| 这个作业属于哪个班级 | 数据结构-网络20 |
|---|---|
| 这个作业的地址 | DS博客作业01--线性表 |
| 这个作业的目标 | 学习线性表相关内容 |
| 姓名 | 余智康 |
目录
0. 展示PTA总分
1. 本章学习总结
2. PTA实验作业
3. 阅读代码
0.PTA得分截图

1.本周学习总结(5分)
1.1 绪论(1分)
1.1.1 数据结构有哪些结构,各种结构解决什么问题?
- 数据结构分为逻辑结构和存储(物理)结构:
- 逻辑结构:
-
集合:集合中含有多种元素,这些元素无序存在。
-
线性结构:(一对一),除了开始和最后的元素外,每一个元素都有一个前驱和一个后继的n个数据元素有序集合。
可以使用线性结构完成名单之类有序信息的记录。
-
树结构:(一对多),除开始元素,每一个元素都有一个前驱;除终端元素,每一个元素都有一个或多个后继。

-
图结构:(多对多),每个元素的前驱个数和后继个数是任意的,所以可能没有开始、终端元素,也可能有多个开始、终端元素
2.存储结构:
-
顺序存储结构:连续的存储单元存放所有元素

-
链式存储结构:每个结点单独申请,所占的存储空间不一定连续,需要给每个结点添加指针域,存放相邻结点的地址

1.1.2 时间复杂度及空间复杂度概念。
- 时间复杂度用于衡量程序执行的时间,它取执行频度T(n)的数量级。若程序执行的次数与问题规模(n)无关,则时间频度为O(1);
- 空间复杂度是算法在运行过程中临时占用的储存空间的量度。若临时占用的空间对于问题规模来说是常数,那么该算法就称为就地工作算法或原地工作算法。
1.1.3 时间复杂度有哪些?如何计算程序的时间复杂度和空间复杂度,举例说明。
- 时间复杂度:
从小到大排序为:O(1) < O(log2 n) < O(n) < O(n log2 n) < O(n^2) < O(n^3) < O(2^n) < O(n!)
- 计算:通过分析执行的频度,取数量级来表示
- 简化分析:仅仅考虑算法中的基本操作,(基本操作:是多重循环中的最深层语句)
void func(int n)
{
int i = 0, s = 0;
while( s < n)
{
i++; //基本操作
s = s + i; //基本操作
}
}
设循环执行k次,变量i从0递增1,直到k为止。
所以循环结束时,s = (1 + k) * k * (1/2)>= n,增加一个用于修正的常数C,则(1 + k) * k * (1/2) + c = n
解得,k = [-1 + √(8n + 1 -8c)] * (1/2), 从而得出该算法的时间复杂度为:O(√n)
- 求和、求积的计算:设T1(n) = O(f(n)), T2(n) = O(g(n))
- 求和:T1(n) + T2(n) = O(MAX(f(n),g(n)))
- 求积:T1(n) * T2(n) = O(f(n) * g(n))
for(i = 0; i < n; i++) /*片段1*/
{
printf("i = %d ",i);
}
/*片段2*/
for(i=0; i<n; i++) // 循环1
for(j=i; j>=1; j/=2)
printf(“%d
”, j); // 循环2
片段1中,易得,T1(n) = n;
片段2中,
不考虑循环1时,设循环2执行k次,得出 n / 2 ^ k + c = 0, 解出T2(n) = O(log2 n)
而循环1执行n次,得出T3 = O(n),
由此得出,片段2中, 时间复杂度为 O(n * log2 n)
由于片段1的时间复杂度小于片段2的时间复杂度,故该算法的时间复杂度为 O(n log2 n)
- 递归:先写出递推式,然后求解递推式得出算法的执行时间,从而得出时间复杂度
int fact(int n)
{
if(n<=1)
return 1;
else
return n*fact(n-1);
}
当 k = 1时, T(k) = 1,
当 k ≠ 1时, T(k) = T(k-1) + 1 = T(k-2) + 1 + 1 = T(1) + 1 + ... + 1 = n
- 空间复杂度
- 计算:通过分析函数体中所占用的临时空间,取数量级来表示
void fun(int a[], int n, int k)
{
int i;
if( k == n-1)
{
for(i = 0; i<n; i++)
{
printf("%d
",a[i]);
}
}
else
{
for(i = k; i<n; i++)
a[i] = a[i] + i * i;
fun(a, n, k+1);
}
}
分析fun(a, n, 0)时的空间复杂度, 设fun(a, n, k)所占的临时空间为S1(n, k)
当k = n - 1时, 仅定义了一个变量,S(n) = O(1);
当k ≠ n - 1时, S1(n, k) = S1(n, k+1)
可得:S(n) = S1(n, 0) = 1 + S(n,1) = 1 + 1 + ... + 1 + S1(n,n-1) = n = O(n)
1.2 线性表(1分)
1.2.1 顺序表
介绍顺序表结构体定义、顺序表插入、删除的代码操作
介绍顺序表插入、删除操作时间复杂度
- 结构体定义:
* 思路:需要数组,需要长度
* 代码:
typedef struct SqList
{
int data[MAXSIZE];
int length;
}SqList,*List;
- 顺序表插入
-
思路:挪动数组,长度增加
-

