更新至【58】,不定期更新,加入了自己的理解,如有不对,请指出。
【1】 new/delete和malloc/free的区别和联系?
1. 二者都可以动态分配和撤销内存。
2. new/delete是运算符,执行效率更高,而后者是标准函数库。
3. 针对对象时,new/delete会执行对象的构造/析构函数,而后者不会。
4. new返回数据类型指针,malloc返回void指针。
【2】 delete和delete [ ]的区别?
后者是delete处理数组时的用法,它会调用每个数组元素的析构函数,然后释放内容,例如:pt = new class[10]; delete [ ]pt;简单说就是:delete与new配套,delete [ ]与new [ ]配套。
【3】C++的特性?
封装、继承、多态。
【4】子类析构时会调用父类的析构函数吗?
1. 会,但是调用的次序是先派生类的析构,后基类的析构,也就是说在基类的的析构调用的时候,派生类的信息已经全部销毁了;
例如运行以下代码,输出:
constrcut parent
constrcut child
destrcut child
destrcut parent
1 class Parent 2 { 3 public: 4 Parent() 5 { 6 std::cout << "constrcut parent" << std::endl; 7 } 8 ~Parent() 9 { 10 std::cout << "destrcut parent" << std::endl; 11 } 12 }; 13 class Child : public Parent 14 { 15 public: 16 Child() 17 { 18 std::cout << "constrcut child" << std::endl; 19 } 20 ~Child() 21 { 22 std::cout << "destrcut child" << std::endl; 23 } 24 }; 25 26 int main() 27 { 28 Child child; 29 return 0; 30 }
2. 而构造函数的情况则相反:定义一个对象时先调用基类的构造函数、然后调用派生类的构造函数,例如:
Graduate(int age, string name, double wage):Student(age, name){mwage = wage;}
|__________|_________________________↑ ↑
|______________________________|
3. 倘若父类构造函数无参数时,子类也会调用父类的无参数构造函数,如1所示,输出
constrcut parent
constrcut child
destrcut child
destrcut parent
【5】 C++多态靠什么实现的?
广义上的多态包括静态/动态多态。
1. 其中前者靠函数/运算符重载实现,体现在程序编译的时候,因为通过单行语句就能判断调用那个函数(根据参数类型和个数等),所以程序在编译的时候就能确定调用那个函数;
2. 而动态多态靠虚函数实现,体现在程序运行的时候,因为只凭一行程序无法确定调用那个函数,例如pt->display();必须结合“上下文”,所以在程序运行的时候才能确定调用那个函数。
【6】 虚函数的作用
虚函数:在基类中用virtual标记的成员函数例如virtual void display();允许在派生类中重写(override),函数类型,名,参数必须一样,最好也加上virtual关键字,只有函数体不一样,而且重写的函数依旧被自动设为虚函数(不管你加不加virtual,但是最好加上)。
然后重点是,敲黑板:可以通过基类指针调用基类/派生类的同名函数,而不出错,意思是指针类型不用变,直接改变指向就行,例如下,如果不是虚函数,那么下例两次display都是调用的父类的display:
1 Graduate a; 2 Student *pt = new Student (); 3 pt -> display();//输出父类的display 4 pt = &a; 5 pt -> display();//输出子类的display
通过虚函数与定义一个指向基类对象类型的指针配合使用,就能方便的调用同一个类族中的不同class的同名函数,只需要改变指针的指向即可。那么问题来了,费这么大劲干嘛,上例中直接a.display();不就得了嘛?a.display();编译就知道调用那个函数了,但是pt->display(), 在编译的时候不知道,必须运行的时候“结合上下文”才能知道调用那个函数,这就是多态吧。
【7】 纯虚函数与虚函数的区别是,纯虚函数的作用?
1. 纯虚函数没有函数体,一般如virtual void display() =0;
2. 拥有纯虚函数的类成为抽象类,抽象类不能定义对象(即不能实例,比如动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。
3. 纯虚函数的作用主要是为一个类族提供一个公共接口。
【8】 引用和指针的区别?
1. 引用是一个变量的别名,而指针一个变量,存的是另一个变量的地址。
2. 引用不占用内存,声明一个引用也不是新定义了一个变量。
3. 引用在定义的时候必须初始化,而且以后不能赋值改变用作其他变量的别名,如下,而指针不是必须得初始化,随时赋值。
1 string str1 = "a"; 2 string str3 = "b"; 3 string &str2 = str1; 4 cout << "a = " << str1 << endl; 5 str2 = str3;//引用可以赋值,而且<=>str1 = str3;但是不能试图成为其他变量的别名,如: &str2 = str3; 6 cout << "a = " << str1 << endl; 7 //输出 a = a 8 // a = b
4. 指针可以为NULL,但是引用不能为空。
5. 不能建立数组的引用,意思是数组的元素不能是引用,而数组名是可以被引用的,如下:
1 int a[3] ={1111,999,88}; 2 int (&b)[3] = a; 3 std::cout << "a[2] = " << b[2] << std::endl;//输出88,没什么问题 4 // 还是auto大法好,自动型别推导 5 auto &c = a; 6 std::cout << "a[2] = " << c[2] << std::endl;//输出88,没什么问题
这样才是建立一个“数组元素是引用”的数组:int& b[3];但是C++不支持,编译失败。
*6. "sizeof引用"得到的是所指向的变量(对象)的大小,而"sizeof指针"得到的是指针本身的大小。
*7. 指针和引用的自增(++)运算意义不一样。
*8. 指针可以有多级,但是引用只能是一级(int **p;合法 而 int &&a是不合法的) (右值引用)
【9】 将引用作为函数参数有什么特点?
