hdfs的优缺点比较:


架构图解分析:
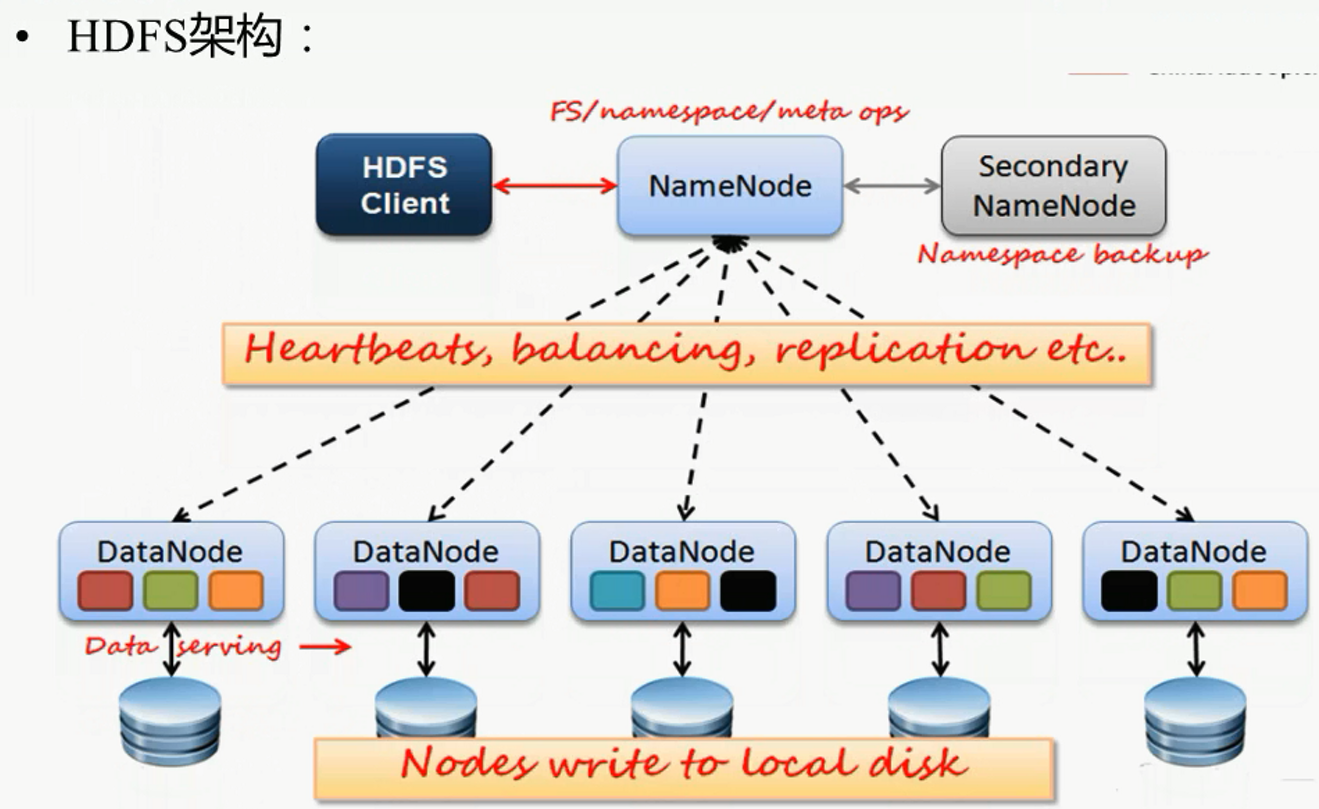
nameNode的主要任务:
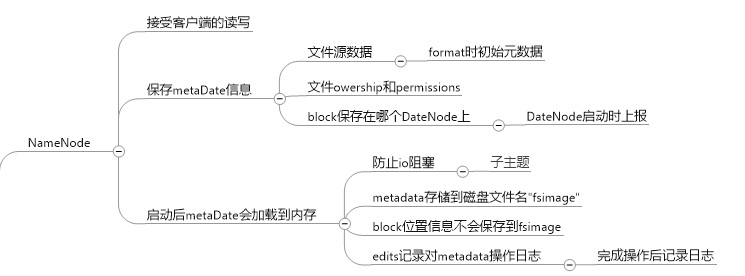
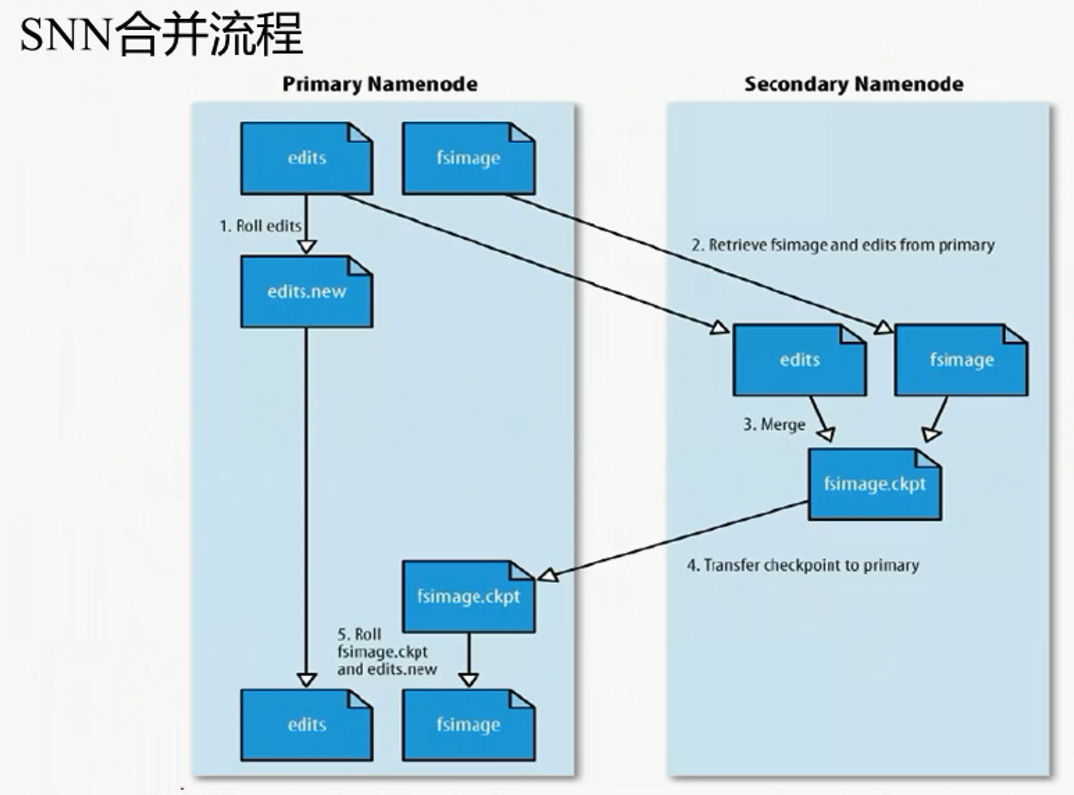
SNameNode的功能: (不是NN的备份, 主要用来合并fsimage)

合并流程:
dataNode的主要功能:
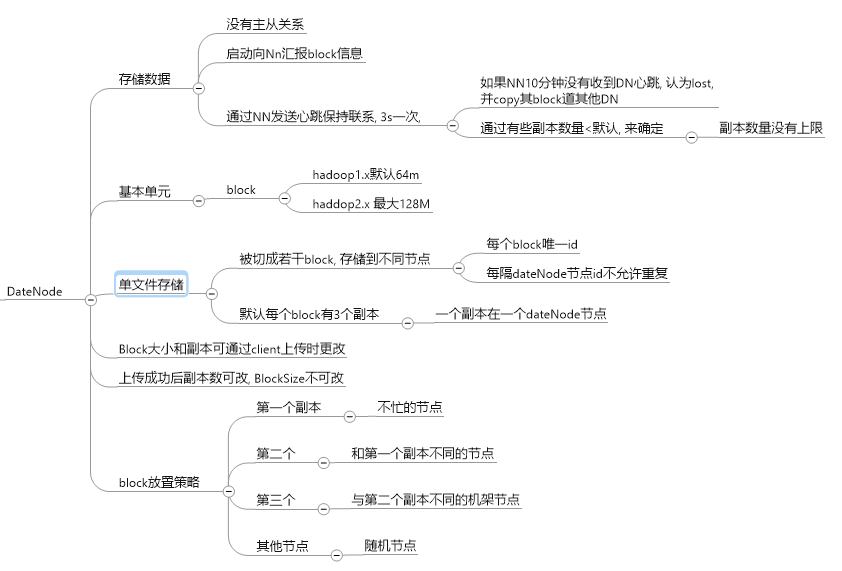
HDFS上传文件思想:
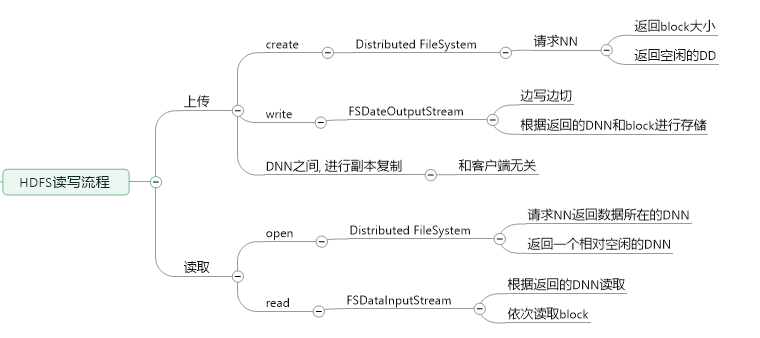
hdfs用于一般用于处理离线数据文件, 存储方式为block副本, 集群规划使用完全式分部安装
一台作为NameNode, 3台为DataNode, 其中hdfs-dnn1 为SecondNameNode:
NameNode: 192.168.208.106 wenbronk.hdfs.com DataNode: 192.168.208.107 hdfs-dnn1 DataNode: 192.168.208.108 hdfs-dnn2 DataNode: 192.168.208.109 hdfs-dnn3
1, 为了方便NameNode直接启动DataNode, 不输入密码, 使用ssh的免密登录
注意: 1. .ssh目录权限必须是700
2 . .ssh/authorized_keys 文件权限必须是600