-
挪动,
-
-
将insert插入,
-

-
将length增加
-
时间复杂度:O(n)
-
代码:
// position 为插入的位置,
// num_insert 为插入的数据,
for( i = L->length; i > position; i--) //挪动数组
{
L->data[i] = L->data[i=1];
}
L->data[position] = num_insert; //插入
L->length++; //长度增加
- 顺序表删除
- 思路:挪动数组,长度减少

- 挪动,以删除data2为例

- 将length减小
- 时间复杂度: O(n),
- 代码:
// position 为删除的位置,
for(i = position; i < L->length - 1; i++)
{
L->data[i] = L->data[i+1];
}
L->length--; //长度减少
1.2.2 链表(2分)
画一条链表,并在此结构上介绍如何设计链表结构体、头插法、尾插法、链表插入、删除操作
重构链表如何操作?链表操作注意事项请罗列。
- 链表:
*
* 结构体:思路:需要数据、以及指针域
typedef struct LNode
{
int data;
srtuct LNode * next;
}LNode, *LinkList;
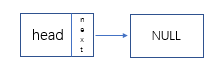
- 头插法:
- 新建头结点,并将它的next指向空:
- 新建结点,先把head的next赋值给新结点的next,再将新结点的地址赋值给head的next
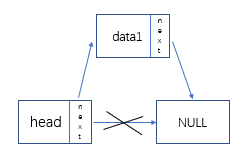
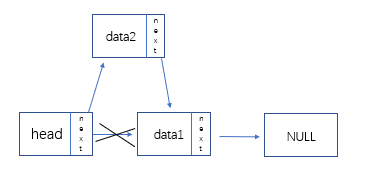
node -> next = L->next;
L->next = node;
- 尾插法:
-
新建头结点,并它的next指向空:
-
新建尾指针,指向最后一个结点:
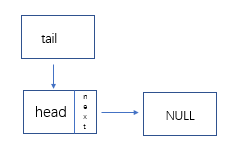
-
新建结点,将新结点的地址赋给tail的结点的next,在将tail指向tail指向的结点的下一个结点(即,最后一个结点)
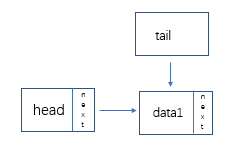
-
最后让tail指向的结点的next指向NULL
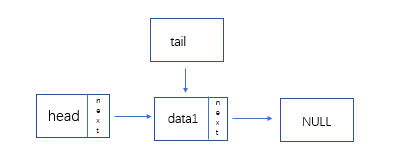
while()
{
...
tail -> next = node;
tail = tail ->next;
}
tail ->next = NULL;
- 链表插入:
- 思路:通过前驱,修改next关系
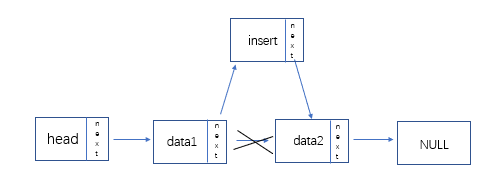
- 代码:
LinkList node; //新建结点,并输入数据
node = new LNode;
cin >> node -> data;
node -> next = pre -> next; //修改next关系
pre -> next = node;
- 删除:
-
思路:找前驱,修改next关系
-