1. 可以用作输出参数,实现多变量的输出,普通函数只能return一个变量,太不方便了。
2. 相比使用指针达到上述效果,被调函数不要给指针形参(普通形参也是一样的)分配存储空间(深有体会,当形参是很大的一个数据结构时,使用引用参数,相当好,晕死,人家相比的是指针,又不是值传递),效率高,使用方便。
【10】 什么时候使用常引用?
如果既要利用引用提高程序的效率,又要保护传递给函数的数据不在函数中被改变,就应使用常引用。常引用声明方式:const 类型标识符 &引用名=目标变量名;
//例1 int a ; const int &ra = a; ra = 1; //错误 a = 1; //正确
【11】 将“引用”作为函数返回类型的格式,好处,要遵守的规则?
1. 格式:类型标识符 & 函数名(参数){函数体}
2. 好处
(1) 在内存中不产生被返回值的副本。
(2) 可将函数作为左值运算,例如:
int vals[10]; int &put(int n) { return vals[n]; } int main(int argc, char** argv) { put(0)=10; //以put(0)函数值作为左值,等价于vals[0]=10; put(9)=20; //以put(9)函数值作为左值,等价于vals[9]=20; cout << vals[0] << endl; cout << vals[9] << endl;
return 0; }
3. 注意事项:
(1) 不能返回函数内部局部变量的引用,因为离开函数体后,局部变量的生命周期结束,相应的引用也会失效。
(2) 不能返回函数内部new分配的内存的引用,因为当被函数返回的引用只是作为一个临时变量没有赋值一个实际变量,则new的内存就不会被释放,例如:
//下面是伪代码,没有将new的内存赋值给一个实际变量
cloud_ptr function() { return (new pcl::PointCloud<pcl::PointXYZI>); } std::cout << function()->points[0].x << std::endl;
【12】 struct和union的区别?
1. 二者都是由多个不同的数据类型成员组成, 但在任何同一时刻, union中只存放了一个被选中的成员, 而struct的所有成员都存在。
2. struct各成员都有自己的内存空间,struct的size等于所有成员的size之和;而union所有成员共用一个内存空间,其size等于长度最长的成员size。
3. 对于联合的不同成员赋值, 将会对其它成员重写, 原来成员的值就不存在了, 而对于结构的不同成员赋值是互不影响的。
【13】 重载,重写(覆盖),隐藏的区别?(overload,override,overwrite)
1. 重载是同层次(可以理解为“横向”)下的函数同名问题,但是不同参(类型,数量); 在编译的时候就确定调用那个函数,因此又被理解为“静态”多态。
2. 重写是基类与派生类(可以理解为“纵向”)下的函数同名问题,同名同参同类型,只有函数体不一样,基类中的同名函数必须加virtual关键字,派生类可加可不加(一般加上);在程序运行的时候才能确定调用哪个函数,因此又被理解为“动态”多态。
3. 隐藏也是“纵向”的问题,指的是派生类的函数屏蔽了与其同名的基类函数,规则如下:
(1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)。
4. 总结:“纵向”问题中,只有派生类与基类的同名、同参、同类型、并且基类有virtual关键字的时候才是重写,其他的“纵向”问题都是隐藏;而重载出现在“横向”问题中,例如:下面的程序中:
(1) 函数Derived::f(float) 重写了Base::f(float)。
(2) 函数Derived::g(int) 隐藏了Base::g(float),而不是重载。
(3) 函数Derived::h(float) 隐藏了Base::h(float),而不是重写。
#include <iostream.h> class Base { public: virtual void f(float x) {cout << "Base::f(float) " << x << endl;} void g(float x) {cout << "Base::g(float) " << x << endl;} void h(float x) {cout << "Base::h(float) " << x << endl;} }; class Derived : public Base { public: virtual void f(float x) {cout << "Derived::f(float) " << x << endl;} void g(int x) {cout << "Derived::g(int) " << x << endl;} void h(float x) {cout << "Derived::h(float) " << x << endl;} };
【14】 什么时候必须使用初始化表初始化对象?
1. 类的成员变量有const修饰
2. 类的成员为引用
3. 类的成员变量有“缺少默认构造函数的class类型”
4. 派生类在初始化时,必须在其初始化表中 调用 基类的构造函数,而且是先构造基类,后构造派生类(析构顺序则相反)。
1~3 的示例如下:


#include <iostream> using namespace std; class Base { public: Base(int p_nValue) : m_nValue(p_nValue) {} private: int m_nValue; }; class MyClass { public: MyClass(int p_nValue) : m_objBase(p_nValue),m_nNewVal(p_nValue) m_nVal(p_nValue) {} void printVal() { cout << "hello:" << p << endl;} private: const int m_nVal; int &m_nNewVal; Base m_objBase; }; int main(int argc ,char **argv) { int nValue = 45; MyClass objMyClass(nValue ); objMyClass.printVal(); }
4 的示例如下:
#include <iostream> using namespace std; class Parent { public: Parent(int p_nVal) : m_nVal(p_nVal) {} private: int m_nVal; }; class Child : public Parent { public: Child(int p_nVal) : Parent(p_nVal), m_nNewVal(p_nVal) {} void printVal() { cout << "hello:" << p << endl;} private: int m_nNewVal; }; int main(int argc ,char **argv) { int nValue = 45; Child objChild(nValue); objChild.printVal(); }
【15】 C++是不是类型安全的?
不是,两个不同类型的指针之间可以强制转换。
【16】 main函数执行之前,还会执行什么代码?
