1 性能测试目的
性能测试的目的:验证软件系统是否能够达到用户提出的性能指标,同时发现软件系统中存在的性能瓶颈,以优化软件。
最后起到优化系统的目的性能测试包括如下几个方面:
1.评估系统的能力:测试中得到的负荷和响应时长数据可以被用于验证所计划的模型的能力,并帮助做出决策
2.识别体系中的弱点:受控的负荷可以被增加到一个极端的水平并突破它,从而修复体系的瓶颈或薄弱的地方
3.系统调优:重复运行测试,验证调整系统的活动是否得到了预期的结果,从而改进性能
检测软件中的问题:长时间的测试执行可导致程序发生由于内存泄漏引起的失败,揭示程序中隐含的问题或冲突
4.验证稳定性(Resilience)、可靠性(Reliability):在一个生产负荷下执行测试-一定的时间是评估系统稳定性和可靠性是否满足要求的唯一方法
2 性能测试常见分类(相关术语)
性能测试:Performance Testing,模拟用户负载来测试系统在负载情况下,系统的响应时间(RT)、吞吐量(TPS)等指标是否满足性能要求。
性能测试包括负载测试、强度测试、容量测试等
2.1 负载测试(Load Testing)
负载:模拟业务操作对服务器造成压力的过程,比如模拟100个用户进行发帖。
负载测试:通过不断加大负载(不同虚拟用户数)来确定在满足性能指标情况下能够承受的最大用户数,即我们对系统进行定容定量,找出系统性能的拐点。性能指标只要包括TPS(每秒事务数)、RT(事务平均响应时间)、CPU Using(CPU 利用率)、Mem Using(内存使用情况)等。
负载测试的目标:确定并确保系统在超出最大预期工作量的情况下仍能正常运行负载测试还要评估性能特征,如响应时长、事务处理速率。
2.2 强度测试(Stress Testing):压力测试
压力测试:通过高负载的手段来使服务器资源处于极限状态,测试系统在极限状态下长时间运行是否稳定,确定稳定的指标主要包括TPS、RT、CPU Using、Mem Using等。
比如测试一个web站点在大量负荷下,何时系统的响应会退化或失败。
2.3 容量测试(Volume Testing)
容量测试确定系统可处理同时在线的最大用户数
针对上述 负载测试、压力测试、容量测试 举个例子
例:一个人背X斤
负载测试:200斤情况下,是否能坚持5分钟
压力测试:200,300,400... 斤情况下,他的表现,什么时候失败,失败之后什么表现,重新扛200是否正常
容量测试:在坚持5分钟的情况下,他一次最多能扛多少斤
2.4 配置测试:Configration Testing
配置测试:为了合理地调配资源,提高系统运行效率,通过测试手段来获取、验证、调整配置信息的过程。通过这个过程我们可以收集到不同配置反映出来的不同性能,从而为设备选择、设备配置提供参考。
2.5 稳定性测试
稳定性测试:长时间运行一定负载,确定系统在满足性能指标的前提下是否运行稳定。满足性能要求的情况下,系统的稳定性、比如响应时间是否稳定、TPS是否稳定。一般会在满足要求的负载情况下加大1.5-2倍的负载量进行测试。
2.6 性能测试指标
TPS(Transaction Per Second):每秒完成的事务数,通常指每秒成功的事务数。一个事务是一个业务度量单位,有时一个事务会包括多个子操作(多个子操作统计为一个事务)。比如一笔电子支付操作,在后台操作中可能会经历会员系统、账务系统、支付系统、会计系统、银行网关等,但对于用户来说只想知道整笔支付花费了多长时间。