-
代码:
LinkList p;
p = pre -> next; //暂时保存要删除元素的地址
pre -> next = pre ->next ->next; //修改next关系
delete p; //释放要删除元素的空间
-
链表:
* 存储空间:1)不连续的空间,需要多少申请多少,提高了空间的利用率
* 插入: 1)不需要挪动数据,仅修改next关系,若是已知要删除元素的前驱,时间复杂度为O(1)
* 删除: 1)不需要挪动数据,并物理意义上删除了数据,若是已知要删除元素的前驱,时间复杂度为O(1) -
顺序表:
* 存储空间:1)连续的空间,但需要申请的空间一般大于所使用的空间,可能对空间有所浪费;2)空间有限,若是后续要添加的数据过多,可能溢出
* 插入: 1)需要挪动数据;2)插入的数据过多时,数组可能溢出
* 删除: 1)需要挪动数据;2)并没有真正删除了数据 -
链表操作注意事项:
* 链表的非空判断;
* 对链表结点的next关系进行修改之前,一般注意保留后继结点;
* 链表有无头结点;
* 遍历时要记住新建遍历指针,一般不要将指向头结点的头指针拿去当遍历指针(犯过这种错误、(o_ _)ノ);
* 链表的类型:单链表,循环单链表,循环双链表等;
* 删除结点后,记得delete;
1.2.3 有序表及单循环链表(1分)
有序顺序表插入操作,代码或伪代码介绍。
有序单链表数据插入、删除。代码或伪代码介绍。
有序链表合并,代码或伪代码。尽量结合图形介绍。
有序链表合并和有序顺序表合并,有哪些优势?
单循环链表特点,循环遍历方式?
- 有序顺序表插入(以递增为例):
- 代码介绍:
// insert_num 为插入的数据
int position = 0; // 存放要插入的位置
for(i = L->length - 1; i >= 0 && L->data[i] < insert_num; i--)
{
L->data[i + 1] = L->data[i];
}
position = i+1; //找位置
L->data[position] = insert_num; //插入
L->length++; //增加长度
- 有序单链表插入、删除(以递增为例):
-
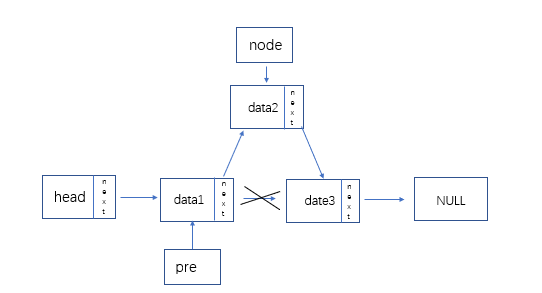
-
代码介绍:
LinkList pre = L;
while(pre->next && pre -> next > insert_num ) //遍历,寻找插入位置的前驱
{
pre = pre->next;
}
LinkList node = new LNode; //新建结点,存放插入数据
node->data = insert_num;
node->next = pre->next; //修改next关系,完成插入
pre->next = node;
- 有序链表合并:
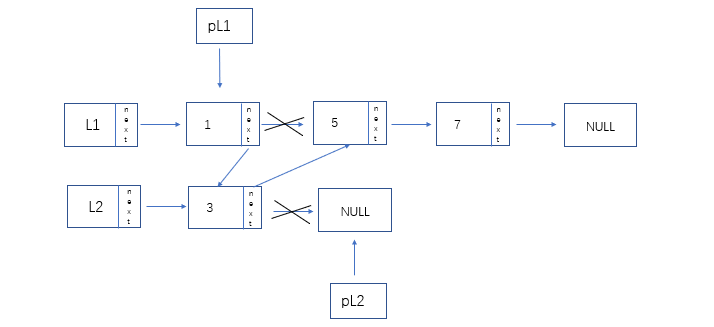
- 代码介绍:
LinkList pL1 = L1->next; //新建遍历指针
LinkList pL2 = L2->next;
LinkList merge_L = L; //重构链表
L->next = NULL;
while(pL1 && pL2) //任一为空时结束循环
{
if(pL1->data == pL2->data) //相同
{
merge_L -> next = pL1;
merge_L = merge->next;
pL1 = pL1 ->next;
pL2 = pL2 ->next;
}
else if(pL1->data < pL2->data)
{
merge_L -> next = pL1;
merge_L = merge->next;
pL1 = pL1 ->next;
}
else
{
merge_L -> next = pL2;
merge_L = merge->next;
pL2 = pL3->next;
}
}
if(pL1) //若pL1所指向为空,则pL2剩下的数据元素接到merge_L的后面
merge_L ->next = pL2;
