path.sh主要设定路径等
export KALDI_ROOT=`pwd`/../../.. [ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh export PATH=$PWD/utils/:$KALDI_ROOT/tools/openfst/bin:$PWD:$PATH [ ! -f $KALDI_ROOT/tools/config/common_path.sh ] && echo >&2 "The standard file $KALDI_ROOT/tools/config/common_path.sh is not present -> Exit!" && exit 1 . $KALDI_ROOT/tools/config/common_path.sh export LC_ALL=C 添加kaldi主目录路径 如果存在env.sh文件,则执行该脚本
添加openfst执行文件等目录路径 如果不存在common_path.sh文件,则打印报错,退出 执行 存在,则执行该脚本文件 按照C排序法则
#!/bin/bash #run.pl本地脚本,确定训练与识别命令 train_cmd="utils/run.pl" decode_cmd="utils/run.pl" #确定waves_yesno目录 if [ ! -d waves_yesno ]; then wget http://www.openslr.org/resources/1/waves_yesno.tar.gz || exit 1; # was: # wget http://sourceforge.net/projects/kaldi/files/waves_yesno.tar.gz || exit 1; tar -xvzf waves_yesno.tar.gz || exit 1; fi #
解压后,waves_yesno文件夹下的文件如下. 0_0_0_0_1_1_1_1.wav 0_0_1_1_0_1_1_0.wav ... 1_1_1_0_1_0_1_1.wav 总共60个wav文件,采样率都是8k,wav文件里每一个单词要么”ken”要么”lo”(“yes”和”no”)的发音,所以每个文件有8个发音,文件命名中的1代表yes发音,0代表no的发音.
#确定训练语料和测试语料 train_yesno=train_yesno test_base_name=test_yesno #清理相关目录 rm -rf data exp mfcc # Data preparation #数据准备
local/prepare_data.sh waves_yesno 内部实现代码: waves_dir=$1 将传入的文件目录赋值 ls -1 $waves_dir > data/local/waves_all.list 将wav文件夹所有文件名写入list文件中 local/create_yesno_waves_test_train.pl waves_all.list waves.test waves.train将waves_all.list中的60个wav文件名,分成两拨,各30个,分别记录在waves.test和waves.train文件中. 如waves.train文件内容如下: 0_0_0_0_1_1_1_1.wav
../../local/create_yesno_wav_scp.pl ${waves_dir} waves.test > ${test_base_name}_wav.scp
../../local/create_yesno_wav_scp.pl ${waves_dir} waves.train > ${train_base_name}_wav.scp
生成test_yesno_wav.scp和train_yesno_wav.scp 根据waves.test 和waves.train又会生成test_yesno_wav.scp和train_yesno_wav.scp两个文件. 这两个文件内容排列格式如下: 0_0_0_0_1_1_1_1 waves_yesno/0_0_0_0_1_1_1_1.wav 发音id 对应文件
../../local/create_yesno_txt.pl waves.test > ${test_base_name}.txt
../../local/create_yesno_txt.pl waves.train > ${train_base_name}.txt
然后生成train_yesno.txt和test_yesno.txt 这两个文件存放的是发音id和对应的文本. 0_0_1_1_1_1_0_0 NO NO YES YES YES YES NO NO
for x in train_yesno test_yesno; do
mkdir -p data/$x #创建文件夹
cp data/local/${x}_wav.scp data/$x/wav.scp #将local里面的scp(发音id 对应文件)和text(发音id 发音文本)文件保存再对应的训练或者测试文件夹里
cp data/local/$x.txt data/$x/text
cat data/$x/text | awk '{printf("%s global
", $1);}' > data/$x/utt2spk #将text(发音id 发音文本)转成 (发音id 发音人)
utils/utt2spk_to_spk2utt.pl <data/$x/utt2spk >data/$x/spk2utt #将utt2spk转成spk2utt
done
生成utt2spk和spk2utt
这个两个文件分别是发音和人对应关系,以及人和其发音id的对应关系.由于只有一个人的发音,所以这里都用global来表示发音.
utt2spk
<utt_id><speaker_id>
0_0_1_0_1_0_1_1 global
utt2spk
<speaker_id> <all_hier_utterences>
此外还可能会有如下文件(这个例子没有用到):
segments
包括每个录音的发音分段/对齐信息
只有在一个文件包括多个发音时需要
reco2file_and_channel
双声道录音情况使用到
spk2gender
将说话人和其性别建立映射关系,用于声道长度归一化.