(nameNode需要远程登陆Dnn中进行开启DNN), 不设置的话每次输入密码
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
生成的公钥和私钥文件在 /root/.ssh 下
将 自己 设置为免密码登录, 将生成的pub文件追加到认证文件下
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys将 NN的公钥放置到DNN中去, (详细可见 ssh 免密码登录 原理)
scp ~/.ssh/id_rsa.pub root@hdfs-dnn1:/opt/ssh
cat /opt/ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_rsa.pub root@hdfs-dnn2:/opt/ssh
cat /opt/ssh/id_rsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/id_dsa.pub root@hdfs-dnn3:/opt/ssh
cat /opt/ssh/id_dsa.pub >> ~/.ssh/authorized_keys
2, 配置4台机器的jdk为1.7版本的, (使用hadoop2.x)
配置好一台机器后, 使用scp拷贝
scp -r jdk1.7.0_79/ root@hdfs-dnn1:/usr/opt/ scp -r jdk1.7.0_79/ root@hdfs-dnn3:/usr/opt/
之后, source /etc/profile
3, 上传解压hadoop.2.5.1_x64.tar.gz
使用rz上传
使用tar -zxvf had.. 解压
4, 修改配置文件
cd hadoop.2.5.1/etc/hadoop
hadoop-env.sh
export JAVA_HOME=/usr/opt/jdk1.7.0_79/
core-site.xml, 配置NN所在的主机和数据传输端口(rpc协议)
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.208.126:9000</value>
</property>
<!--配置缓存目录, 因为fsimage默认在此目录下, 所以更改-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
hdfs-site.xml, 配置的为secondNameNode
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hdfs-dnn1:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>hdfs-dnn1:50091</value>
</property>
slaves
hdfs-dnn1 hdfs-dnn2 hdfs-dnn3
masters 自己创建, 配置SNN的主机名
hdfs-dnn1
之后, 将整个hadoop文件scp到DNN主机上
5, 配置hadoop的环境变量 /etc/profile