全局对象的构造函数会在main之前执行。
【17】 分别写出bool, int, float, 指针类型的变量a与“零”的比较
1. bool: if(a) / if(!a) //不可将布尔变量直接与TRUE、FALSE或者1、0进行比较。 根据布尔类型的语义,零值为“假”(记为FALSE),任何非零值都是“真”(记为TRUE);TRUE的值究竟是什么并没有统一的标准,例如Visual C++ 将TRUE定义为1,而Visual Basic则将TRUE定义为-1。
2. int : if(0 == a) / if(0 != a)
3. float: if(fabs(a) <= 1e-6) //无论是float还是double类型的变量,都有精度限制,所以一定要避免将浮点变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“ <=”形式。
4. 指针: if(nullptr == a) / if(nullptr != a)
【18】 const与#define的区别?
1. const 常量有数据类型,而宏常量没有数据类型。编译器可以对前者进行类型安全检查。而对后者只进行字符替换,没有类型安全检查,并且在字符替换可能会产生意料不到的错误(边际效应)。
2. 有些集成化的调试工具可以对const 常量进行调试,但是不能对宏常量进行调试。
【19-1】 内存分配的几种方式?
1. 从静态存储区域分配:内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在,例如全局变量,静态局部变量。
2. 在栈上创建:在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时,这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
3. 从堆上分配,亦称动态内存分配:程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
【19-2】由 C/C++ 编译的程序占用的内存分为几个部分?
1. 栈区(stack):由编译器自动分配释放 ,存放为运行函数而分配的局部变量、函数参数、返回数据、返回地址等,其操作方式类似于数据结构中的栈。
2. 堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由 OS 回收,分配方式类似于链表。
3. 全局区(静态区)(static):存放全局变量、静态数据,程序结束后由系统释放。
4. 文字常量区:常量字符串就是放在这里的,程序结束后由系统释放。
5. 程序代码区:存放函数体(类成员函数和全局函数)的二进制代码。
1 int a = 0; // 全局初始化区 2 char *p1; // 全局未初始化区 3 int main() 4 { 5 int b; // 栈 6 char s[] = "abc"; // 栈 7 char *p2; // 栈 8 char *p3 = "123456"; //123456� 在常量区, p3 在栈上。 9 static int c =0;// 全局(静态)初始化区 10 p1 = new char[10]; 11 p2 = new char[20]; 12 // new分配就在堆区。 13 strcpy(p1, "123456"); //123456� 放在常量区,编译器可能会将它与 p3 所指向的 "123456" 优化成一个地方。 14 }
【20】 基类的析构函数不是虚函数,会有什么后果?(深入理解虚函数的作用)
1. 当使用基类指针pt,去指向派生类对象而进行一些操作时,如果基类的析构函数不是虚函数,当 delete pt 时,只会执行基类的析构函数,不执行派生类的析构函数,如下,输出:
Delete class B
Delete class A
但是当删除class A中的virtual后,只输出:
Delete class A
class A { public: A() {} virtual ~A() { cout << "Delete class A" << endl; } }; class B : public A { public: B() {} ~B() { cout << "Delete class B" << endl; } }; int main(int argc, char** argv) { A *b = new B; delete b; return 0; }
2. 给基类的析构函数加virtual关键字后,上述情况中,delete pt 时,先析构派生类,再析构基类(与构造顺序相反)。
3. 总结:如果不需要用基类指针对派生类及对象进行操作,则不能定义虚函数,因为这样会增加内存开销,当类里面有定义虚函数的时候,编译器会给类添加一个虚函数表,里面来存放虚函数指针,这样就会增加类的存储空间。
4. 注意与【4】的区别,【4】中没有基类指针一说,所以也就不涉及虚函数。
【21】 static的作用?
1. 对普通的变量/函数
(1) 静态局部变量:存储位置从栈改为静态存储区;默认初始化为0;作用域没有改变,仍然是本函数体,但是离开函数体后,没有被销毁,仍然保留在内存中,直到程序结束,所以程序结束前再次进入函数时,static局部变量的值依然是上次执行完函数后的值。
(2) 静态全局变量:存储区和生命周期均未改变,改变的是作用域,普通全局变量作用域是整个工程,其他文件可以通过extern的形式(或者其他文件include有“外部调用声明它”的h文件)调用它,但是static全局变量只能在本文件使用,这样其他文件也可以用同名全局变量而不冲突。
(3) static的函数:作用域也是被限制在本文件,即便在其头文件声明后,也不能在其他包含这个头文件的文件中使用这个static函数;static函数在内存中只有一份,普通函数在每个被调用文件中维持一份拷贝。
2. 对类
(1) 静态成员变量:
a. 用static修饰类的数据成员会被该类的所有对象共享,包括派生类的对象,父类的static变量和函数在派生类中依然可用,但是受访问性控制(比如,父类的private域中的就不可访问),而且对static变量来说,派生类和父类中的static变量是共用空间的。
b. static成员变量必须在类外进行初始化,初始化格式: string Student::name = "wellp";而不能用构造函数、初始化表进行初始化,因为它并不属于某一个对象。
c. C++类的静态成员变量是必须初始化的,否则调用时编辑报错,但为什么要初始化呢?其实这句话“静态成员变量是需要初始化的”是有一定问题的,应该说“静态成员变量需要定义”才是准确的,而不是初始化,两者的区别在于:初始化是赋一个初始值,而定义是分配内存。静态成员变量在类中仅仅是声明,没有定义,所以要在类的外面定义,实际上是给静态成员变量分配内存。
d. 其意义在于为同一类族提供沟通的渠道,实现数据共享,避免了全局变量的使用,全局变量破坏了封装的原则,不符合OOP的要求。
(2) 静态成员函数:
a. 用static修饰成员函数,使这个类只存在这一份函数,所有对象共享该函数,不含this指针。
b. 其意义是为了处理(访问)静态成员变量,因为静态成员函数不含有this指针,所以不能访问非静态成员变量。
c. 静态成员变量/函数,可以通过类名访问(无对象生成时亦可),也可以通过对象访问。
d. 注意class中声明静态成员函数时带static,但是class外定义时,不能再加static,否则编译报错。
【22】 const和static为什么不能同时修饰成员函数?