以上生成的文件经过辅助操作均在:
data/train_yesno/
data/test_yesno/
目录结构如下:
data
├───train_yesno 训练文件夹
│ ├───text (发音id 发音文本)
│ ├───utt2spk (发音id 发音人)
│ ├───spk2utt (发音人 发音id)
│ └───wav.scp (发音id 发音文件)
└───test_yesno
├───text
├───utt2spk
├───spk2utt
└───wav.scp
#准备词典发音脚本
local/prepare_dict.sh 内部代码实现: mkdir -p data/local/dict #首先创建词典目录 input的两个txt应该是手工写的 非语言音发音拷贝到lexicon_words.txt cp input/lexicon_nosil.txt data/local/dict/lexicon_words.txt 将所有发音拷贝到lexicon.txt中 cp input/lexicon.txt data/local/dict/lexicon.txt 这个简单的例子只有两个单词:YES和NO,为简单起见,这里假设这两个单词都只有一个发音:Y和N。这个例子直接拷贝了相关的文件,非语言学的发音,被定义为SIL。 data/local/dict/lexicon.txt <SIL> SIL YES Y NO N cat input/phones.txt | grep -v SIL > data/local/dict/nonsilence_phones.txt grep -v 反向选择 echo "SIL" > data/local/dict/silence_phones.txt echo "SIL" > data/local/dict/optional_silence.txt echo "Dictionary preparation succeeded" lexicon.txt,完整的词位-发音对 lexicon_words.txt,单词-发音对 silence_phones.txt, 非语言学发音 nonsilence_phones.txt,语言学发音 optional_silence.txt ,备选非语言发音
#语音词典转成FST脚本
最后还要把字典转换成kaldi可以接受的数据结构-FST(finit state transducer)。这一转换使用如下命令 utils/prepare_lang.sh --position-dependent-phones false data/local/dict "<SIL>" data/local/lang data/lang 由于语料有限,所以将位置相关的发音disable。这个命令的各行意义如下: utils/prepare_lang.sh --position-dependent-phones false <RAW_DICT_PATH> <OOV> <TEMP_DIR> <OUTPUT_DIR> OOV存放的是词汇表以外的词,这里就是静音词(非语言学发声意义的词) 发音字典是二进制的OpenFst 格式,可以使用如下命令查看:
~/source_code/kaldi-trunk/egs/yesno/s5$ sudo ../../../tools/openfst-1.6.2/bin/fstprint --isymbols=data/lang/phones.txt --osymbols=data/lang/words.txt data/lang/L.fst
0 1 <eps> <eps> 0.693147182 0 1 SIL <eps> 0.693147182 1 1 SIL <SIL> 1 1 N NO 0.693147182 1 2 N NO 0.693147182 1 1 Y YES 0.693147182 1 2 Y YES 0.693147182 1 2 1 SIL <eps>
. utils/parse_options.sh
if [ $# -ne 4 ]; then
echo "usage: utils/prepare_lang.sh <dict-src-dir> <oov-dict-entry> <tmp-dir> <lang-dir>"
echo "e.g.: utils/prepare_lang.sh data/local/dict <SPOKEN_NOISE> data/local/lang data/lang"
echo "<dict-src-dir> should contain the following files:"
echo " extra_questions.txt lexicon.txt nonsilence_phones.txt optional_silence.txt silence_phones.txt"
echo "See http://kaldi-asr.org/doc/data_prep.html#data_prep_lang_creating for more info."
echo "options: "
echo " --num-sil-states <number of states> # default: 5, #states in silence models."
echo " --num-nonsil-states <number of states> # default: 3, #states in non-silence models."
