 }
代码模块二:http.h
#ifndef HTTP_H__ #define HTTP_H__ /* 主状态机的两种可能状态,分别表述:当前正在分析请求行,当前正在分析头部字段 */ enum CHECK_STATE {CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER}; /* 从状态机的三种可能状态,即行的读取状态,分别表示:读取到一个完整的行、行出错和行数据尚且不完整 */ enum LINE_STATUS {LINE_OK = 0, LINE_BAD, LINE_OPEN}; /* 服务器处理HTTP请求的结果:NO_REQUEST表示请求不完整,需要继续读取客户数据;GET_REQUEST表示获得了一个完整的客户请求; * BAD_REQUEST表示客户请求有语法错误;FORBIDDEN_REQUEST表示客户对资源没有足够的访问权限;INTERNAL_ERROR表示服务器内部错误; * CLOSED_CONNECTION表示客户端已经关闭连接了 */ enum HTTP_CODE {NO_REQUEST, GET_REQUEST, BAD_REQUEST, FORBIDDEN_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION}; /* 分析HTTP请求的入口函数 */ enum HTTP_CODE parse_content(char *buffer, int *checked_index, enum CHECK_STATE *checkedstate, int read_index, int *start_line); /* 从状态机,用于解析出一行内容 */ enum LINE_STATUS parse_line(char *buffer, int *checked_index, int read_index); /* 分析请求行 */ enum HTTP_CODE parse_requestline(char *temp, enum CHECK_STATE *checkstate); /* 分析头部字段 */ enum HTTP_CODE parse_headers(char *temp); #endif
NO8《http读取和分析》的运行命令:
第一个终端:
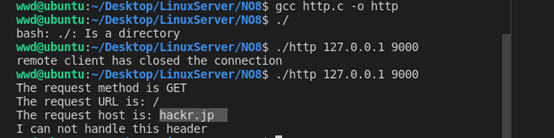
第二个终端:

数据:test.html
GET / HTTP/1.1
Host: hackr.jp
User-Agent: Moazilla/5.0