1. C++编译器在实现const的成员函数的时候为了确保该函数不能修改类的实例的状态,会在函数中添加一个隐式的参数const this*。但当一个成员为static的时候,该函数是没有this指针的。也就是说此时const的用法和static是冲突的。
2. 我们也可以这样理解:两者的语意是矛盾的。static的作用是表示该函数只作用在类型的静态变量上,与类的实例没有关系;而const的作用是确保函数不能修改类的实例的状态,与类型的静态变量没有关系。因此不能同时用它们。
【23】 const的作用都有哪些?
1. 限定变量为不可修改。
2. 限定成员函数不可以修改任何数据成员。
3. const与指针:
(1) const char *p 表示指向的内容(即*p)不能改变,但是p可变。
(2) char * const p,就是将p声明为常指针,它的地址(即p)不能改变,但是*p可以改变。
(3) const char * const p, p和*p都不能变。
4.常对象不能调用该对象的非const成员函数。
const Time t1;//定义一个常对象 t1.get_time();//企图调用非const成员函数,非法,在类Time的声明中将该成员函数定义为常成员函数就可以了:int get_time() const;
【24】 多重继承和虚继承?
1. 多重继承:一个派生类继承自多个基类。 class E: public B, private C, protected D {};
2. 若上例中,B,C,D都继承自同一个基类A,则在E中会有3份一样的A的成员。所以用虚继承(又被称为菱形继承)解决这个问题如下,注意虚基类不是声明基类时声明的,而是在声明派生类时声明的。
class A {}; class B : virtual public A{}; class C : virtual public A{}; class D : virtual public A{};
class E: public B, private C, protected D {};
【25】 vector中的size()和capacity()的区别?
1. size()指容器当前拥有的元素个数(对应的resize(size)会在容器尾添加或删除一些元素,来调整容器中实际的内容,使容器达到指定的大小。)
2. capacity()指容器在必须分配存储空间之前可以存储的元素总数(对应的是reverse(size),给容器预留指定空间)。
3. 注意vector的capacity是2倍增长的。如果vector的大小不够了,比如现在的capacity是4,插入到第五个元素的时候,发现不够了,此时会给他重新分配8个空间,把原来的数据及新的数据复制到这个新分配的空间里。(会有迭代器失效的问题)
【26】 C++程序调用被C编译器编译后的函数,为什么要加extern"C"?
函数被C++编译器编译后在库中的名字与C语言的不同,假设某个函数原型为:void foo(int x, inty);该函数被C编译器编译后在库中的名字为: _foo,而C++编译器则会产生像: _foo_int_int 之类的名字。为了解决此类名字匹配的问题,C++提供了C链接交换指定符号 extern "C"。
【27】 头文件中的ifndef/define/endif 是干什么用的?
防止头文件被重复包含。
【28】 类的static变量在什么时候初始化?函数的static变量在什么时候初始化?
类的静态成员变量在类实例化之前就已经存在了,并且分配了内存;函数的static变量在执行此函数时进行初始化。
【29】 什么是内存泄漏?如何避免?
1. 用动态存储分配函数动态开辟的空间,在使用完毕后未释放,结果导致一直占据该内存单元即为内存泄露。
2. new/malloc的时候得确定在那里delete/free.
3. 对指针赋值的时候应该注意被赋值指针需要不需要释放.
4. 动态分配内存的指针最好不要再次赋值.
5. 上述的3、4 case用智能指针其实就可以很好地避免内存泄露
【30-1】 常用的排序算法和查找算法都有哪些?
1. 八大排序算法:快速排序 O(nlog2n)、堆排序 O(nlog2n)、归并排序 O(nlog2n)、选择排序 O(n2)、插入排序 O(n2)、冒泡排序 O(n2)、希尔排序 O(nlog2n)、基数排序 O(logRB,R是基数 个十百,B是真数 0~9)。
其中,快排、冒泡以及归并排序的demo code如下:
1 #include <iostream> 2 #include <vector> 3 4 void quick_sort(std::vector<int> &data, int left, int right) 5 { 6 if (left >= right) 7 { 8 return; 9 } 10 int i(left), j(right), pivot(data[left]); 11 while (i < j) 12 { 13 while (i < j && data[j] >= pivot) j--; 14 if (i < j) data[i++] = data[j]; 15 while (i < j && data[i] < pivot) i++; 16 if (i < j) data[j--] = data[i]; 17 } 18 data[i] = pivot; 19 quick_sort(data, left, i - 1); 20 quick_sort(data, i + 1, right); 21 } 22 23 24 std::vector<int> merge_sort(std::vector<int> data0, std::vector<int> data1) 25 { 26 std::vector<int> res; 27 int i = 0; 28 int j = 0; 29 while (i < data0.size() && j < data1.size()) 30 { 31 if (data0[i] < data1[j]) res.push_back(data0[i++]); 32 if (data0[i] >= data1[j]) res.push_back(data1[j++]); 33 } 34 while (i < data0.size()) res.push_back(data0[i++]); 35 while (j < data1.size()) res.push_back(data1[j++]); 36 return res; 37 } 38 39 40 void swap(int &a, int &b) 41 { 42 int tmp = a; 43 a = b; 44 b = tmp; 45 } 46 47 void bubble_sort(std::vector<int> &data) 48 { 49 for (int i = 0; i < data.size(); i++) 50 { 51 for (int j = 0; j < int(data.size()) - 1 - i; j++) 52 { 53 if (data[j] > data[j + 1]) 54 { 55 swap(data[j], data[j + 1]); 56 } 57 } 58 } 59 } 60 61 int main() 62 { 63 std::cout << "quick_sort:" << std::endl; 64 std::vector<int> data_raw = { 34, 65, 12, 43, 67, 5, 78, 10, 3, 70 }; 65 auto data = data_raw; 66 std::cout << "raw:" << std::endl; 67 for (auto d : data) 68 std::cout << d << ","; 69 std::cout << std::endl; 70 quick_sort(data, 0, data.size() - 1); 71 std::cout << "sort:" << std::endl; 72 for (auto d : data) 73 std::cout << d << ","; 74 std::cout << std::endl; 75 76 data = data_raw; 77 std::cout << " bubble_sort:" << std::endl; 78 std::cout << "raw:" << std::endl; 79 for (auto d : data) 80 std::cout << d << ","; 81 std::cout << std::endl; 82 bubble_sort(data); 83 std::cout << "sort:" << std::endl; 84 for (auto d : data) 85 std::cout << d << ","; 86 std::cout << std::endl; 87 88 std::cout << " merge_sort:" << std::endl; 89 std::vector<int> data0 = { 0, 2, 4, 6, 8, 10 }; 90 std::vector<int> data1 = { 1, 3, 5, 7, 9 }; 91 std::cout << "raw:" << std::endl; 92 for (auto d : data0) std::cout << d << ", "; 93 std::cout << std::endl; 94 for (auto d : data1) std::cout << d << ", "; 95 std::cout << std::endl; 96 auto res = merge_sort(data0, data1); 97 std::cout << "sort:" << std::endl; 98 for (auto d : res) std::cout << d << ", "; 99 std::cout << std::endl; 100 101 return 0; 102 }
输出:
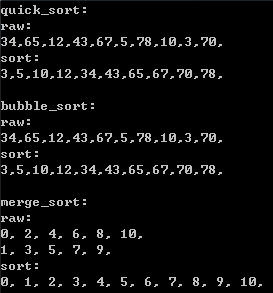
2. 七大查找算法: 顺序查找、二分查找、插值查找、斐波那契查找、树表查找、分块查找、哈希查找。
其中哈希查找,是通过计算数据元素的存储位置进行查找的一种方法:若查找关键字为 key,则其值存放在 f(key) 的存储位置上,由此,不需比较便可直接取得所查记录,哈希查找与线性表查找和树表查找最大的区别在于,不用数值比较,时间复杂度基本是O(1)。
【30-2】 排序算法中那些是稳定的?
两个相同的数字,排序结束后,二者的相对位置不发生变化,即为稳定的排序算法。
选择排序、快速排序、堆排序、希尔排序 不是稳定的排序算法;
冒泡排序、插入排序、归并排序、基数排序 是稳定的排序算法。
【31】 什么函数不能为虚函数?什么函数不能是重载函数?
1.构造函数,主要从使用的角度来解释:虚函数的意义在于先定义一个基类指针pt,然后让pt去指向派生类对象,进而就可以调用派生类的成员函数了,而构造函数不能被调用,在派生类实例化的时候就自动调用构造函数了。
2.析构函数没有参数,所以也就不能重载
【32】 常用的数据结构有哪些?
1. 线性数据结构: 数组,链表,队列(先进先出),栈(先进后出)。
2. 非线性数据结构: 树,图。
【33】 二叉树的遍历?
1. 二叉树的遍历,就是按照某条搜索路径访问树中的每一个结点,使得每个结点均被访问一次,而且仅被访问一次。
2. 常见的遍历次序如下,时间复杂度都是 O(N):
(1) 先序遍历:先访问根结点,再访问左子树,最后访问右子树
(2) 中序遍历:先访问左子树,再访问根结点,最后访问右子树
(3) 后序遍历:先访问左子树,再访问右子树,最后访问根结点
3. 还有BFS和DFS,时间复杂度也是O(N),详见【58】
【34】 switch的参数类型不能是?
实型,ps:说这么高大上,实型又称实数或浮点数,有float 和 double两种,因为浮点数的不能精确表示一个数,所以不能用于“等式”判断。
【35】 频繁出现的短小函数, 在c和c++中分别如何实现?
c中使用宏定义, c++中使用inline内置函数。
//C
#define f1(a, b) (a + b * 2)
//C++
inline int f2(int a, int b)
{
return a + b * 2;
}
std::cout << f1(5, 10) << std::endl;//输出25
std::cout << f2(5, 10) << std::endl;//输出25
【36】 定义一个宏时应注意什么?
定义部分的每个形参和整个表达式都必须用括号括起来,以避免不可预料的错误。
例如:
1.![]()
2.![]()
【37】 struct 和 class 的区别?
1. 默认成员属性:class的成员默认是private的,而struct 的成员默认是public的。
2. 默认继承方式:声命派生类时,如果不写继承方式,对于class来说默认是private继承, struct就是public继承了。
【38】 如何判断一段程序是由C 编译程序还是由C++编译程序编译的?
#ifdef __cplusplus cout << "c++" << endl; #else cout << "c" << endl; #endif
【39】 简述数组与指针的区别?
1. 数组要么在静态存储区被创建(如全局数组),要么在栈上被创建;指针可以随时指向任意类型的内存块。
2. 用运算符sizeof(p)p是数组名,可以计算出数组的容量(字节数); sizeof(p) p为指针,得到的是一个指针变量的字节数,而不是p 所指的内存容量。
【40】 #include <file.h> 和 #include "file.h" 有什么区别?