QPS(Query Per Second):每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
RT/ART(Response Time / Average Response Time):响应时间/平均响应时间,指一个事务花费多长时间完成(多长时间响应客户请求)。
PV(Page View):每秒用户访问页面的次数,此参数用来分析平均每秒有多少用户访问页面。
Vuser虚拟用户(Virtual user):模拟真实业务逻辑步骤的虚拟用户,虚拟用户模拟的操作步骤都被记录在虚拟用户脚本里。
思考时间(Think Time):模拟正式用户在实际操作时的停顿间隔时间。在测试脚本中,思考时间体现为脚本中两个请求语句之间的间隔时间。
标准差(Std. Deviation):该标准差根据整理统计的概念得来,标准差越小,说明波动越小,系统越稳定,反之,标准差越大,说明波动越大,系统越不稳定。包括响应时间标准差、TPS标准差、Running Vuser标准差、Load标准差、CPU资源利用率标准差、Web Resources标准差等。
场景(Scenario):为了模拟真实用户的业务处理过程,构建的基于事务、脚本、虚拟用户、运行设置、运行计划、监控、分析等的一系列动作的集合,称为性能测试场景。场景中包含了待执行脚本、脚本组、并发用户数、负载生成器、测试目标、测试执行时的配置条件等。
3 性能测试的常见指标
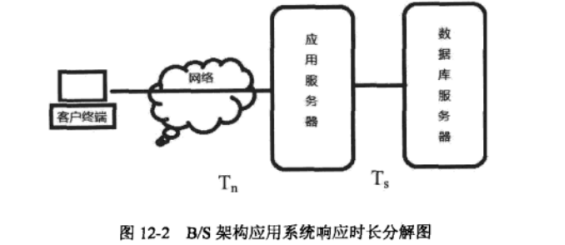
常见的两种架构进行软件测试:B/S、C/S
3.1 B/S架构-常见性能指标
对于B/S架构的软件,一般会关注如下Web服务器性能指标
|
概念 |
说明 |
|
Avg Rps |
平均每秒钟的响应次数=总请求次数/秒数 |
|
Avg time to last byte per terstion(mstes) |
平均每秒业务脚本的迭代次数 |
|
Successful Rounds |
成功的请求 |
|
Failed Rounds |
失败的请求 |
|
Successful Hits |
成功的点击次数 |
|
Failed Hits |
失败的点击次数 |
|
Hits Per Second |
每秒点击次数 |
|
Successful Hits Per Second |
每秒成功的点击次数 |
|
Failed Hits Per Second |
每秒失败的点击次数 |
|
Attempted Connections |
尝试连接数 |
|
Throughput |
吞吐率 |
3.2 C/S架构-常见性能指标
对于C/S架构的程序,由于软件后台通常为数据库,所以我们更注重数据库的测试指标。
除了表格里面的概念,还有部分指标:CPU占用率、内存占用率、数据库连接池等。
|
概念 |
说明 |
|
User Connections |
用户连接数,也就是数据库的连接数量 |
|
Number of Deadlocks |
数据库死锁 |
|
Butter Cache Hit |
数据库Cache的命中情况 |
4 性能测试结果分析
4.1如何分析性能测试结果
- 分析在整个性能测试执行期间,测试环境是否稳定正常。
例如,测试期间运行Jmeter的及其CPU占用率经常达到100%(或内存占用很高)、测试网络出现拥塞导致响应延迟、待测系统参数配置错误(JDBC连接池等).....