else
merge_L ->next = pL1;
- 有序链表合并的优势:
- (空间上)有序顺序表合并需要新建一个数组;有序链表可以在原链表上进行重构,更节省空间
- (时间上)若合并的某个表先为空,有序顺序表需要将剩下的元素遍历存入重构数组中;而有序链表仅仅修改next关系即可
- 单循环链表特点,循环遍历方式:
- 特点:
1)尾结点的next不指向NULL,而是指向头结点
2)可以从任何位置开始遍历整个链表 - 遍历条件:
LinkList p = L->next;
while(p != L) //与单链表不同的是,将 p!= NULL 改为了p!= L
{
...
p = p->next;
}
2.PTA实验作业(4分)
此处请放置下面2题代码所在码云地址(markdown插入代码所在的链接)。
2.1 两个有序序列的中位数
- 代码:(复制链接,应该可以访问)
https://gitee.com/welcome_to_tommrow/pta-code/blob/master/Median%20of%20two%20ordered%20sequences%20.cpp#
2.1.1 解题思路及伪代码
- 解题思路:
- 已知个数、且递增 ——> 通过简单计算得出中位数的位置
- 遍历,同时计数,当负责计数的变量值等于中位数的位置时,找到中位数
- 所需函数:链表的创建与销毁、找中位数
- 伪代码(找中位数):
LinkList MidLNode(LinkList L1, LinkList L2, int position_mid)
{
if mid_position = 0
return NULL; //表示该表为空表
end if
LinkList pL1 = L1->next;
LinkList pL2 = L2->next;
LinkList pMid; //指向中位数
int count == 0;
while count != mid_position do //未到达中位数位置时,循环继续
if pL1->data <= pL2->data
mid = pL1;
pL1 = pL1->next;
end if
else
mid = pL2;
pL2 = pL2->next;
end else
count++;
end while
return mid;
}
2.1.2 总结解题所用的知识点
- 链表遍历、找到指定的第几个位置的数据结点
2.2 一元多项式的乘法与加法运算
- 代码:(复制链接,应该可以访问)
https://gitee.com/welcome_to_tommrow/pta-code/blob/master/Multiplication%20and%20addition%20of%20unary%20polynomials.cpp
2.2.1 解题思路及伪代码
- 解题思路:
- 多项式加法:链表的合并。可以重构链表L1,将加法的结果放在链表L1中,以便乘法时使用
- 多项式乘法:多个链表的合并。L1的每一项和L2相乘,再相加。
- 可以将L1的一项和L2相乘的结果放在temp_L链表中,
- 再调用合并的函数将L_multiply 和temp_L合并,结果放在L_multiply链中
- 特殊情况处理:
- 结果计算完后,通过自定义的函数DelEmpty(),删去系数为0的项
- 输出时,若是链表为空,输出 0 0
- 所用函数:
- 链表的创建和销毁、输出、多项式合并、多项式相乘、删去系数为0的项、
- 伪代码:
// 多项式合并:
LinkList MergeList(LinkList L1, LinkList L2)
{
pL1 = L1 ->next;
pL2 = L2 -> next;
tail = L1;
L_merge = L1;
L_merge->next = NULL;
while(pL1 != NULL && pL2 != NULL) do
{
if( pL1 -> index = pL2 ->index) //如果指数相等
{
pL1->coefficient = pL1->coefficient + pL2->coefficient;//系数相加,存放在pL1中