1. 对于#include <file.h> ,编译器从标准库路径开始搜索。
2. 对于#include “file.h” ,编译器从用户的工作路径开始搜索。
【41】 vector迭代器失效的几种情况和原因?
1. 插入元素:vector在内存是连续连续存储的,当插入数据可能会超过vector.capacity()时,vector重新被分配内存来扩容1倍,在新的内存空间中复制原理来的元素,并插入新的元素,最后撤销原来的空间,迭代器本质是指针,内存地址都变了,迭代器当然会失效;当然如果没有重新分配内存,那么插入点之前的iterator有效,插入点之后的iterator失效。
2. 删除元素:导致指向删除点及其后元素的迭代器全部失效,因为删除一个元素导致后面所有的元素会向前移动一个位置,所以不能使用erase(iter++)的方式,还好erase方法可以返回下一个有效的iterator,所以要
iter = v.erase(iter);
【42】 什么是仿函数functor?
仿函数(functor),就是使一个类的使用看上去像一个函数。其实现就是类中实现一个括号的运算符重载,operator(),这个类就有了类似函数的行为,就是一个仿函数类了。
class CircleFittingCost { public: CircleFittingCost(double x, double y) : x_(x) , y_(y) { } template <typename T> bool operator() (const T* const a, const T* const b, const T* const r, T* e) const { e[0] = (T(x_) - a[0]) * (T(x_) - a[0]) + (T(y_) - b[0]) * (T(y_) - b[0]) - r[0] * r[0]; return true; } private: double x_, y_; };
int main ()
{
//CircleFittingCost* cir = new CircleFittingCost(10.3351, 5.678);
//cir->operator()<double>(&a, &b, &r, &error);
//下面的执行结果和上面的一样,但是下面的对象cir使用时有了类似函数的功能,所谓仿函数
CircleFittingCost cir(10.3351, 5.678);
cir(&a, &b, &r, &error);
}
【43】 什么是智能指针?
智能指针和普通指针的区别在于智能指针实际上是对普通指针加了一层封装机制,这样的一层封装机制的目的是为了使得智能指针可以方便的管理一个对象的生命期,防止内存泄露。
在C++中,我们知道,如果使用普通指针来创建一个指向某个对象的指针,那么在使用完这个对象之后我们需要自己删除它,例如:
ObjectType* temp_ptr = new ObjectType(); temp_ptr->foo(); delete temp_ptr;
很多材料上都会指出说如果程序员忘记在调用完temp_ptr之后删除temp_ptr,那么会造成一个悬挂指针(dangling pointer),也就是说这个指针现在指向的内存区域其内容程序员无法把握和控制,也可能非常容易造成内存泄漏。
可是事实上,不止是“忘记”,在上述的这一段程序中,如果foo()在运行时抛出异常,那么temp_ptr所指向的对象仍然不会被安全删除。
在这个时候,智能指针的出现实际上就是为了可以方便的控制对象的生命期,在智能指针中,一个对象什么时候和在什么条件下要被析构或者是删除是受智能指针本身决定的,用户并不需要管理。
根据具体的条件,我们一般会讨论这样几种智能指针,而如下所说的这些智能指针也都是在boost library里面定义的。
【44】 C++函数模板的显式/隐式调用?
template <class T> inline const T& c_max (const T& a, const T& b) { return a < b ? b : a; } int main(int argc, char** argv) { c_max(1, 2);//正确,模板的隐式调用,根据参数类型决定函数模板的编译 c_max(1, 2.1);//编译错误 educed conflicting types for parameter ‘const T’ (‘int’ and ‘double’)
c_max<double>(1, 2.1);//正确,模板的显式调用 }
【45】 map的四个常见问题?
1. 为何map和set的插入删除效率比用其他序列容器高?
map和set的内部数据结构是红黑树,一种会自动有序的平衡查找二叉树(对key自动排序的过程中,自动保持树的平衡,可以使得查找的效率维持在O(logN)左右,根据key索引对应的value,索引过程与std::pair类似。可以看出std::map相比于std::pair,除了具有“关联”特性之外,还有更加复杂高效的功能如count find,而这些功能都是通过对key建立的红黑树实现的,所以可以认为: map = set + pair),所有元素都是以红黑树节点(如下)的方式来存储,其节点结构和链表差不多,指向父节点和子节点,结构图可能如下:
A / B C / / D E F G
插入删除元素时,不需要做内存拷贝和内存移动,只需要改变相关指针的指向,所以效率高。
2. 为何每次insert之后,以前保存的iterator不会失效?
iterator这里就相当于指向节点的指针,插入时,内存没有变,指向内存的指针怎么会失效呢。
3. 当数据元素增多时(10000到20000个比较),map和set的插入和搜索速度变化如何?
10000时搜索速度是log210000,13.28次左右;20000时只增加了一次,也就是14.28。
也就是时间复杂度是O(logN)
【46】 STL的sort函数实现原理?
STL中的sort并非只是普通的快速排序,除了对普通的快速排序进行优化,它还结合了插入排序和堆排序。根据不同的数量级别以及不同情况,能自动选用合适的排序方法。当数据量较大时采用快速排序,分段递归。一旦分段后的数据量小于某个阈值,为避免递归调用带来过大的额外负荷,便会改用插入排序。而如果递归层次过深,有出现最坏情况的倾向,还会改用堆排序。
【47】 C++标准库、std、STL、boost都是什么?
1. C++标准库
即C++ Standard Library,是类库和函数库的集合,其使用核心语言写成,由C++标准委员会指定,并不断更新维护,简单来说,除了支持文件之外,C++标准库还主要包含了三个部分:C的函数库、C++ IO库、STL。
2. std
In fact, all identifiers of the C++ standard library are defined in a namespace called std.