echo " --position-dependent-phones (true|false) # default: true; if true, use _B, _E, _S & _I"
echo " # markers on phones to indicate word-internal positions. "
echo " --share-silence-phones (true|false) # default: false; if true, share pdfs of "
echo " # all non-silence phones. "
echo " --sil-prob <probability of silence> # default: 0.5 [must have 0 <= silprob < 1]"
echo " --phone-symbol-table <filename> # default: ""; if not empty, use the provided "
echo " # phones.txt as phone symbol table. This is useful "
echo " # if you use a new dictionary for the existing setup."
echo " --unk-fst <text-fst> # default: none. e.g. exp/make_unk_lm/unk_fst.txt."
echo " # This is for if you want to model the unknown word"
echo " # via a phone-level LM rather than a special phone"
echo " # (this should be more useful for test-time than train-time)."
echo " --extra-word-disambig-syms <filename> # default: ""; if not empty, add disambiguation symbols"
echo " # from this file (one per line) to phones/disambig.txt,"
echo " # phones/wdisambig.txt and words.txt"
exit 1;
fi
#准备语言模型
这里使用的是一元文法语言模型,同样要转换成FST以便kaldi接受。该语言模型原始文件是data/local/lm_tg.arpa,生成好的FST格式的。是字符串和整型值之间的映射关系,kaldi里使用整型值。 gsc@X250:~/kaldi/egs/yesno/s5$ head -5 data/lang/phones.txt 音素 <eps> 0 SIL 1 Y 2 N 3 #0 4 gsc@X250:~/kaldi/egs/yesno/s5$ head -5 data/lang/words.txt 词 <eps> 0 <SIL> 1 NO 2 YES 3 #0 4 可以使用如下命令查看生成音素的树形结构: phone 树
~/source_code/kaldi-trunk/egs/yesno/s5$ ~/kaldi-trunk/src/bin/draw-tree data/lang/phones.txt exp/mono0a/tree | dot -Tps -Gsize=8,10.5 | ps2pdf - ./tree.pdf
LM(language model)在data/lang_test_tg/。
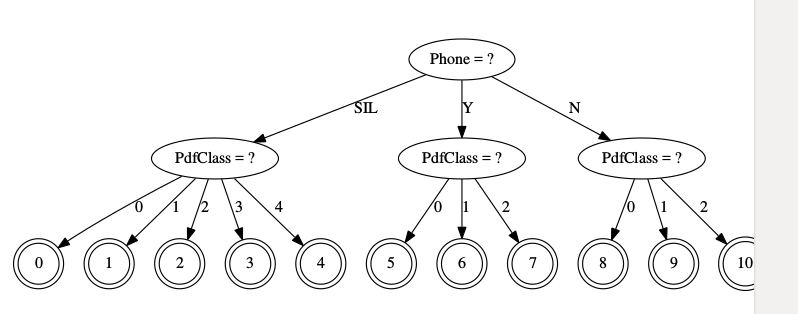
查看拓扑结构
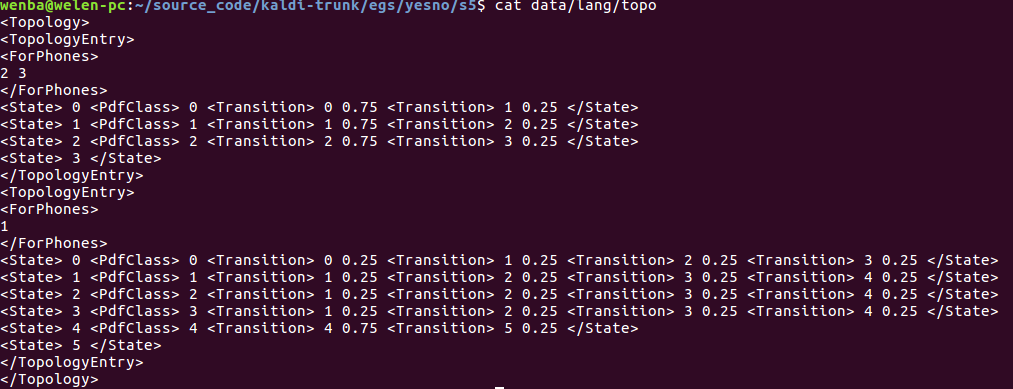
在<ForPhone></ForPhones>之间的数字,1表示silcense,2,3分别表示Y和N,这从拓扑图里也可以看出来。 1 2 3 在phones.txt有说明。
发音音素指定了三个状态从左到右的HMM以及默认的转变概率。为silence赋予5个状态。这个默认值再上面黄色标注那大块有说明。
当前状态只会往后面状态转移。
0.mdl模型的内容
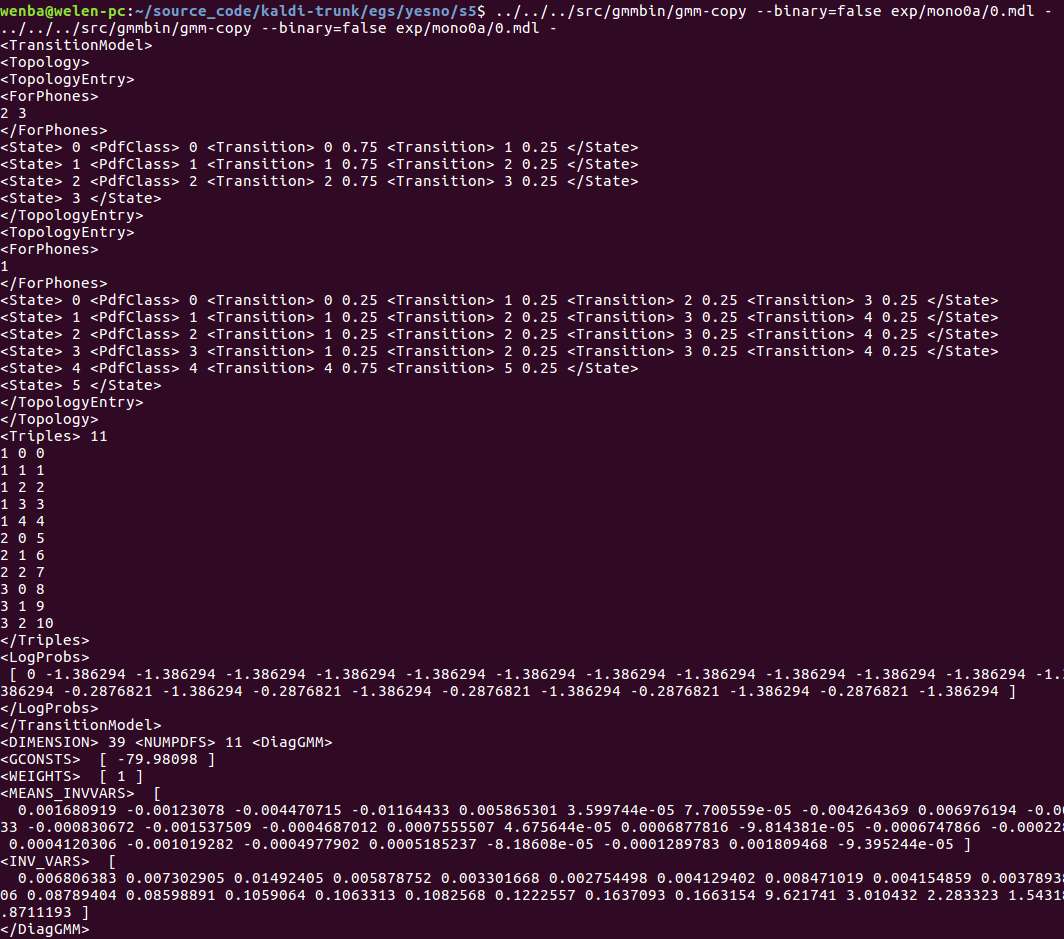
用1个hmm表示1个音素(此处是一个孤立词)。1个hmm根据发音类型,用5个(sil)或者3个(非sil)状态来表示,状态之间有转移。
