本文使用Spark的版本为:spark-2.4.0-bin-hadoop2.7.tgz。
spark的集群采用3台机器进行搭建,机器分别是server01,server02,server03。
其中:server01,server02设置为Master,server01,server02,server03为Worker。
1.Spark
下载地址:
http://spark.apache.org/downloads.html
选择对应的版本进行下载就好,我这里下载的版本是:spark-2.4.0-bin-hadoop2.7.tgz。
2.上传及解压
2.1 下载到本地后,上传到Linux的虚拟机上
scp spark-2.4.0-bin-hadoop2.7.tgz hadoop@server01:/hadoop
2.2 解压
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
2.3 重命名
mv spark-2.4.0-bin-hadoop2.7 spark
3.配置环境
进入spark/conf目录
3.1 复制配置文件
cp slaves.template slaves cp spark-env.sh.template spark-env.sh
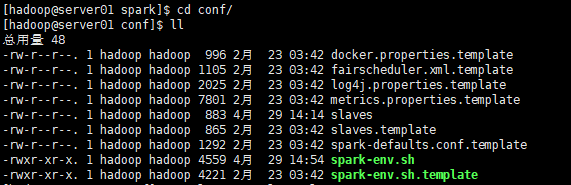
3.2 修改slaves配置文件
spark集群的worker conf配置 slaves
server01
server02
server03
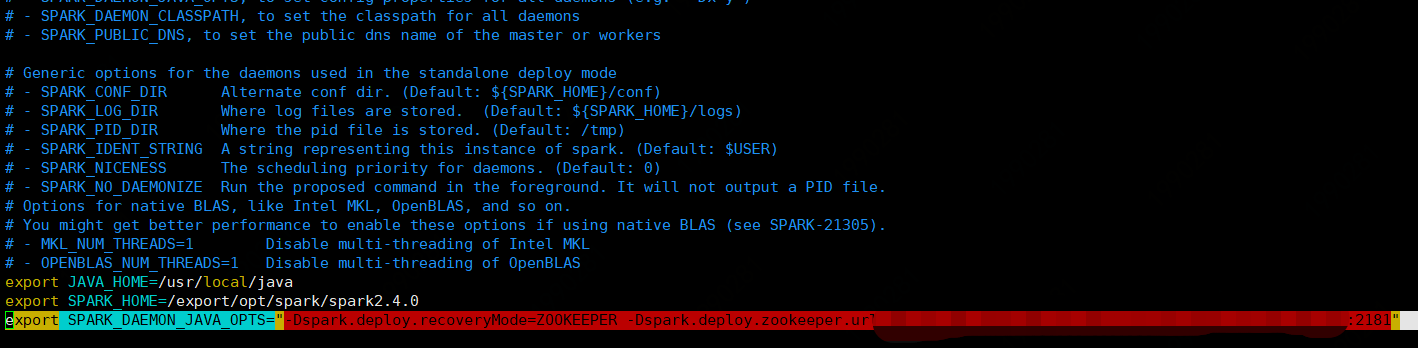
3.3 修改spark-env.sh配置文件
# java环境变量 export JAVA_HOME=/usr/local/java #spark home export SPARK_HOME=/export/opt/spark/spark2.4.0 # spark集群master进程主机host export SPARK_MASTER_HOST=server01 # 配置zk 此处可以独立配置zk list,逗号分隔 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=xxx.xxx.xxx.xxx:2181, xxx.xxx.xxx.xxx:2181……"
如下图
3.4 下发到server02和server03机器上
scp -r /hadoop/spark hadoop@server02:/hadoop scp -r /hadoop/spark hadoop@server03:/hadoop
3.5 修改server02机器上的spark-env.sh的SPARK_MASTER_HOST参数信息
# 增加备用master主机,改为server02,将自己设置为master(备用)
export SPARK_MASTER_HOST=server02

3.6 配置环境变量
给server01,server02,server03机器上配置spark的环境变量
export SPARK_HOME=/export/opt/spark/spark2.4.0 export PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin #使配置环境生效 source /etc/profile
4. 启动Spark集群
在server01机器上,进入spark目录
4.1 分别启动master和slaves进程
# 启动master进程 sbin/start-master.sh # 启动3个worker进程,也可以每个机器独立启动需要输入两个master地址 sbin/start-slaves.sh
jps查看进程1有既有master又有Worker,2,3只有Worker

4.2 直接使用start-all.sh启动
sbin/start-all.sh

4.3 手动启动server02机器上的master进程
进入spark目录
sbin/start-master.sh
我们可以使用stop-all.sh杀死spark的进程
sbin/stop-all.sh
web页面展示
在浏览器中输入
server01:8080
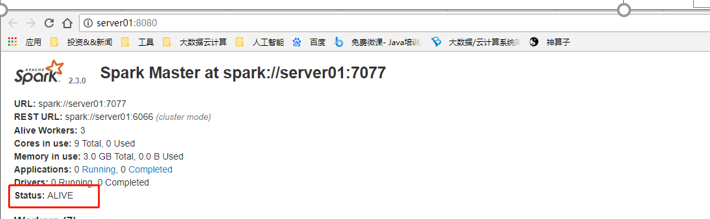
Status:ALIVE 说明master为主Master
server02:8080

总结
部署完成后可以尝试kill掉1的master,然后需要等几分钟后会重启备用master,此时备用切换为主。
另外如果application被杀掉或者jvm出现问题,还可以通过增加参数 --supervise(需要安装,pip install supervise)可以重新启动application。