2. 检查jmeter测试脚本参数设置是否合理、检查jmeter运行模式是否合理。
例如,线程组的参数Ramp-Up Period(in seconds)设置为0或1,jmeter就会瞬间启动该线程组下的所有虚拟用户,会为待测服务器造成巨大的压力,轻则导致服务器响应时长超长,重则导致部分虚拟用户等待响应超时而报错。
3. 检查测试结果是否暴露出了系统瓶颈。
性能测试分析的原则:由表及里、由内而外、抽丝剥茧
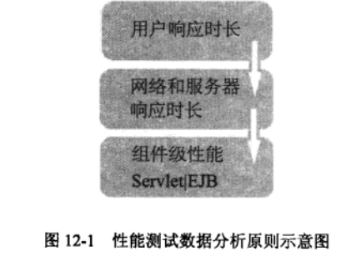
响应时长,主要包括2部分:服务器响应时长(应用服务器、数据库服务器的响应时长)、网络响应时长。
4.2 如何借助监听器发现性能缺陷
4.2.1 图形结果(Graph Results)
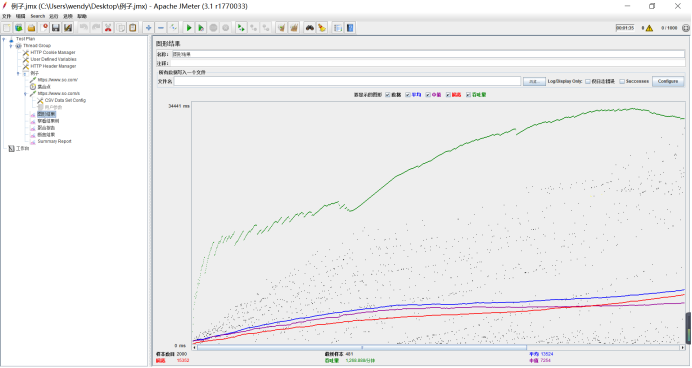
|
概念 |
说明 |
|
样本数目 |
总共发送到服务器的请求数 |
|
最新样本(黑色) |
代表时间的数字,是服务器响应最后一个请求的时间(当前采样响应时长) |
|
吞吐量(绿色) |
服务器每分钟处理的实际请求数 |
|
平均值(蓝色) |
总运行时间除以发送到服务器的请求数(平均采样响应时长) |
|
中间值(紫色) |
代表时间的数字,有一半的服务器响应时间低于该值而另一半高于该值 |
|
偏离(红色) |
服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布 |
测试人员可以通过增加并发线程数或减少脚本中的延迟,来找到系统支持的最大吞吐率。
图形结果中比较有参考价值的字段是:平均值、偏离、吞吐量。
4.2.1.1平均值
随着并发压力的加大,以及时间延长,系统性能所发生的变化。正常情况下,平均采样响应时长曲线应该是平滑的,并大致平行于图形下边界。
可能存在性能问题的平均值:
①平均值在初始阶段跳升,而后逐渐平稳起来。
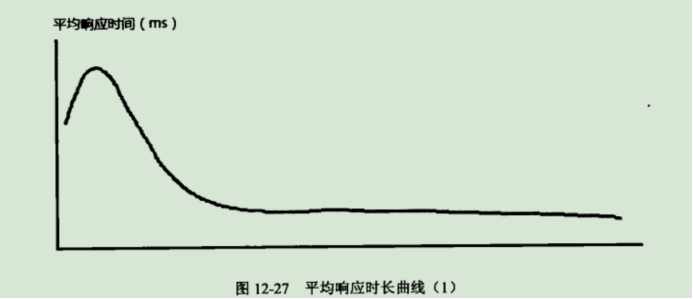
一是系统在初始阶段存在性能缺陷,需要进一步优化,如数据库查询缓慢
二是系统有缓存机制,而性能测试数据在测试期间没有变化,如此一来同样的数据在初始阶段的响应时长肯定较慢;这属于性能测试数据准备的问题,不是性能缺陷,需调整后在测试
