一、scrapy基本操作
scrapy startproject scrapy_redis_spiders #创建项目
cd scrapy_redis_spiders #进入目录
scrapy genspider chouti chouti.com #创建爬虫项目网站
scrapy crawl chouti --nolog #运行爬虫,--nolog表示不打印日志
Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
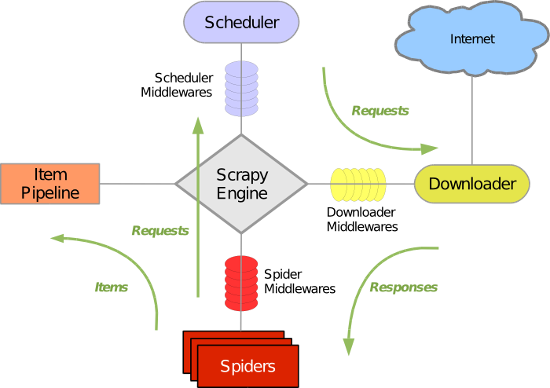
Scrapy主要包括以下组件
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spiders Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
二、Scrapy-redis基础配置
在settings中
ITEM_PIPELINES = {
# 'scrapy_redis_spiders.pipelines.ScrapyRedisSpidersPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 300,
'scrapy_redis_spiders.pipelines.BigfilePipeline': 400,
}
# ############ 连接redis 信息 ################# REDIS_HOST = '127.0.0.1' # 主机名 REDIS_PORT = 6379 # 端口 # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) # REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 默认:redis.StrictRedis REDIS_ENCODING = "utf-8" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 有引擎来执行:自定义调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 默认使用优先级队列(默认广度优先),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START = False # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key chouti:dupefilter SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter' # 去重规则对应处理的类 DUPEFILTER_DEBUG = False # 深度和优先级相关 DEPTH_PRIORITY = 1 REDIS_START_URLS_BATCH_SIZE = 1 # REDIS_START_URLS_AS_SET = True # 把起始url放到redis的集合 REDIS_START_URLS_AS_SET = False # 把起始url放到redis的列表
在spiders目录下的chouti.py中内容如下
import scrapy import scrapy_redis from scrapy_redis.spiders import RedisSpider from scrapy.http import Request from ..items import ScrapyRedisSpidersItem from scrapy.selector import HtmlXPathSelector from bs4 import BeautifulSoup from scrapy.http.cookies import CookieJar import os
class ChoutiSpider(RedisSpider):
name = 'chouti'
allowed_domains = ['chouti.com']
# start_urls = ['https://dig.chouti.com/']
# cookies = None
# def start_requests(self):
# # os.environ['HTTP_PROXY'] = "192.168.10.1"
#
# for url in self.start_urls:
# yield Request(url=url,callback=self.parse_index,meta={'cookiejar':True})
# yield Request(url=url,callback=self.parse)
def parse(self,response):
#response.url获取url
url = response.url
yield Request(url=url, callback=self.parse_index, meta={'cookiejar': True}) #meta={'cookiejar': True}表示自动获取cookies
def parse_index(self,response):
#登录chouti
# print(response.text)
req = Request(
url='https://dig.chouti.com/login',
method='POST',
headers={'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'},
body='phone=86xxxxxxx&password=xxxxxx&oneMonth=1', #输入手机号跟密码
callback=self.check_login,
meta={'cookiejar': True}
)
# print(req)
yield req
def check_login(self,response):
#获取主页信息
print('check_login:',response.text)
res = Request(
url='https://dig.chouti.com/',
method='GET',
# callback=self.parse_check_login, #这个去自动点赞功能
callback=self.parse, #这个是去下载图片功能
meta={'cookiejar': True},
dont_filter=True, #默认是False 默认表示去重 True表示这个url不去重
)
# print("res:",res)
yield res
def parse_check_login(self,response):
#获取主页信息然后进行自动点赞
# print('parse_check_login:',response.text)
hxs = HtmlXPathSelector(response=response)
# print(hxs)
items = response.xpath("//div[@id='content-list']/div[@class='item']")
# print(items)
for item in items:
#点赞带的share-linkid号获取所有的
linksID = item.xpath(".//div[@class='part2']/@share-linkid").extract_first()
# print(linksID)
for nid in linksID:
res = Request(
