首先分析街拍图集的网页请求头部:
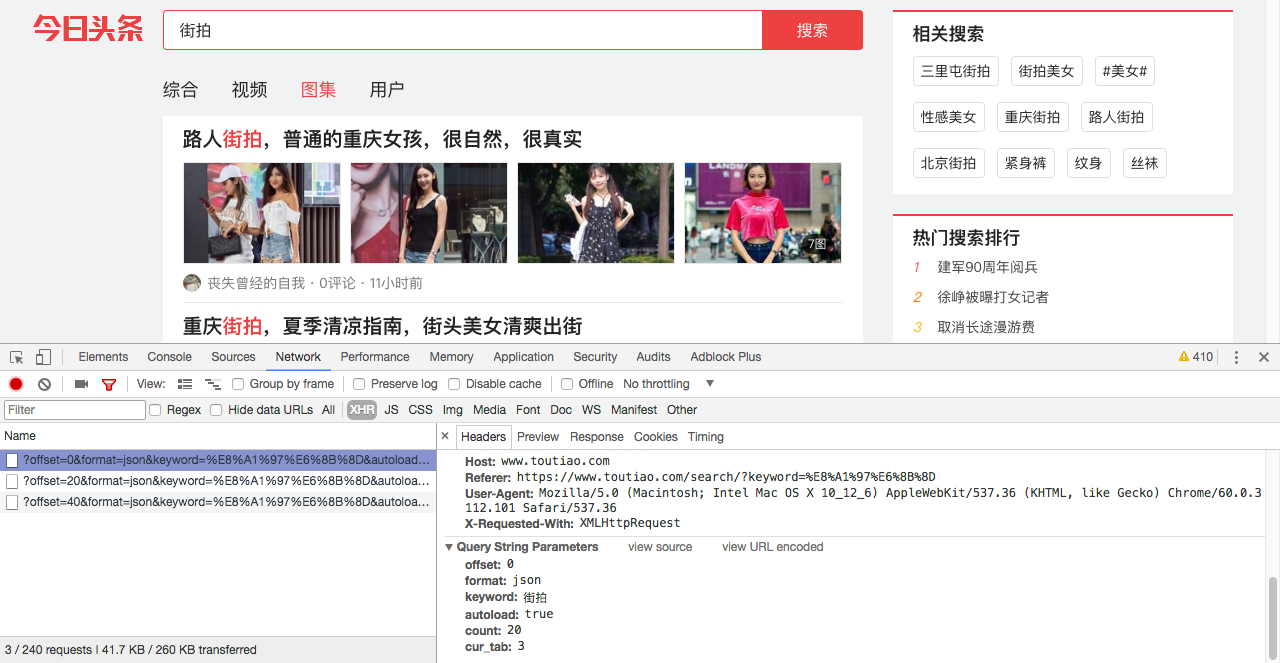
在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url:
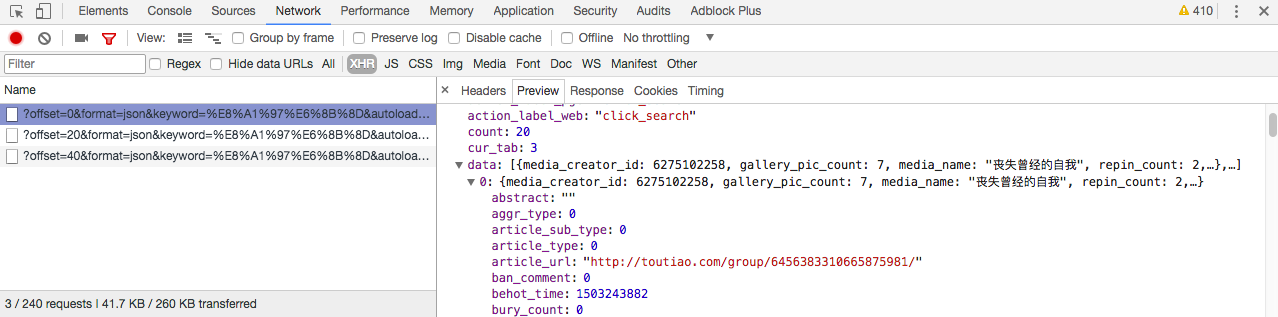
选中其中一张图片,分析 json 请求,可以找到图片地址在 gallery 一栏:
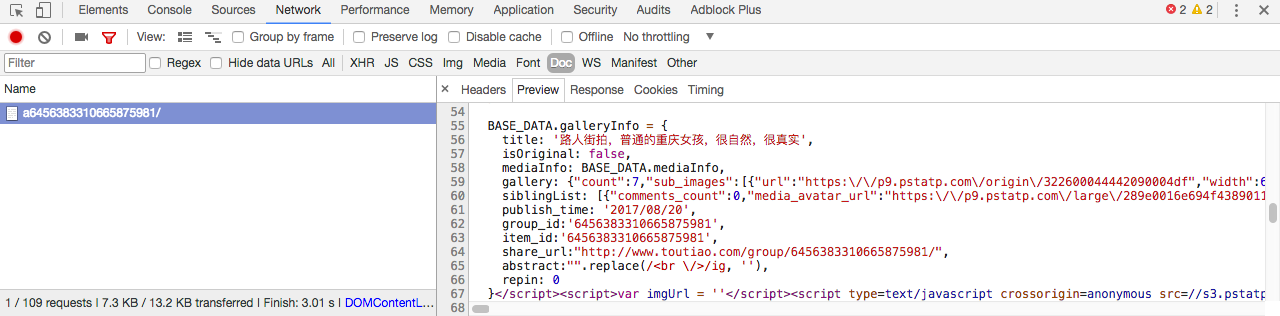
找到图片地址,接下来我们就可以来写代码了:
1.导入必要的库:
import requests
import json
import re
import pymongo
import os
from hashlib import md5
from multiprocessing import Pool
from json.decoder import JSONDecodeError
from requests.exceptions import RequestException
from urllib.parse import urlencode
from bs4 import BeautifulSoup
2.获取索引页并分析:
def get_page_index(offset, keyword):
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求索引页出错')
return None
def parse_page_index(text):
try:
data = json.loads(text)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
3.获取详情页并分析:
def get_page_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print(' 请求详情页出错')
return None
def parse_page_detail(html, url):
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()
images_pattern = re.compile('gallery: (.*?),
', re.S)
result = re.search(images_pattern, html)
if result:
data = json.loads(result.group(1))
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images:
download_images(image)
return {
'title': title,
'url': url,
'images': images
}
4.使用 MongoDB 数据库存储数据:
首先定义一个 config.py 文件,配置默认参数:
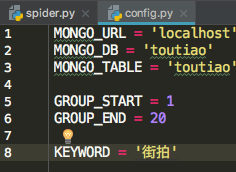
写入 MongoDB:
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print(' 存储到 MongoDB 成功', result)
return True
5.存储图片到本地:
def download_images(url):
print(' 正在下载', url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print(' 请求图片出错')
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
6.最后定义 main()函数,并开启多线程抓取20页图集:
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
text = get_page_index(offset, KEYWORD)
for url in parse_page_index(text):
html = get_page_detail(url)
if html:
result = parse_page_detail(html, url)
if result:
save_to_mongo(result)
if __name__ == '__main__':
groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)]
pool = Pool()
pool.map(main, groups)
代码GitHub地址:https://github.com/weixuqin/PythonProjects/tree/master/jiepai