三是系统架构设计导致的固有现象,例如在系统接收到第一个请求后,才去建立应用服务器到数据库的链接,后续一段时间内不会释放连接。
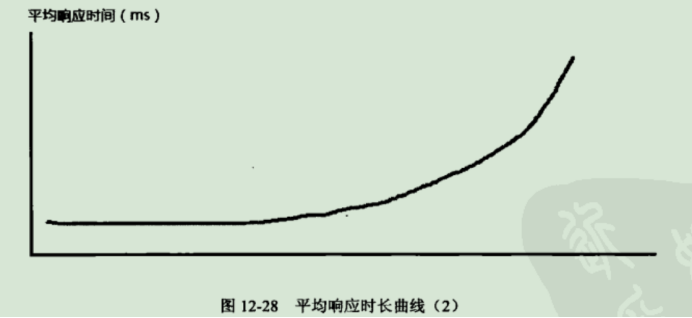
②平均值持续增大,图片变得越来越陡峭
一是可能存在内存泄漏,此时可以通过监控系统日志、监控应用服务器状态等常见方法,来定位问题。
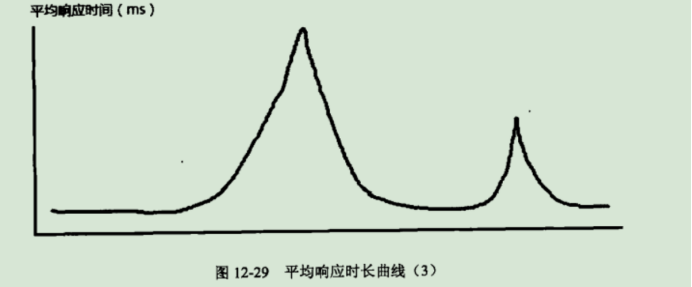
③平均值在性能测试期间,突然发生跳变,然后又恢复正常
一是可能存在系统性能缺陷
二是可能由于测试环境不稳定所造成的(检查应用服务器状态【CPU占用、内存占用】或者检查测试环境网络是否存在拥塞)
4.2.1.2 偏离
观察采样响应时长标准差,可以判断数据的分布是否均匀。理想状态是平滑的。
4.2.1.3 吞吐量
服务器每分钟处理的实际采样数。首先通过增加并发线程数或减少脚本中的延迟,来找到系统支持的最大吞吐率。然后将系统实际支持的最大吞吐率和预期吞吐率进行比较,以便确认系统表现是否满足用户需求。
4.2.2 断言结果(Assertion Results)
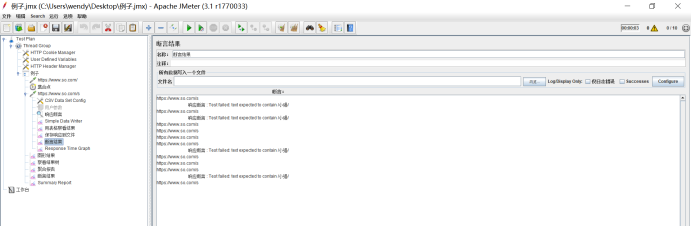
断言结果试图会展示每个采样携带的标签,如果断言有问题,会进行显示。
4.2.3 查看结果树(View Results Tree)
查看结果树会以树的方式来展示所有采样响应结果,测试人员可以通过它来查看任何采样的响应。
查看结果数一般用于调试性能测试脚本。还可以通过查询结果,利用正则表达式,从响应结果中提取数据。
4.2.4用表格查看结果
为每一个采样结果创建一行,但是会占用较多内存。
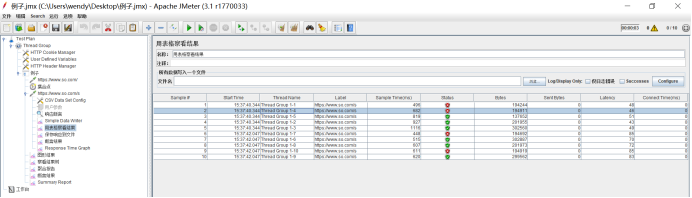
在“用表格查看结果”中,测试人员可以看到采样时间、系统响应时长、字节数等,且可以确定问题采样发生的准确时刻。
4.2.5聚合报告(Aggreate Report)
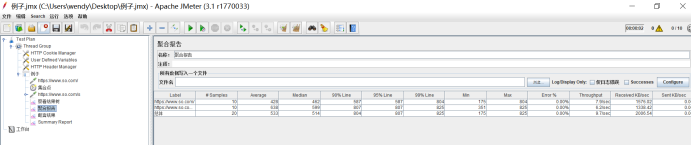
部分概念如下:
|
概念 |
说明 |
|
Label |
说明是请求类型,如Http,FTP等请求 |
|
#Samples |
也就是图形报表中的样本数目,总共发送到服务器的样本数目 |
|
Average |
也就是图形报表中的平均值,是总运行时间除以发送到服务器的请求数(平均响应时间) |
|
Median |
也就是图形报表中的中间值,是代表时间的数字,有一半的服务器响应时间低于该值而另一半高于该值 |
|
90%line |
是指90%请求的响应时间比所得数值还要小 |
|
Min |
是代表时间的数字,是服务器响应的最短时间 |
|
Max |
是代表时间的数字,是服务器响应的最长时间 |
|
Error% |
请求的错误百分比 |
|
Throughput |
也就是图形报表中的吞吐量,这里是服务器每单位时间处理的请求数,注意查看是秒或是分钟 |
|
KB/sec |
是每秒钟请求的字节数(数据传输量) |
|
Throughput |
也就是图形报表中的吞吐量,这里是服务器每单位时间处理的请求数,注意查看是秒或是分钟 |
聚合报告综合判断系统性能是否满足要求。比较关心的几个统计值,包括平均响应时长、90%阈值、吞吐率(每秒完成请求数)、错误率。
PS:90%line的定义:
一组数由小到大进行排列,找到他的第90%个数(假如是12),那么这个数组中有90%的数将小于等于12 。
用在性能测试的响应时间也将非常有意义,也就是90%请求响应时间不会超过12 秒。
4.2.6 聚合图形(Aggregate graph)
聚合图形与聚合报告一致,区别在于聚合图形有生成的图表。
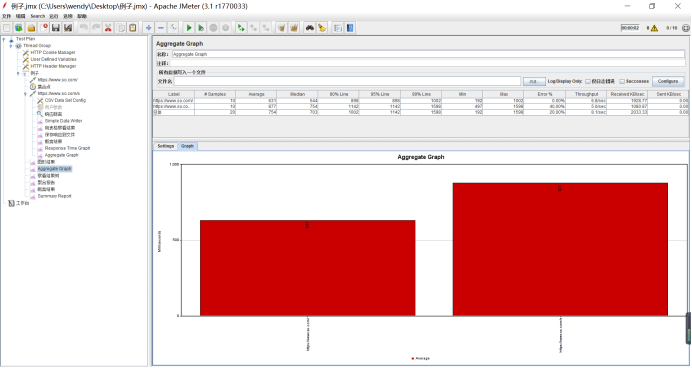
4.2.7概要报告(summary report)

|
概念 |
说明 |
|
Label |
采样标签 |
|
#Samples |
标签名相同的总采样数 |
|
Average |
请求(事务)的平均响应时间 |
|
Min |
标签名相同的采样中,最小的响应时长 |
|
Max |
标签名相同的采样中,最大的响应时长 |
|
Std.Dev. |
采样响应时长的标准差 |
|
Error% |
事务发生错误的比率 |
|
Throughput |
该吞吐率以每秒/分钟/小时发生的采样数来衡量(TPS) |
|
KB/sec |
吞吐量以每秒KB来衡量(即每秒数据包流量) |
|
Avg.Bytes |
以字节为单位的采样响应平均大小(平均数据流量) |
4.2.8服务器性能监控设置
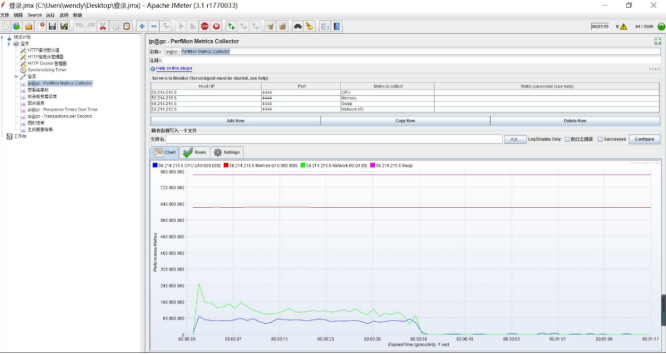
JMeter使用plugins插件进行服务器性能监控,对服务器的 CPU、内存、Swap、磁盘 I/O、网络 I/O 进行监控。客户端添加CPU监控Permon Metrics Collector,服务器端开启代理,在HTTP请求的时候,就能进行服务器资源的监控情况。
4.2.8.1服务器插件下载
访问网址https://jmeter-plugins.org/downloads/old/,下载三个文件。其中客户端插件JMeterPlugins-Standard和JMeterPlugins-Extras(目前我使用的版本是1.4.0),
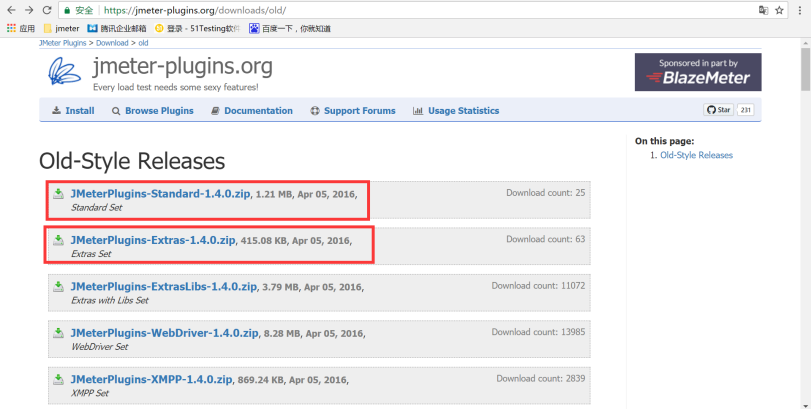
访问网址https://jmeter-plugins.org/wiki/Start/,下载服务器端插件ServerAgent的。

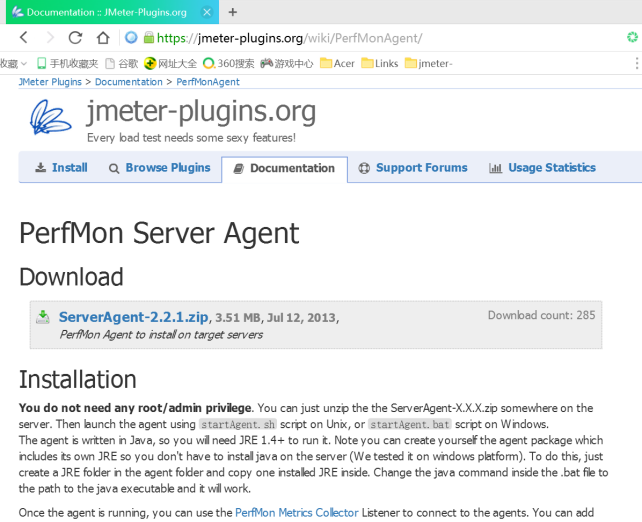
4.2.8.2插件客户端配置
解压客户端的两个文件,进入其路径JMeterPlugins-Extras(Standard)-1.3.1libext,复制JmeterPlugins-Extras.jar(JmeterPlugins-Standard.jar)两个文件,放到JMeter客户端的lib/ext文件夹中,打开JMeter,可在监听器中看到Permon Metrics Collector,客户端配置成功。
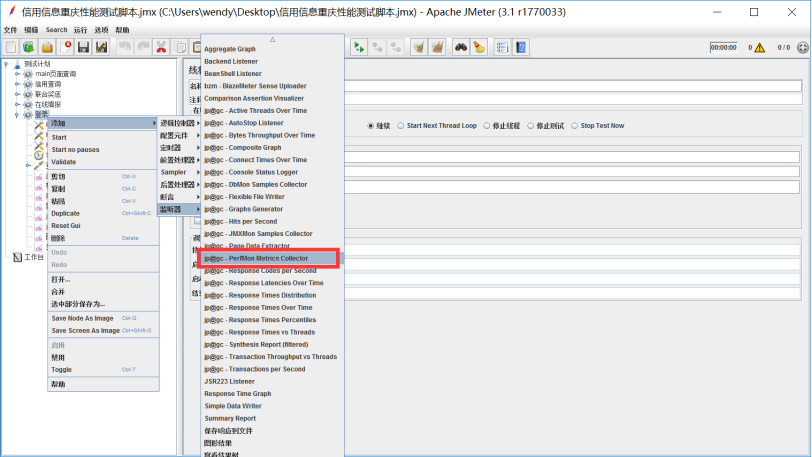
4.2.8.3插件服务器端配置
将ServerAgent-2.2.1.jar上传到被测服务器,解压,进入目录,Windows环境,双击ServerAgent.bat启动;linux环境执ServerAgent.sh启动,默认使用4444端口,出现如下情况

即服务端配置成功。
11-4.Permon Metrics Collector监控的执行