url='https://dig.chouti.com/link/vote?linksId=%s'%nid,
method='POST',
callback=self.parse_show_result,
meta={'cookiejar': True} #携带cookies
)
yield res
def parse_show_result(self,response):
print(response.text)
def parse(self, response):
hxs = HtmlXPathSelector(response=response)
# 去下载的页面中:找新闻
items = hxs.xpath("//div[@id='content-list']/div[@class='item']")
for item in items:
# print(item)
href = item.xpath(".//div[@class='part1']//a[1]/@href").extract_first()
# img = item.xpath("//div[@class='news-pic']/img/@original").extract_first()
img = item.xpath(".//div[@class='part2']/@share-pic").extract_first()
# print(img)
# file_name = img.rsplit('//')[1].rsplit('?')[0]
img_name = img.rsplit('_')[-1]
file_path = 'images/{0}'.format(img_name)
#使用大文件下载方式
item = ScrapyRedisSpidersItem(url=img, type='file', file_name=file_path)
print(img)
yield item
# pages = hxs.xpath("//div[@id='page-area']//a[@class='ct_pagepa']/@href").extract()
# print(pages)
# for page_url in pages:
# page_url = "http://dig.chouti.com" + page_url
# print(page_url)
# yield Request(url=page_url, callback=self.parse)
在scrapy_redis_spiders目录下载创建images目录用于存在图片
在scrapy_redis_spiders目录下配置items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ScrapyRedisSpidersItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() url = scrapy.Field() img = scrapy.Field() type = scrapy.Field() file_name = scrapy.Field()
在scrapy_redis_spiders中配置pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html from twisted.web.client import Agent, getPage, ResponseDone, PotentialDataLoss from twisted.internet import defer, reactor, protocol from twisted.web._newclient import Response from io import BytesIO class ScrapyRedisSpidersPipeline(object): def process_item(self, item, spider): return item class _ResponseReader(protocol.Protocol): #与BigfilePipeline配套下载大文件 def __init__(self, finished, txresponse, file_name): self._finished = finished self._txresponse = txresponse self._bytes_received = 0 self.f = open(file_name, mode='wb') def dataReceived(self, bodyBytes): self._bytes_received += len(bodyBytes) # 一点一点的下载 self.f.write(bodyBytes) self.f.flush() def connectionLost(self, reason): if self._finished.called: return if reason.check(ResponseDone): # 下载完成 self._finished.callback((self._txresponse, 'success')) elif reason.check(PotentialDataLoss): # 下载部分 self._finished.callback((self._txresponse, 'partial')) else: # 下载异常 self._finished.errback(reason) self.f.close() class BigfilePipeline(object): """ 用于下载大文件 """ def process_item(self, item, spider): # 创建一个下载文件的任务 if item['type'] == 'file': agent = Agent(reactor) d = agent.request( method=b'GET', uri=bytes(item['url'], encoding='ascii') ) # 当文件开始下载之后,自动执行 self._cb_bodyready 方法 d.addCallback(self._cb_bodyready, file_name=item['file_name']) return d else: return item def _cb_bodyready(self, txresponse, file_name): # 创建 Deferred 对象,控制直到下载完成后,再关闭链接 d = defer.Deferred() d.addBoth(self.download_result) # 下载完成/异常/错误之后执行的回调函数 txresponse.deliverBody(_ResponseReader(d, txresponse, file_name)) return d def download_result(self, response): pass
在scrapy_redis_spiders目录下创建一个start_url.py
#!/usr/bin/env python #coding=utf-8 import redis conn = redis.Redis(host='127.0.0.1',port=6379) # 起始url的Key: chouti:start_urls conn.lpush("chouti:start_urls",'https://dig.chouti.com') v = conn.keys() # value = v.mget("chouti:start_urls") print(v)