论文地址:https://arxiv.org/pdf/1711.01731.pdf
论文翻译
论文大纲
一、两类问答系统
任务导向的对话系统
任务为导向的对话系统是帮助用户去完成特定任务,比如找商品,订住宿,订餐厅等。实现任务为导向的对话系统,主要有两类方式:
- Pipeline method
通过4个步骤去完成对话任务
2)End-to-End method。
端到端地完成对话任务
非任务导向的对话系统
非任务导向的对话系统是与用户进行互动并提供回答,简单的说,就是在开放领域的闲聊。实现非任务导向对话系统也主要可分为两类:
- generative method
生成式对话
2)retrived-based method
答案选择式对话
文章就以上两类对话系统,以及各自的实现方法进行详细综述与讲解。
二、任务导向的对话系统
Pipeline method
Pipeline method的步骤可以分为4个,分别是自然语言理解–>对话状态跟踪–>策略学习–>自然语言生成
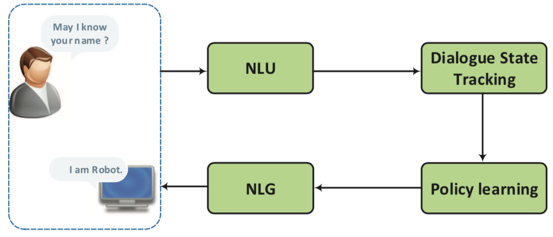
下面对着四个步骤分别进行介绍:
自然语言理解 Natrual Language Understanding(NLU)
目标:将用户的输入语句转化为预先设定好的语义槽(semantic slot)
先来个例子:
在任务型对话系统中用户想要查酒店信息,于是说出一个句子:“show restaurant at New York tomorrow.”
理解这个句子需要两个步骤:
(1)意图识别:首先要判断用户是需要订酒店,而不是订机票,买东西,查快递,那么这属于一个分类问题,即识别用户意图类别
(2)语义槽填充:查酒店类别会有与之相对应的预先设定好语义槽(semantic slot),如New York是location的slot value.填充槽值的过程即在句中做词信息的抽取。
以上两步也可分别称作意图识别(intent detection)与槽填充(slot filling):
意图识别: 是分类问题,将用户发出的语句分类到预先设定好的意图类别中。简而言之,其实就是短文本的分类,最近一般都使用深度学习来做分类。
深度学习在意图识别中的应用:
- “Use of kernel deep convex networks and end-to-end learning for spoken language understanding.(2012)”
- “Towards deeper understanding: Deep convex networks for se- mantic utterance classification.(2012)”
- “Zero- shot learning and clustering for semantic utterance classification using deep learning(2014)”
其中,使用卷积神经网络来抽取查询语句的向量表征(vector representations):
*“Query intent detection using convolutional neural networks(2016)”
槽填充:是序列标注问题,为句子中的每个词打上语义标签。输入是由一组序列的词组成的句子,输出是该组序列的词及词对应的语义类别(slot/concept ID)。可以类比中文分词,词性标注等问题。因此传统的做法有HMM,CRF等。最近效果较好的是DBN,RNN去做序列标注
使用了deep belief networ(DBNs),取得优于CRF baseline的效果:
*“Use of kernel deep convex networks and end-to-end learning for spoken language understanding.(2012)”
*“Deep belief network based semantic taggers for spoken language understanding.(2013)”
[17]和[15]使用了deep belief networ(DBNs),
使用了RNN
*“Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding.(2013)”
*“Recurrent neural networks for language understanding.(2013)”
*“Spoken language understanding using long short-term memory neural networks.(2014)”
Dialogue State Tracking
根据对话历史管理每一轮对话的输入,并且预测当前对话的状态。对话状态Ht表示到时间t为止对话的表征(也叫做slot或semantic frame)。对话状态的跟踪主要有3个方面:the user’s goal, the user’s action, the dialogue history.
传统的方式:是使用手工做的规则来选择最可能的结果。但是错误率高。
基于统计的方式:会对每轮对话都计算对每个state的概率分布。
*“The hidden information state model: A practical framework for pomdp- based spoken dialogue management(2010)”
对每轮对话的每个slot都计算概率分布
*“A belief tracking challenge task for spoken dialog systems.(2012)”
*“The dialog state tracking challenge.(2013)”
基于规则的方式:
*“A simple and generic belief tracking mechanism for the dialog state tracking chal- lenge: On the believability of observed information(2013)”
用CRF
“Recipe for building robust spoken dialog state trackers: Dialog state tracking challenge system description(2013)”
“Structured discriminative model for dialog state tracking(2013)”
“Dialog state tracking using conditional random fields(2013)”
用最大熵模型
“Multi-domain learning and generalization in dialog state tracking.(2013)”
用基于网络的排序
“Web-style ranking and slu combina- tion for dialog state tracking(2014)”
基于深度学习:深度学习在信念跟踪上的应用(可以跨领域应用)。
“Deep neu- ral network approach for the dialog state tracking challenge(2013)”
多领域RNN对话跟踪
“Multi-domain dialog state tracking using recurrent neural networks(2015)”
利用神经信念跟踪NBT检测每个slot pair
“Neural belief tracker: Data-driven dialogue state tracking.(2017)”
Policay learning
根据当前对话状态做出下一步的反应。举个例子,在线上购物的场景中,若上一步识别出来的对话状态是“Recommendation",那么这一步骤就会给出对应推荐的action,即从数据库中获取商品。
监督学习:
首先一个rule-based agent用来做热启动,然后监督学习会在根据rule生成的action上进行:
*“Building task-oriented dialogue systems for on- line shopping”
强化学习:
*“Strategic dialogue management via deep reinforcement learning.(2015)”
Natural language generation(NLG)
将Policy learning给出的反应转换成相应的自然语言形式的回答提供给用户。一个好的回答生成器应具备4个特点:adequacy, fluent,readability and variation[78].
传统的方法[90;79]:使用sentence planning,将输入的语义特征转换成中间形式(比如树状或模版形式),然后再通过surface realization将中间形式转换成最终的回答。
深度学习的方法:[94;95]介绍了NN于LSTM结合的结构,类似于RNNLM;[94]使用前向RNN生成器,以及CNN和backwards RNN的reranker,所有子模型进行联合优化;[95;83]新增一个control celll来gate the dialogue act;[96]将前者在multiple-domain上改进于应用;[123]使用encode-decode LSTM-based,并结合了attention machanism;[20]使用sequence-to-sequence 方法。
端到端方法实现任务型问答
特点:使用单个模型;可于外部的结构数据库进行交互
使用基于网络的端到端的可训练的对话系统。将对话系统的问题转换为学习一个映射(从历史对话–>回答)。但是,其需要大量训练数据并且缺少鲁棒性。
"A network-based end-to-end trainable task-oriented dialogue system(2017)”
“end-to-end goal-oriented dialog(2017)”
使用end-to-end 强化学习方法,联合训练对话跟踪于策略学习,但是也存在缺陷:不可微+无法获取语义不确定性。
“Towards end-to-end learn- ing for dialog state tracking and management us- ing deep reinforcement learning.(2016)”
基于memory network,使用RNN+可微分attention
“Key-value retrieval networks for task-oriented dialogue(2017)”
三、非任务型对话:闲聊系统
非任务型对话主流有两类:生成式对话和抽取式对话。
生成式闲聊系统构建:Neural generative models
Neural generative models主要是依赖于sequence to sequence的模型。但光建立一个序列模型还远远不够,一个好的对话系统还需要考虑:
(1)历史对话对当前对话的影响
(2)回答的多样性
(3)针对不同领域与用户个性提供不同的回答
(4)基于外部的知识库去做回答
(5)内部学习与评估(两个对话机器人互相对话作为训练)
Dialogue context
将历史对话的内容转换成词或短语向量的表征作为序列模型的特征
建立一个层级结构的attention机制去找出重要的历史语句
根据相关性去找出与问句最相关的context作为特征
Reponse Diversity
调整目标函数:使用maximum mutual information作为最优化目标
使用IDF去评估回答的多样性
调整beam search,使得输出多样回答
加入re-ranking步骤
增加输入信息的多样性
加入latent variable
Topic and personality
先用主题模型LDA去生成主题,将主题信息作为特征输入对话模型
将用户对话做领域的分类
加入emotional embedding到生成模型中
加入profile的信息
强化学习
Outside knowledge base
使用memory network使对话系统与知识库做交互
将知识库中的词语模型生成的词做结合
Evaluation
如何评价产生对话的好坏呢?
- 基于字符重叠度的系列指标(word overlap metrics):BLEU,METEOR,ROUGE
- 利用两个RNN来做评估
将context,the true response and candidate response表征成向量计算向量之间的相似性来评估 - 图灵测试
adversarial evaluation model
基于检索的闲聊系统:Retrieval-based method
Retrieval-based method是从候选答案中选出一个答案作为回答。主要有两个应用领域:
(1)单轮对话
(2)多轮对话
混合式闲聊系统:Hybrid methods
将以上生成式对话和抽取式对话结合起来,先从通过抽取模型抽取出答案,再将答案放到RNN中去生成回答。