export JAVA_HOME=/usr/opt/jdk1.7.0_79 export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/usr/opt/hadoop-2.5.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6, 启动
6.1) 格式化NN, 在 HADOOP_HOME/dfs/name/current/ 下生成fsimage文件
hdfs namenode -format
6.2) 启动
start-dfs.sh
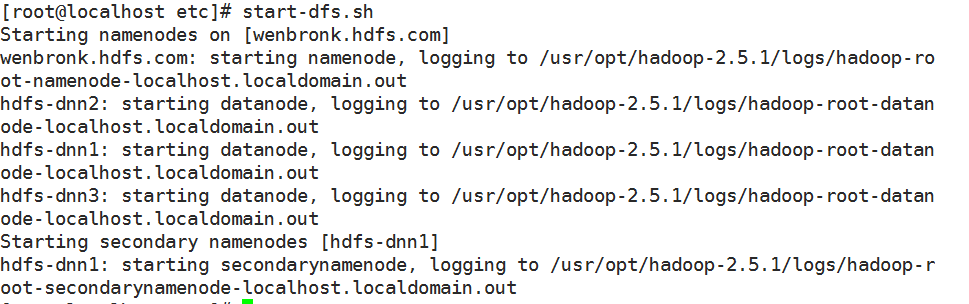
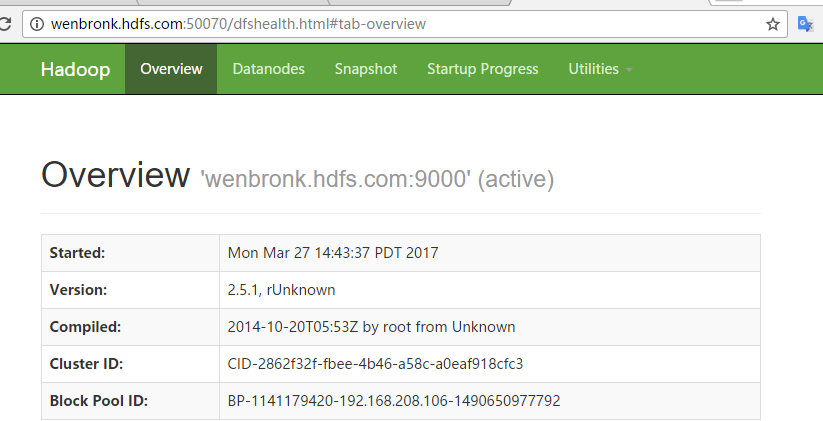
然后通过浏览器可以访问监控页面,
命令行示例:
1) 从本地磁盘拷贝文件
hdfs dfs -put foo.txt foo.txt
hdfs 没有当前目录的概念, 必须从用户的home路径下, /usr/username/foot.txt
# 从hdfs拷贝
hdfs dfs -get /user/fred/bar.txt baz.txt
2) 获取用户home目录列表
hdfs dfs -ls
访问根目录, 直接 /
3) 显示hdfs文件 /user/fred/bar.txt
hdfs dfs -cat /user/fred/bar.txt
4), 在用户目录下创建input目录
hdfs dfs -mkdir input
5) , 删除目录
hdfs dfs -rm -r input-old
系列来自尚学堂