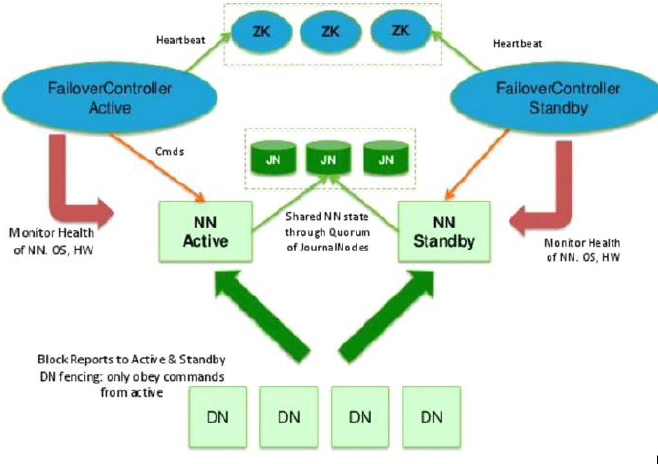
在hdfs中, NN只有一个, 但其中保存的数据尤其重要, 所以需要将元数据保存, 其中源数据有2个形式, fsimage 和 edit文件, 最简单的解决方法就是复制fsimage, 并在文件修改时同时修改 NNActive 和 NNStandby 中的edit, 保存在第三方的QJM中, 所以多个NN除了active接受用户请求外, 无其他区别
首先是, 集群规划:
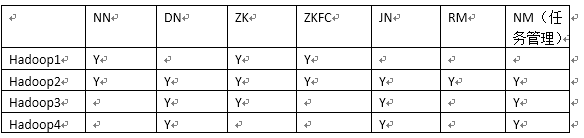
可以看到NN是有1和2组成active和standby的, 之前说过NN需要有DNN免密登录的权限, 所以, 两台分别设置其他三台的免密登录
1, 多台NN间切换, 通过zookeeper来实现的
1) 安装zookeeper.3.4.6.tar.gz, 并创建 conf/zoo.cfg文件
tickTime=2000 dataDir=/var/lib/zookeeper
clientPort=2181 initLimit=5 syncLimit=2 server.1=192.168.208.106:2888:3888 server.2=192.168.208.107:2888:3888 server.3=192.168.208.108:2888:3888
2), 创建data目录和log目录(mkdir -p)
3), 在 ${dataDir}/下面 配置节点信息 myid, 跟上面的server.x保持一致
1
2
3
4), 启动, cd /usr/opt/zookeeper3.4.6/bin
zkServer.sh start
5), 链接内存数据库, 通过get 和ls 等命令可查看数据库中的内容
zkCli.sh
zookeeper启动后, 就不要关闭了...
zk启动脚本:
脚本启动不管用的, 把环境变量配置在 ~/.bashrc下, 因为ssh分为登陆和非登陆, 读取配置文件的顺序不同
#!/bin/bash host=(node2 node3 node4) start() { for i in ${host[@]} do echo start $i ssh -o StrictHostKeyChecking=no root@$i "/usr/local/zookeeper-3.4.11/bin/zkServer.sh start" ssh -o StrictHostKeyChecking=no root@$i "jps" echo start $i done done } stop() { for i in ${host[@]} do echo stop $i ssh -o StrictHostKeyChecking=no root@$i "/usr/local/zookeeper-3.4.11/bin/zkServer.sh stop" ssh -o StrictHostKeyChecking=no root@$i "jps" echo stop $i done done } case "$1" in start) start ;; stop) stop ;; *) echo "Usage: start|stop" ;; esac
2, 修改hdfs的配置文件
2.1), 删除masters, 不需要SNN了
rm -rf /usr/opt/hadoop-2.5.1/etc/hadoop
2.2) 删除原集群中的数据文件
rm -rf /opt/hadoop
2.3) hdfs-site.xml
servername, zookeeper 使用
<property> <name>dfs.nameservices</name> <value>hdfscluster</value> </property>
节点协议( 有几个nameNode定义几个)
<property> <name>dfs.ha.namenodes.hdfscluster</name> <value>nn1,nn2</value> </property>
rpc协议( 文件上传下载使用)
<property> <name>dfs.namenode.rpc-address.hdfscluster.nn1</name> <value>192.168.208.106:8020</value> </property> <property> <name>dfs.namenode.rpc-address.hdfscluster.nn2</name> <value>192.168.208.107:8020</value> </property>
http协议
<property> <name>dfs.namenode.http-address.hdfscluster.nn1</name> <value>192.168.208.106:50070</value> </property> <property> <name>dfs.namenode.http-address.hdfscluster.nn2</name> <value>192.168.208.107:50070</value> </property>
qjm节点, journalNodes节点, 用于缓存edits文件, uri, 分号隔开
<property> <name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.208.107:8485;192.168.208.108:8485;192.168.208.109:8485/hdfscluster</value> </property>
帮助客户端获得activeNameNode
<property> <name>dfs.client.failover.proxy.provider.hdfscluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
远程登陆, 需要ssh密钥文件
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
journalNode 数据存放的目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalNode/data</value>
</property>
2.4) core-site.xml, 修改下入口即可
<property> <name>fs.defaultFS</name> <value>hdfs://hdfscluster</value> </property>
3, 启用自动切换
3.1), hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
3.2), core-site.xml, 更改一个配置即可, hadoop.tmp.dir仍然保留
<property> <name>ha.zookeeper.quorum</name> <value>192.168.208.106:2181,192.168.208.107:2181,192.168.208.108:2181</value> </property>
4, 启动journalNode
hadoop-daemon.sh start journalnode
查看日志检查是否成功启动
停止: hadoop-daemon.sh stop journalnode
lgos/hadoop-root-journalnode-node4.log
5, 格式化其中一个NN
hdfs namenode -format
6, 拷贝fsimage 到另一台 NN上, 或者手动拷贝过去也可以
#启动刚刚格式化的NN
hadoop-daemon.sh start namenode
#在没有格式化的NN上执行
hdfs namenode -bootstrapStandby
#启动第二个NN
hadoop-daemon.sh start namenode
7, 初始化zookeeper, 在active的NN上执行
hdfs zkfc -formatZK
8, 启动
start-dfs.sh
排错时, 可用jps命令查看集群端口号, 然后kill -9, 或者 killall java
ps: 记得上个博客的配置, slaves等
以后启动时, 先启动3台zookeeper, 然后 start-dfs.sh 即可以了
非常坑, 因为私钥文件root前面没有加 / 表明根目录, 卡了一个小时!!!!
系列来自尚学堂