hadoop最主要的2个基本的内容要了解。上次了解了一下HDFS,本章节主要是了解了MapReduce的一些基本原理。
MapReduce文件系统:它是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce将分为两个部分:Map(映射)和Reduce(归约)。
当你向mapreduce框架提交一个计算作业,它会首先把计算作业分成若干个map任务,然后分配到不同的节点上去执行,每一个map任务处理输入数据中的一部分,当map任务完成后,它会生成一些中间文件,这些中间文件将会作为reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个map的数据汇总到一起并输出。
MapReduce的体系结构:
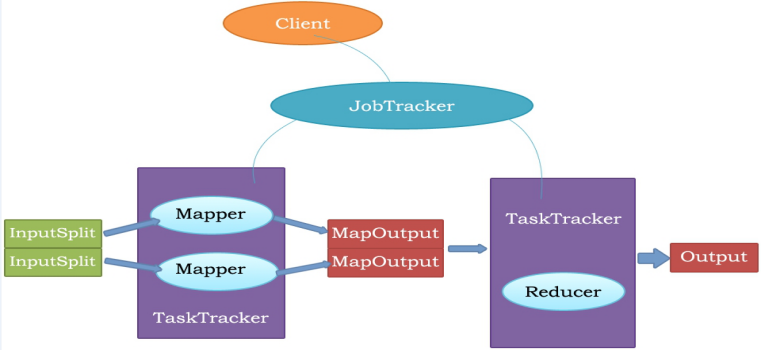
主从结构:主节点,只有一个:JobTracker;从节点,有很多个:Task Trackers
JobTracker负责:接收客户提交的计算任务;把计算任务分给Task Trackers执行;监控Task Tracker的执行情况;
Task Trackers负责:执行JobTracker分配的计算任务。
MapReduce是一种分布式计算模型,由google提出,主要用于搜索领域,解决海量数据的计算问题。
MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参是key、value,表示函数的输入信息。
MapReduce执行流程:
MapReduce原理:
执行步骤:
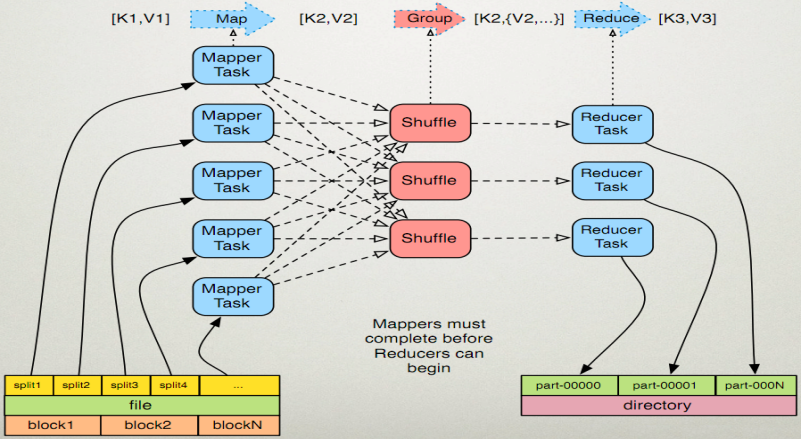
1. map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
1.3 对输出的key、value进行分区。
1.4 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
1.5 (可选)分组后的数据进行归约。
2.reduce任务处理
2.1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2.2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3 把reduce的输出保存到文件中。
例子:实现WordCountApp
map、reduce键值对格式
|
函数 |
输入键值对 |
输出键值对 |
|
map() |
<k1,v1> |
<k2,v2> |
|
reduce() |
<k2,{v2}> |
<k3,v3> |
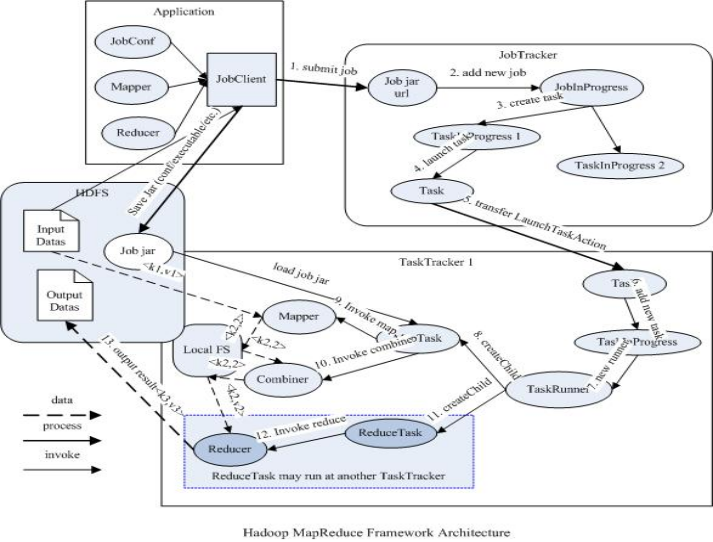
JobTracker
负责接收用户提交的作业,负责启动、跟踪任务执行。
JobSubmissionProtocol是JobClient与JobTracker通信的接口。
InterTrackerProtocol是TaskTracker与JobTracker通信的接口。
TaskTracker
负责执行任务
JobClient
是用户作业与JobTracker交互的主要接口。
负责提交作业的,负责启动、跟踪任务执行、访问任务状态和日志等。
MapReduce驱动默认的设置
|
InputFormat(输入) |
TextInputFormat |
|
MapperClass(map类) |
IdentityMapper |
|
MapOutputKeyClass |
LongWritable |
|
MapOutputValueClass |
Text |
|
PartitionerClass |
HashPartitioner |
|
ReduceClass |
IdentityReduce |
|
OutputKeyClass |
LongWritable |
|
OutputValueClass |
Text |
|
OutputFormatClass |
TextOutputFormat |
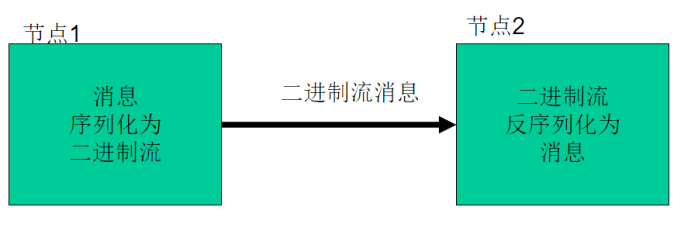
序列化的概念:
序列化(Serialization)是指把结构化对象转化为字节流。
反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。
Java序列化(java.io.Serializable)
Hadoop-序列化格式特点:
紧凑:高效使用存储空间。
快速:读写数据的额外开销小
可扩展:可透明地读取老格式的数据
互操作:支持多语言的交互
Hadoop的序列化格式:Writable
序列化在分布式环境的两大作用:进程间通信,永久存储。
Hadoop节点间通信。
MapReduce输入的处理类:
FileInputFormat:是所有以文件为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法有不同的子类--TextInputFormat进行实现的。
InPutFormat负责处理MR的输入部分。
InPutFormat的三个作用:
验证作业的输入是否规范
把输入文件切成InputSplit
提供RecordReader的实现类,把InputSplit读到Mapper中进行处理。
FileInputSplit:
◆ 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
◆ FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
◆ 如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
◆ 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。
例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
TextInputFormat:
◆ TextInputformat是默认的处理类,处理普通文本文件。
◆ 文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。
◆ 默认以 或回车键作为一行记录。
◆ TextInputFormat继承了FileInputFormat。
InputFormat类的层次结构:
