本月初,Azure Data Explorer (后面简称 ADX) 已经在 Azure 中国区发布预览。ADX 作为一款海量数据的交互查询引擎,良好的数据格式兼容性(结构化,半结构化,非结构化),出色的性能可以支持亿级数据秒级的查询。今天这篇文章不做 ADX 的通用使用说明书,我们换一种玩法,如今很多数据分析产品已经将计算能力开放给用户,使客户可以实现对数据近缘计算,这篇中介绍 ML on ADX,如何对海量数据近缘的实现 ML。
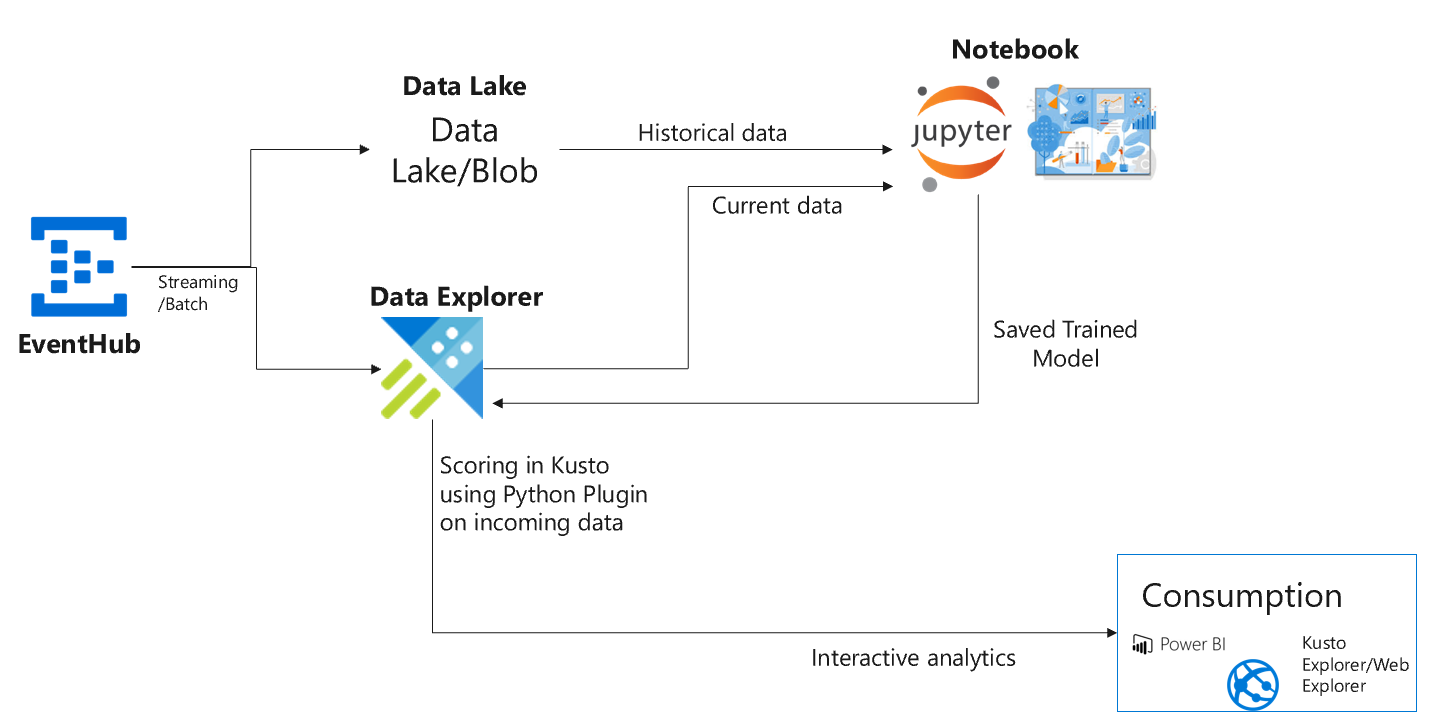
我们先来看一下方案架构:本文中我们采用开放数据集 Occupancy Detection ,该数据集中记录这在房间内持续监测的温度、湿度、光线、二氧化碳含量等信息,且包含了房间占用信息(Bool,0 代表有人,1 代表无人)。这些 IOT 的信息通过 Event Hub 实时采集注入到 Data Explorer,架构中通过在 Out of Box 的 Notebook 中进行 ML 的模型训练,然后将训练好的模型保存到 Data Explorer。Data Explorer 的 Python PlugIn 能力将数据平台的计算能力开放给用户,借用该功能将训练好的模型运行在 Data Explorer 上,从而实现对实时数据的在线推理。
数据准备,本文中将 Occupancy Detection 的数据已经导入到 Data Exploer,导入方法不再做赘述,大家可以参见文档。在 ADX 中我们创建了示例数据 Demo,其中的 OccupancyDetectionTable 记录了 ML 所需的训练数据和测试数据,表中通过 Test 列来标注是否为训练数据。数据样本格式参考:

本文示例中采用的训练数据量级在 1w 条量级,所以 ML 训练计算量开销不大,此示例我们采用 Azure NoteBook Build-In 计算资源进行 ML 训练,通过 ADX 的 SDK 从 ADX 中拉取训练数据,然后在 NoteBook 计算资源中进行模型训练,训练中我们采用4种 ML 算法进行交叉比对,选择结果最好的模型然后将模型通过 ADX SDK 存储到 ADX 中。下面我们来看一下 NoteBook 中的 Jupyter 的示例代码:
# Load Lib from azure.kusto.data.request import KustoClient, KustoConnectionStringBuilder from azure.kusto.data.exceptions import KustoServiceError from azure.kusto.data.helpers import dataframe_from_result_table import pandas as pd import datetime import pickle import binascii %env PYTHONHASHSEED=0 # Set Query patten to load training data, you can change the the table name with your own table name q = ''' OccupancyDetectionTable ''' fn = "df" + str(hash(q)) + ".pkl" print("Cache file name: ", fn) # Init ADX conection parameter, you can change to your envrionment parameter AAD_TENANT_ID = "{your AAD tenant ID}" APP_CLIENT_ID = "{your SP Client ID}" APP_SECRET = "{your SP secret}" KUSTO_CLUSTER = "{your adx cluster endpoint in format https://xxx.region.kusto.chinacloudapi.cn:443/}" # Init ADX Client KCSB = KustoConnectionStringBuilder.with_aad_application_key_authentication(KUSTO_CLUSTER, APP_CLIENT_ID, APP_SECRET, AAD_TENANT_ID) KUSTO_CLIENT = KustoClient(KCSB) KUSTO_DATABASE = "demo" # Load Data fn = "df" + str(hash(q)) + ".pkl" try: df = pd.read_pickle(fn) print("Load df from " + fn) except: print("Execute query...") try: KUSTO_QUERY = q RESPONSE = KUSTO_CLIENT.execute(KUSTO_DATABASE, KUSTO_QUERY) df = dataframe_from_result_table(RESPONSE.primary_results[0]) print("Save df to " + fn) df.to_pickle(fn) print(" ", df.shape, " ", df.columns) except Exception as ex: print(ex) # Check out sample data item schema print(df.shape, " ") print(df[-4:]) # Summary the Data Item counts df.groupby(['Test', 'Occupancy']).size() # Init ML Training and Testing Data train_x = df[df['Test'] == False][['Temperature', 'Humidity', 'Light', 'CO2', 'HumidityRatio']] train_y = df[df['Test'] == False]['Occupancy'] test_x = df[df['Test'] == True][['Temperature', 'Humidity', 'Light', 'CO2', 'HumidityRatio']] test_y = df[df['Test'] == True]['Occupancy'] # Load ML Lib from sklearn import tree from sklearn import neighbors from sklearn import naive_bayes from sklearn.linear_model import LogisticRegression from sklearn.model_selection import cross_val_score #Init four classifier types clf1 = tree.DecisionTreeClassifier() clf2 = LogisticRegression() clf3 = neighbors.KNeighborsClassifier() clf4 = naive_bayes.GaussianNB() print(train_x.shape, train_y.shape, test_x.shape, test_y.shape) # Train the model, select the best model clf1 = clf1.fit(train_x, train_y) clf2 = clf2.fit(train_x, train_y) clf3 = clf3.fit(train_x, train_y) clf4 = clf4.fit(train_x, train_y) for clf, label in zip([clf1, clf2, clf3, clf4], ['Decision Tree', 'Logistic Regression', 'K Nearest Neighbour', 'Naive Bayes']): scores = cross_val_score(clf, train_x, train_y, cv=5, scoring='accuracy') print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), label)) for clf, label in zip([clf1, clf2, clf3, clf4], ['Decision Tree', 'Logistic Regression', 'K Nearest Neighbour', 'Naive Bayes']): scores = cross_val_score(clf, test_x, test_y, cv=5, scoring='accuracy') print("Accuracy: %0.4f (+/- %0.4f) [%s]" % (scores.mean(), scores.std(), label)) # Dump out the ML Model to dataframe models_tbl = 'ML_Models' model_name = 'Occupancy' bmodel = pickle.dumps(clf2) smodel = binascii.hexlify(bmodel) now = datetime.datetime.now() dfm = pd.DataFrame({'name':[model_name], 'timestamp':[now], 'model':[smodel.decode("utf-8")]}) # Creat the ADX query to create the table to save model create_query = ''' .create table {0} (name: string, timestamp: datetime, model: string) '''.format(models_tbl) print(create_query) KUSTO_QUERY = create_query KUSTO_CLIENT.execute_mgmt(KUSTO_DATABASE, KUSTO_QUERY) # Init ADX ingest client to save the model in ADX from azure.kusto.ingest import KustoStreamingIngestClient, IngestionProperties, DataFormat, KustoIngestClient KUSTO_CLUSTER = "{your adx cluster endpoint in format https://xxx.region.kusto.chinacloudapi.cn}" KCSB = KustoConnectionStringBuilder.with_aad_application_key_authentication(KUSTO_CLUSTER, APP_CLIENT_ID, APP_SECRET, AAD_TENANT_ID) KUSTO_INGEST_CLIENT = KustoStreamingIngestClient(KCSB)
在 ADX 中的 ML_Models 表中查看记录,可以看到训练导出的模型已经保存至其中。

模型导入后可对在线数据通过 Python Plug-In 来调用该模型,对在线数据进行推理。为了方便理解,我们将执行通过 Kusto Query Launguage 来完成。
# Define ML Python Function let classify_sf=(samples:(*), models_tbl:(name:string, timestamp:datetime, model:string), model_name:string, features_cols:dynamic, pred_col:string) { let model_str = toscalar(models_tbl | where name == model_name | top 1 by timestamp desc | project model); let kwargs = pack('smodel', model_str, 'features_cols', features_cols, 'pred_col', pred_col); let code = ' ' 'import pickle ' 'import binascii ' ' ' 'smodel = kargs["smodel"] ' 'features_cols = kargs["features_cols"] ' 'pred_col = kargs["pred_col"] ' 'bmodel = binascii.unhexlify(smodel) ' 'clf1 = pickle.loads(bmodel) ' 'df1 = df[features_cols] ' 'predictions = clf1.predict(df1) ' ' ' 'result = df ' 'result[pred_col] = pd.DataFrame(predictions, columns=["pred_col"])' ' ' ; samples | evaluate python(typeof(*, pred_col:bool ), code, kwargs) }; // // Test scoring // OccupancyDetectionTable | where Test == bool(true) | extend pred_Occupancy=bool(false) | invoke classify_sf(ML_Models, 'Occupancy', pack_array('Temperature', 'Humidity', 'Light', 'CO2', 'HumidityRatio'), 'pred_Occupancy') | fork (summarize n=count() by Occupancy, pred_Occupancy)
查看执行结果,可以看到准确率还可以呦。

整个架构中 NoteBook 使用 kusto SDK 与 ADX Cluster 进行沟通,目前中国区的 ADX Endpoint 在 Python SDK 中还无法直接指定,可以通过修改 security.py (路径 azure/kusto/data)中的认证节点来实现和中国节点的连接:
self._adal_context = AuthenticationContext("https://https://login.microsoftonline.com/{0}".format(authority)) 修改为: self._adal_context = AuthenticationContext("https://login.partner.microsoftonline.cn/{0}".format(authority))
另外大家需要注意这些有意思的功能默认不是打开的,ML 推理在 ADX 上使用的 Python Plug-In 功能需要开启售后支持 Case 开启。保存模型到 ADX 使用的 StreamingIngestion 功能同样需要开启售后支持 Case 开启。
好了 ML on ADX 就介绍到这里,希望通过这篇文章可以帮助大家换个角度了解 ADX 这款产品。
补充资料:
Python Plug-in 功能支持哪些 Lib,可以参阅:http://docs.anaconda.com/anaconda/packages/old-pkg-lists/5.2.0/py3.6_win-64/