状态状态用一个对角GMM来表示,但此处1个GMM只包含1个高斯。
特征维度为39
转移模型
topo
<TransitionModel> <Topology> <TopologyEntry> <ForPhones> 2 3 </ForPhones> <State> 0 <PdfClass> 0 <Transition> 0 0.75 <Transition> 1 0.25 </State> <State> 1 <PdfClass> 1 <Transition> 1 0.75 <Transition> 2 0.25 </State> <State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State> <State> 3 </State> </TopologyEntry> <TopologyEntry> <ForPhones> 1 </ForPhones> <State> 0 <PdfClass> 0 <Transition> 0 0.25 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 </State> <State> 1 <PdfClass> 1 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State> <State> 2 <PdfClass> 2 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State> <State> 3 <PdfClass> 3 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State> <State> 4 <PdfClass> 4 <Transition> 4 0.75 <Transition> 5 0.25 </State> <State> 5 </State> </TopologyEntry> </Topology>
音素 hmm状态
11个,见上面的树叶子节点;
音素标号 hmm状态标号 pdf标号
<Triples> 11
1 0 0
1 1 1
1 2 2
1 3 3
1 4 4
2 0 5
2 1 6
2 2 7
3 0 8
3 1 9
3 2 10
</Triples>
高斯模型
如下的20+1个log概率对应于11个phone(0-10)。
<LogProbs> [ 0 -1.386294 ... ] </LogProbs>
接下来是高斯模型的维度39维(没有能量),对角GMM参数总共11个。
<DIMENSION> 39 <NUMPDFS> 11 <DiagGMM>
在接下来就是对角高斯参数的均值方差权重等参数:
<GCONSTS> [ -79.98567 ] <WEIGHTS> [ 1 ] <MEANS_INVVARS> [ 0.001624335 ...] <INV_VARS> [ 0.006809053 ... ]
编译训练图

为每一个训练的发音编译FST,为训练的发句编码HMM结构。
kaldi 中表的概念
表是字符索引-对象的集合,有两种对象存储于磁盘
“scp”(script)机制:.scp文件从key(字串)映射到文件名或者pipe
“ark”(archive)机制:数据存储在一个文件中。
Kaldi 中表
一个表存在两种形式:”archive”和”script file”,他们的区别是archive实际上存储了数据,而script文件内容指向实际数据存储的索引。
从表中读取索引数据的程序被称为”rspecifier”,向表中写入字串的程序被称为”wspecifier”。
| rspecifier | meaning |
|---|---|
| ark:- | 从标准输入读取到的数据做为archive |
| scp:foo.scp | foo.scp文件指向了去哪里找数据 |
冒号后的内容是wxfilename 或者rxfilename,它们是pipe或者标准输入输出都可以。
表只包括一种类型的对象(如,浮点矩阵)
respecifier和wspecifier可以包括一些选项:
- 在respecifier中,ark,s,cs:- ,表示当从标准输入读操作时,我们期望key是排序过的(s),并且可以确定它们将会按排序过的顺序读取,(cs)意思是我们知道程序将按照排序过的方式对其进行访问(如何条件不成立,程序会crash),这是得Kaldi不要太多内存下可以模拟随机访问。