再将pL1所指的结点接到tail后面;
tail = tail->tail; //tail移动
pL1、pL2移动;
}end if
else if (pL1 ->index > PL2 ->index)
{
将pL1所指的结点接到tail后面;
tail = tail->tail; //tail移动
pL1移动;
} end else if
//...pL2所指结点的指数大时,处理情况与pL1大类似,不多赘述
}end while
if(pL1) //如果while循环结束,pL1仍剩余
tail ->next = pL1;
end if
else
tail ->next = pL2;
end else
return L_merge; //返回头结点
}
// 多项式相乘:
LinkList MultiplyList(LinkList L1, LinkList L2)
{
新建LinkList指针L_multiply(头结点)存放最终相乘后的多项式
新建LinkList指针L_temp,存放计算过程中多项式
while(pL1)
{
L_temp->NULL; //每轮开始时,重构L_temp;
tail = L_temp;
pL2 = L2->next; //每轮初始化pL2
while(pL2)
{
新建node结点,并分配内存;
//node的介绍:node结点存放pL1所指的数据与pL2所指的数据相乘;
node->index = pL1->index + pL2->index;
node->coefficient = pL1->coefficient * pL2->coefficient;
将node接到tail后面;
tail、pL2移动到后一个结点
}
tail -> next = NULL; //尾结点的next为空
将pL1移动到后一位
调用函数MergeList(),将L_multiply和L_temp合并,
合并后的多项式在L_multiply中
}end while
return L_multiply;
}end while
2.2.2 总结解题所用的知识点
- 多项式合并,用到了链表合并的知识点:
- 链表重构,尾插法、链表遍历
- 多项式相乘,用到了尾插法新建链表、调用函数
3.阅读代码(1分)
3.1 题目及解题代码
- 题目描述
判断给定的链表中是否有环。如果有环则返回true,否则返回false。
class Solution {
public:
bool hasCycle(ListNode *head) {
ListNode* fast = head;
ListNode* slow = head;
while(slow!=NULL&&fast->next!=NULL&&fast->next->next!=NULL)
{
fast = fast->next->next;
slow = slow->next;
if(fast==slow)
{
return true;
}
}
return false;
}
};
3.2 该题的设计思路
设计思路:
- 使用快慢指针,指针p1每次移动一个结点,指针p2每次移动2个结点,若p1、p2相遇则证明环存在
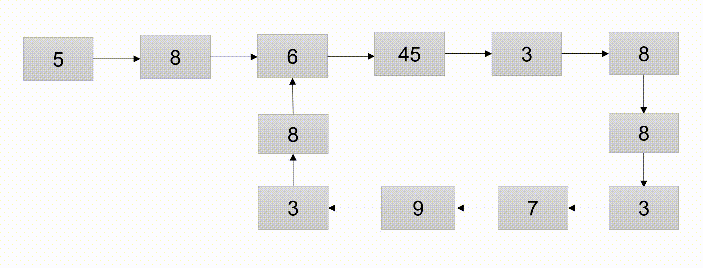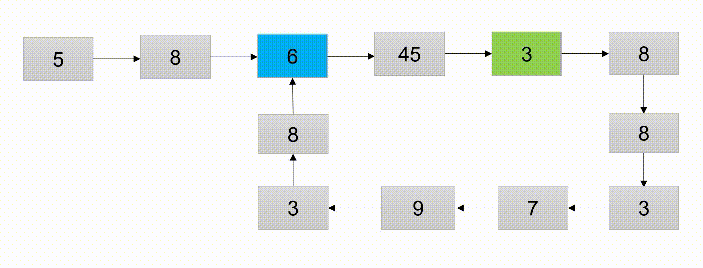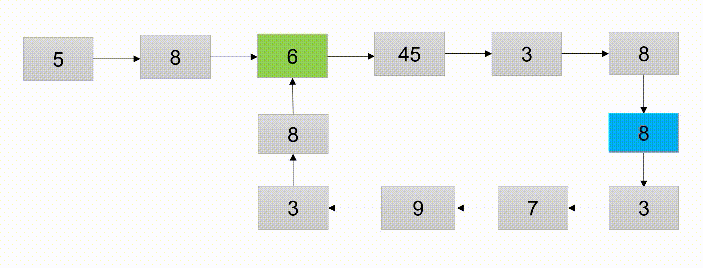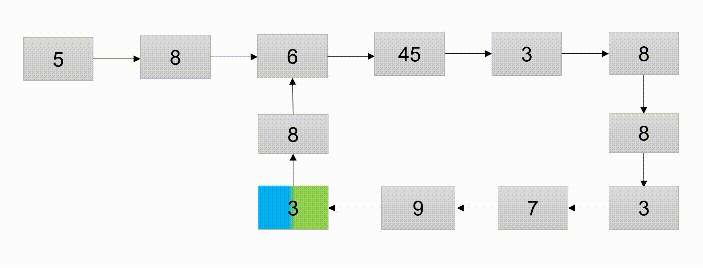
- 算法的时间复杂度:算法中涉及一个循环,时间复制度为O(n)
- 空间复杂度:临时变量占用的临时存储空间与问题规模无关,空间复制度为O(1)
3.3 分析该题目解题优势及难点。
- 题解优势:使用了快指针和慢指针解决了分析链表是否有环的问题。
- 延申:在查找倒数第k个数据元素时也可以使用类似的两个指针遍历的方式:一个指针1先走k个位置,之后指针2再和指针1一起开始移动,当指针1为空时,指针2所指的数据元素就是倒数第k个元素。
- 难点:是否考虑到快慢指针的使用