而STL被容纳与C++ Standard Library里,即std和STL均属于 C++ Standard Library里,STL是其中的一部分内容,std是一个命名空间,C++标准库的所有内容都在std命名空间下。
3. STL
即Standard Template Library 标准模板库, 是C++标准库的一部分。
STL包括容器(containers)、算法(algorithms)、迭代器(iterators)。(其实还有不太常用的空间适配器(allocator)、配接器(adapters)、仿函数(functors))
(1) 容器
序列式容器:vector,list,deque等
关联式容器:map、set、multimap、multiset,内部结构是一颗红黑树。所谓关联,指每个元素都有key和一个value。
无序关联式容器:unordered_map、unordered_set,内部结构是哈希表,无序,查找插入删除的平均时间复杂度O(1),存储也比红黑树大一些。
*容量适配器:stack(栈)、queue(队列)、priority_queue(优先队列)。
(2) 算法,sort,find,count,for_each等,与各个容器相关联。
(3) 迭代器,是STL的精髓。可以这样描述,它提供了一种方法,使之能够按照顺序访问某个容器所含的各个元素,但是无需暴露该容器的内部结构,它将容器和算法分开,好让这二者独立设计。
4. boost
Boost库是一个可移植、提供源代码的C++库,作为标准库的后备,是C++标准化进程的开发引擎之一。 Boost库由C++标准委员会库工作组成员发起,其中有些内容有望成为下一代C++标准库内容。在C++社区中影响甚大,是不折不扣的“准”标准库。Boost由于其对跨平台的强调,对标准C++的强调,与编写平台无关。大部分boost库功能的使用只需包括相应头文件即可,少数(如正则表达式库,文件系统库等)需要链接库。但Boost中也有很多是实验性质的东西,在实际的开发中实用需要谨慎。
【48】 描述几个C++11的新特性?
1. auto
auto的自动类型推导,用于从初始化表达式中推断出变量的数据类型,或者理解为有=,才可以用auto,显而易见嘛
auto a; // 错误,auto是通过初始化表达式进行行类型推导,如果没有初始化表达式,就无无法确定a的类型
auto i = 1;
auto d = 1.0;
auto str = "Hello World";
auto ch = 'A';
auto func = less<int>();
vector<int> iv;
auto ite = iv.begin();
auto p = new foo() // 对自自定义类型进行行类型推导
2. decltype
decltype实际上有点像auto的反函数,auto可以让你声明一个变量,而decltype则可以从一个
变量或表达式中得到类型,有实例如下:
int x = 3;
decltype(x) y = x;
3. nullptr
nullptr是为了解决原来C++中NULL的二义性问题而引进的一种新的类型,因为NULL实际上代表的是0。
4. 序列for循环
在C++中for循环可以使用类似java的简化的for循环,可以用于遍历数组,容器,string以及由begin和end函数定义的序列(即有Iterator),示例代码如下:
map<string, int> m{{"a", 1}, {"b", 2}, {"c", 3}}; for (auto p : m) { cout << p.first << " : " << p.second << endl; }
【49】 引用实现多态的方式?
引用是除基类指针外另一个可以产生多态效果的手段。这意味着,一个基类的引用可以指向它的派生类实例。
class A {...}; class B : public A {...}; B b; A &Ref = b;//用派生类对象初始化基类对象的引用
Ref 只能用来访问派生类对象中从基类继承下来的成员,是基类引用指向派生类。如果A类中定义有虚函数,并且在B类中重写了这个虚函数,就可以通过Ref产生多态效果。
【50】 STL erase()的陷阱
该问题主要分为两类讨论,详见不破不立的blog
1. list、set、map容器:此类容器内部不是连续存储,erase()只会使得当前元素的迭代器失效,而对其他元素的迭代器没有影响。
2. vector、deque容器:这类容器是连续存储,erase()删除一个元素导致当前以及后面所有的元素会向前移动一个位置。
但是由于上述两种容器的erase()都可以返回一个正确的下一个迭代器,所以遍历容器删除元素都可以通过以下方式:
std::list<int> List;
for(auto itList = List.begin(); itList != List.end();) { if(WillDelete(*itList)) { itList = List.erase( itList); } else { itList++;
} }
【51】 vector、list和deque的区别?
1. vector:连续存储结构,实际上是封装的数组数据结构;随机访问效率高,如a[10];高效率地在尾端插入/删除操作, push_back, pop_back。
2. list:非连续存储结构,实际上是封装的双向链表数据结构;随机访问效率低,需要遍历整个链表;在任何位置插入/删除元素效率都很高, insert, erase(双向链表的特性,单链表就不行,见【56】)。
3. deque:即双端队列 double-end queue,连续存储结构;随机访问效率高,如a[10];高效率地首尾两端插入/删除操作, push_back, pop_back, push_front, pop_front。
因此在实际使用时,如何选择这三个容器中哪一个,应根据你的需要而定,一般应遵循下面的原则:
a. 如果你需要高效的随机存取,而不在乎插入和删除的效率,使用vector。
b. 如果你需要大量的插入和删除,而不关心随机存取,则应使用list。
c. 如果你需要随机存取,而且关心两端数据的插入和删除,则应使用deque。
【52】 公共继承、保护继承和私有继承各是什么意思?