* 对于数据源不是很大,并且结果和排序无关的情形时,rspecifier可以忽略s,cs。
* scp,p:foo.scp ,p表示如果scp索引的文件存在不存在的情况,程序不crash(prevent of crash)。
* 对于写,选项t表示文本模式。
script文件格式是,<key> <rspecifier|wspecifier>如utt1 /foo/bar/utt1.mat
从命令行传递的参数指明如何读写表(scp,ark)。对于指示如何读表的字串称为“rspecifier”,而对写是”wspecifier”。
写表的实例如下:
| wspecifier | 意义 |
|---|---|
| ark:foo.ark | 写入归档文件foo.ark |
| scp:foo.scp | 使用映射关系写入foo.scp |
| ark:- | 将归档信息写入stdout |
| ark,t:|gzip -c > foo.gz | 将文本格式的归档写入foo.gz |
| ark,t:- | 将文本格式的归档写入 stdout |
| ark,scp:foo.ark, foo.scp | 写归档和scp文件 |
读表:
| rspecifier | 意义 |
|---|---|
| ark:foo.ark | 读取归档文件foo.ark |
| scp:foo.scp | 使用映射关系读取foo.scp |
| scp,p:foo.scp | 使用映射关系读取foo.scp,p:如果文件不存在,不报错 |
| ark:- | 从标准输入读取归档 |
| ark:gunzip -c foo.gz| | 从foo.gz读取归档信息 |
| ark,s,cs:- | 从标准输入读取归档后排序 |
eg: raw_mfcc_test_yesno.scp 内容: 1_0_0_0_0_0_0_0 /home/wenba/source_code/kaldi-trunk/egs/yesno/s5/mfcc/raw_mfcc_test_yesno.1.ark:16 1_0_0_0_0_0_0_1 /home/wenba/source_code/kaldi-trunk/egs/yesno/s5/mfcc/raw_mfcc_test_yesno.1.ark:8841 1_0_0_0_0_0_1_1 /home/wenba/source_code/kaldi-trunk/egs/yesno/s5/mfcc/raw_mfcc_test_yesno.1.ark:17718 发音id mfcc数据位置(mfcc特征从ark文件第n行开始读起) raw_mfcc_test_yesno.1ark 保存所有测试语音文件的mfcc 原始数据 cmvn_test_yesno.scp 内容:说话人global,因为只有一个人,所以只有1行,数据保存再ark文件中 global /home/wenba/source_code/kaldi-trunk/egs/yesno/s5/mfcc/cmvn_test_yesno.ark:7
特征提取和训练
特征提取,这里是做mfcc
steps/make_mfcc.sh --nj <N> <DATA_DIR> <LOG_DIR> <MFCC_DIR> --nj <N>是处理器单元数 <DATA_DIR>训练语料所在目录 <LOG_DIR>这个目录下记录了make_mfcc的执行log <MFCC_DIR>是mfcc特征输出目录
for x in train_yesno test_yesno; do steps/make_mfcc.sh --nj 1 data/$x exp/make_mfcc/$x mfcc steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc utils/fix_data_dir.sh data/$x done
该脚本主要执行的命令是:
~/kaldi/egs/yesno/s5$ head -3 exp/make_mfcc/train_yesno/make_mfcc_train_yesno.1.log #看log文件的前3行,head linux命令 #compute-mfcc-feats --verbose=2 --config=conf/mfcc.conf scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.1.scp ark:- | copy-feats --compress=true ark:- ark,scp:/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark,/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.scp copy-feats --compress=true ark:- ark,scp:/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark,/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.scp compute-mfcc-feats --verbose=2 --config=conf/mfcc.conf scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.1.scp ark:-
archive文件存放的是每个发音对应的特征矩阵(帧数X13大小)。
第一个参数scp:...指示在[dir]/wav1.scp里罗列的文件。

0_0_0_0_1_1_1_1 [
48.97441 -14.08838 -0.1344408 4.717922 21.6918 -0.2593708 -8.379625 8.9065 4.354931 17.00239 0.8865671 9.878274 2.105978
53.68612 -10.14593 -1.394655 -2.119211 13.08846 6.172102 8.67521 19.2422 0.4617066 5.210238 3.242958 2.333473 -0.5913677
通常在做NN训练时,提取的是40维度,包括能量和上面的一阶差分和二阶差分。
wenba@welen-pc:~/source_code/kaldi-trunk/egs/yesno/s5/mfcc$ ../../../../src/featbin/copy-feats ark:raw_mfcc_train_yesno.1.ark ark:- |../../../../src/featbin/add-deltas ark:- ark,t:- | head
../../../../src/featbin/add-deltas ark:- ark,t:-
../../../../src/featbin/copy-feats ark:raw_mfcc_train_yesno.1.ark ark:-
0_0_0_0_1_1_1_1 [
48.97441 -14.08838 -0.1344408 4.717922 21.6918 -0.2593708 -8.379625 8.9065 4.354931 17.00239 0.8865671 9.878274 2.105978 1.737444 1.14988 0.4575244 -0.4011359 -1.597765 0.7266266 2.309042 0.4257504 0.1381468 -3.825747 0.12343 -1.734139 0.5379874 0.5782275 0.1020916 -0.1619524 0.04889613 -1.136323 0.3202233 -0.7055103 -1.168674 0.1469378 0.2680922 -1.28895 -0.2633252 0.06172774
53.68612 -10.14593 -1.394655 -2.119211 13.08846 6.172102 8.67521 19.2422 0.4617066 5.210238 3.242958 2.333473 -0.5913677 2.134995 -0.08213401 -0.1649551 0.8477319 -3.646181 1.210454 -0.9891207 -1.523279 1.419143 -0.8481507 -1.178195 -2.021803 0.888494 0.2349093 0.07898982 -0.2755309 0.01829068 -0.4357649 0.007175058 -1.218953 -1.580022 0.1808465 1.43533 -1.377595 0.1183428 -0.5812462
然后归一化导谱特征系数
steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc生成的文件最终在mfcc目录下:
cmvn_test_yesno.ark cmvn_train_yesno.ark raw_mfcc_test_yesno.1.ark raw_mfcc_train_yesno.1.ark cmvn_test_yesno.scp cmvn_train_yesno.scp raw_mfcc_test_yesno.1.scp raw_mfcc_train_yesno.1.scp
详细各个命令意义,参考kaldi官网文档http://kaldi-asr.org/doc/tools.html
单音节训练
steps/train_mono.sh --nj <N> --cmd <MAIN_CMD> <DATA_DIR> <LANG_DIR> <OUTPUT_DIR> --cmd <MAIN_CMD>,如果使用本机资源,使用utils/run.pl。 steps/train_mono.sh --nj 1 --cmd "$train_cmd" --totgauss 400 data/train_yesno data/lang exp/mono0a
这将生成语言模型的FST,
使用如下命令可以查看输出:
fstcopy 'ark:gunzip -c exp/mono0a/fsts.1.gz|' ark,t:- | head -n 20

其每一列是(Q-from, Q-to, S-in, S-out, Cost)
解码和测试
图解码
首先测试文件也是按此生成。
然后构建全连接的FST。
utils/mkgraph.sh data/lang_test_tg exp/mono0a exp/mono0a/graph_tgpr
解码
# Decoding
steps/decode.sh --nj 1 --cmd "$decode_cmd"
exp/mono0a/graph_tgpr data/test_yesno exp/mono0a/decode_test_yesno
结果查看
for x in exp/*/decode*; do [ -d $x ] && grep WER $x/wer_* | utils/best_wer.sh; done如果对单词级别的对齐信息感兴趣,可以参考steps/get_ctm.sh
local/prepare_data.sh waves_yesno local/prepare_dict.sh utils/prepare_lang.sh --position-dependent-phones false data/local/dict "<SIL>" data/local/lang data/lang local/prepare_lm.sh #特征提取 #遍历训练与测试文件夹各个文件 #提取mfcc脚本 #cmvn统计脚本 # Feature extraction for x in train_yesno test_yesno; do steps/make_mfcc.sh --nj 1 data/$x exp/make_mfcc/$x mfcc steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc utils/fix_data_dir.sh data/$x done #单音素模型训练 # Mono training steps/train_mono.sh --nj 1 --cmd "$train_cmd" --totgauss 400 data/train_yesno data/lang exp/mono0a #图? # Graph compilation utils/mkgraph.sh data/lang_test_tg exp/mono0a exp/mono0a/graph_tgpr #解码 # Decoding steps/decode.sh --nj 1 --cmd "$decode_cmd" exp/mono0a/graph_tgpr data/test_yesno exp/mono0a/decode_test_yesno # for x in exp/*/decode*; do [ -d $x ] && grep WER $x/wer_* | utils/best_wer.sh; done
参考文档:http://blog.csdn.net/shichaog/article/details/73264152?locationNum=9&fps=1