1. public继承方式
(1) 基类中所有public成员在派生类中为public属性;
(2) 基类中所有protected成员在派生类中为protected属性;
(3) 基类中所有private成员在派生类中不可访问。
2. protected继承方式
(1) 基类中的所有public成员在派生类中为protected属性;
(2) 基类中的所有protected成员在派生类中为protected属性;
(3) 基类中的所有private成员在派生类中仍然不可访问。
3. private继承方式
(1) 基类中的所有public成员在派生类中均为private属性;
(2) 基类中的所有protected成员在派生类中均为private属性;
(3) 基类中的所有private成员在派生类中均不可访问。
class Base { public: int para_base_pub; protected: int para_base_pro; private: int para_base_pri; } class Sub_0 : public Base { } class Sub_1 : protected Base { } class Sub_2 : private Base { } void main() { Sub_0 sub_0; Sub_1 sub_1; Sub_2 sub_2; sub_0.para_base_pub = 1;//right sub_0.para_base_pro = 1;//wrong sub_0.para_base_pri = 1;//wrong sub_1.para_base_pub = 1;//wrong sub_1.para_base_pro = 1;//wrong sub_1.para_base_pri = 1;//wrong sub_2.para_base_pub = 1;//wrong sub_2.para_base_pro = 1;//wrong sub_2.para_base_pri = 1;//wrong }
【53】 解释一下STL中的优先队列(priority_queue)的数据结构
优先队列容器与队列一样,只能从队尾插入元素,从队首删除元素。但是它有一个特性,就是队列中最大(最小)的元素总是位于队首,所以出队时,并非按照先进先出的原则进行,而是将当前队列中最大(最小)的元素出队。这点类似于给队列里的元素进行了由大到小(由小到大)的顺序排序。
优先队列的实现中是通过堆数据结构,最大优先队列可以选用大堆,最小优先队列可以选用小堆来实现。
std::priority_queue<int, vector<int>, less<int>> big; std::priority_queue<int, vector<int>, greater<int>> small;
【54】 C++模板中声明和定义是否可以分开存放在.h和.cpp文件中
不可以,编译分离的问题,详细原因,这个链接看看吧。
翻看开源项目的源码使用模板一般有几种,一种就是把所有代码全放在.h里,另一种是写个.h然后在.h最下面加上#include"XXX.hpp" XXX.hpp里是模板函数的函数体
【55】 平衡二叉树、满二叉树、完全二叉树、二叉查找树的概念
1.平衡二叉树:左右子树的深度差<=1,并且左右子树都是平衡二叉树
2.满二叉树以及完全二叉树:

3.二叉查找树:中序遍历为有序数组的二叉树,哈哈。
【56】 单链表的插入、删除和查找的时间复杂度
1. 单链表的查找时间复杂度没啥好说的,O(N)。
2. 插入:前插O(N),后插O(1)。
3. 删除:删除给定节点O(N),但是可以用后节点覆盖的方式,实现时间复杂度O(1):
node->value = (node + 1)->value; node->next = (node + 1)->next;
free (node + 1);
其中插入删除为什么要分情况讨论,请参看CSDN的一篇博客,在单向链表中,求“后继”的时间复杂度是O(1),而求“前驱”的时间复杂度是O(N),而双向链表的出现就是为了解决这一问题,双向链表的每个node有两个指针,分别指向前一个node和后一个node,从而达到前插后插,以及删除node的时间复杂度都是O(1)。
【57】STL的list
STL的list封装的是一个双向链表。
【58】二叉树的深度优先遍历(dfs)和广度优先遍历(bfs)
bfs其实就是牛客上的“按层打印二叉树的的node”,然后dfs就是把bfs中的queue换成stack,然后入栈顺序与入队列的顺序相反,具体的看CSDN的博友博客,其中的例子如下:

1 #include <iostream> 2 #include <stdlib.h> 3 #include <malloc.h> 4 #include <stack> 5 #include <queue> 6 7 struct Node { 8 char data; 9 struct Node* lchild; 10 struct Node* rchild; 11 }; 12 13 int index = 0; 14 void tree_node_constructor(Node* &root, char data[]){ 15 char e = data[index++]; 16 if (e == '#'){ 17 root = NULL; 18 } 19 else{ 20 root = (Node*)malloc(sizeof(Node)); 21 root->data = e; 22 tree_node_constructor(root->lchild, data); 23 tree_node_constructor(root->rchild, data); 24 } 25 } 26 27 //DFS 28 void depth_first_search(Node* root){ 29 if (root == NULL) return; 30 std::stack<Node*> sta; 31 sta.push(root); 32 while (!sta.empty()) 33 { 34 auto tmp = sta.top(); 35 sta.pop(); 36 std::cout << tmp->data << ", "; 37 if (tmp->rchild) sta.push(tmp->rchild); 38 if (tmp->lchild) sta.push(tmp->lchild); 39 } 40 } 41 42 //BFS 43 void breadth_first_search(Node* root){ 44 if (root == NULL) return; 45 std::queue<Node*> que; 46 que.push(root); 47 while (!que.empty()) 48 { 49 auto tmp = que.front(); 50 que.pop(); 51 std::cout << tmp->data << ", "; 52 if (tmp->lchild) que.push(tmp->lchild); 53 if (tmp->rchild) que.push(tmp->rchild); 54 } 55 } 56 57 //Preorder traversal 58 void preorder_traversal(Node* root) 59 { 60 if (root == NULL) return; 61 std::cout << root->data << ", "; 62 preorder_traversal(root->lchild); 63 preorder_traversal(root->rchild); 64 } 65 66 int main() { 67 char data[15] = { 'A', 'B', 'D', '#', '#', 'E', '#', '#', 'C', 'F', '#', '#', 'G', '#', '#' }; 68 Node* tree; 69 tree_node_constructor(tree, data); 70 std::cout << "DFS: "; 71 depth_first_search(tree); 72 std::cout << " BFS: "; 73 breadth_first_search(tree); 74 std::cout << " Preorder:"; 75 preorder_traversal(tree); 76 return 0; 77 }
输出:

