文章的基本信息
文章来源: SIGGRAPH 2017
下载链接: Parper Download Code Download
摘要
解决问题:修复图像
论文背景:
- 基于
Patch-based的图像补全,该类方法主要是从源图像中寻找相似的patch,然后将该patch贴到缺失的区域。当源图像中没有类似的区域时,该方法就无法填充看上去合理的洞。Patch-based方法的不足:(1)Depend on low-level features;(2)Unable to generate novel objects; - 基于
Context Encoder的图像补全,该方法基于深度学习生成相似的纹理区域,在一定程度上可以补全缺失的区域,而且效果还不错。但是不能够保持局部一致性。Context Encoder方法的不足:(1)Can generate novel objects but fixed low resolution images;(2)Masks region must in the center of image;(3)补全的区域不能保持与周围区域的局部一致性。 - 本文方法主要是基于Context Encoder方法进行相关改进。下表为三种方法的简单比较。

论文目的:本文提出一种新颖的图像补全方法,可以保持图像在局部和全局一致。使用完全卷积神经网络,我们可以通过填充任何形状的缺失区域来完成任意分辨率的图像。为了训练这个图像补全网络,作者使用全局和局部上下文鉴别器进行训练,以区分真实图像和已补全的图像。全局鉴别器查看整个图像,以评估其是否整体一致,而局部鉴别器仅在以补全区域为中心的小区域上看,以确保生成的补丁在局部保持一致性。
解决办法:
数据集:
试验结果:
论文贡献: 全卷积神经网络+局部+全局+dilated conv(来增大感受野,使得网络的学习能力更强)
相关参考:
网络结构
该文章完全以卷积网络作为基础,遵循GAN的思路,设计为两部分(三个网络),一部分用于生成图像,即生成网络,一部分用于鉴别生成图像是否与原图像一致,即全局鉴别器和局部鉴别器。在整个网络中,作者采用ReLU函数,在最后一层采用Sigmoid函数使得输出在0到1区间内。网络结构图如下所示。
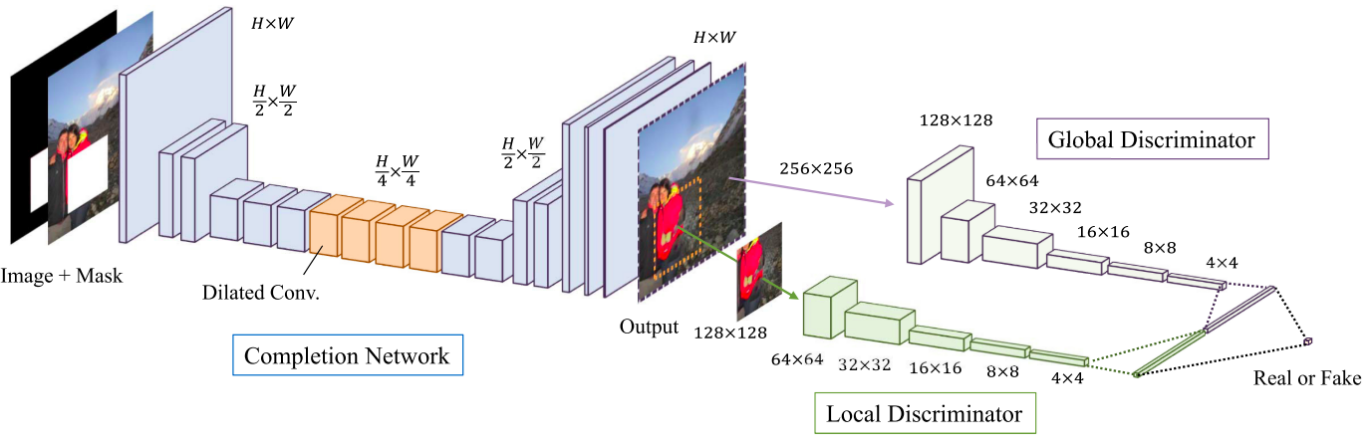
可以从图中看出completion network下采样到原图的1/4,然后经过conv和dilated conv后上采样到原尺寸来恢复mask里面的细节,之后使用global discriminator和local discriminator来使得补全的细节更加真实。
Generator
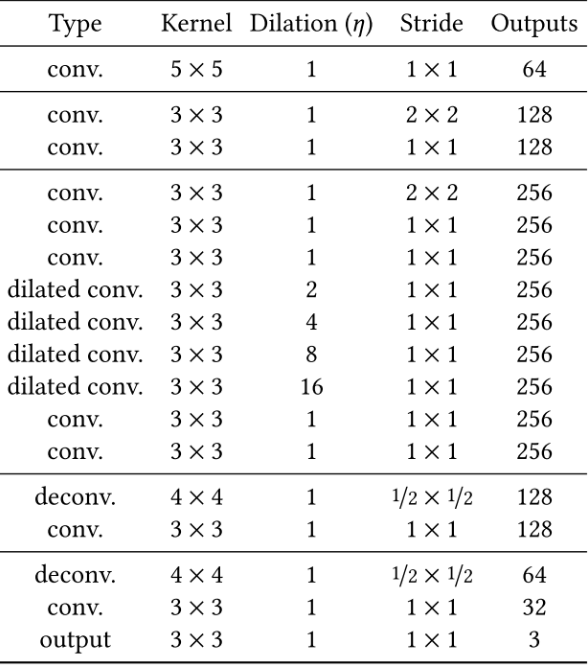
生成图像部分,作者采用12层卷积网络对原始图片(去除需要进行填充的部分)进行encoding,得到一张原图16分之一大小的网格。然后再对该网格采用4层卷积网络进行decoding,从而得到复原图像,下表为生成网络各层参数分布情况。
生成器的具体操作过程:先利用卷积降低图片的分辨率然后利用去卷积增大图片的分辨率得到修复结果。为了保证生成区域尽量不模糊,文中降低分辨率的操作是使用strided convolution 的方式进行的,而且只用了两次,将图片的size 变为原来的四分之一。同时在中间层还使用了dilated convolutional layers 来增大感受野,在尽量获取更大范围内的图像信息的同时不损失额外的信息。
输入:RGB图像,二进制掩码(需要填充的区域以1填充)
输出:RGB图像
Generator loss function
生成网络使用weighted Mean Squared Error (MSE)作为损失函数,计算原图与生成图像像素之间的差异,表达式如下所示:
其中,⊙ is the pixelwise multiplication,|| · || is the Euclidean norm . C(x,Mc)表示Completion Network表示的函数,x表示输入的图像,Mc表示待修复区域的Mask,Mask大小和输入图像一样,1表示缺失区域,0表示非缺失区域。
Discriminator
鉴别器被分为两个部分,一个全局鉴别器(Global Discriminator)以及一个局部鉴别器(Local Discriminator)。
- 全局鉴别器将完整图像作为输入,识别场景的全局一致性,如果图片较大,会将其resize 成256 × 256,通过多次convolution 和全连接层输出一个1024 维的向量,
- 而局部鉴别器仅在以填充区域为中心的原图像4分之一大小区域上观测,识别局部一致性。输入为修复的区域,resize 其大小为128 × 128,同样通过多次卷积和全连接输出一个1024 维的向量,把这两个向量连接成2048 维的向量再经过一个全连接层,输出判别结果。
通过采用两个不同的鉴别器,使得最终网络不但可以使全局观测一致,并且能够优化其细节,最终产生更好的图片填充效果。
全局鉴别网络输入是256X256,RGB三通道图片,局部网络输入是128X128,RGB三通道图片,根据论文当中的设置,全局网络和局部网络都会通过5X5的convolution layer,以及2X2的stride降低分辨率,最终分别得到1024维向量。然后,作者将全局和局部两个鉴别器输出连接成一个2048维向量,通过一个全连接然后用sigmoid函数得到整体图像一致性打分。
Discriminator loss function
鉴别器网络使用GAN损失函数,其目标是最大化生成图像和原始图像的相似概率(见图5中的2048维向量,它代表的是概率),表达式如下所示:
connect layer
将Discriminator两个网络生成的两个1024向量连接成2048 维的向量再经过一个全连接层,输出判别结果。生成网络和鉴别网络之间连接层参数设置:
final loss function
其中α为超参数,文中取值0.004.
Training Neural networks
训练算法流程图,如下:(其中Mc 为生成图像的Mask,Md 为真实图像的Mask,利用(C(x, Mc), Mc) 和(x, Md) 的交叉熵loss 来进行更新)

Trained completion network with the MSE loss. (TC= 90, 000 iterations)Fix the completion network and train the discriminators. (TD = 10, 000 iterations)Completion network and content discriminators are trained jointly. (Ttrain = 500, 000 iterations )post-processing,Blending the completed region with the color of the surrounding pixels.(首先使用fast marching method然后使用泊松分布图像融合)
其中第(1) (2)对于该网络取得成功至关重要。
Some tricks:(训练图像可以是任何尺寸)
(1)将图像的较短边resize成(256,384)中的一个随机数(等比例resize)。
(2)从图像上随机crop一个256*256的图片。
(3)在图像上随机挖一个洞,洞的长和宽为(96,128)中的某个随机数(长宽不需一样,且相互独立)。
(4)全局discriminator的输入为full 256×256-pixel。
(5)局部discriminator的输入128 × 128-pixel patch。
试验结果
文章特点
- 生成网络模型仅仅降低了两次分辨率,使用大小为原始大小四分之一的卷积,其目的是为了降低最终图像的纹理模糊程度。
- 使用
dilatedconvolutionallayer(空洞卷积/扩张卷积),它能够通过相同数量的参数和计算能力感知每个像素周围更大的区域。(Multi-Scale Context Aggregation by Dilated Convolutions) - 复原能力强,且可以生成眼睛、鼻子等细节结构,但是需要在相关数据集上进行
fine-training
文章中给出了具体的示意,为了能够计算填充图像每一个像素的颜色,该像素需要知道周围图像的内容,采用空洞卷积能够帮助每一个点有效 的“看到”比使用标准卷积更大的输入图像区域,从而填充图中点p2的颜色。
扩张卷积算子可以用下式来表示:
其中,η是扩张因子,当η=1,则表示标准卷积操作,文中的η1>1;
Dilated convolutions:307×307pixelsstandard convolutional:99×99 pixels
存在的不足
- 不能补全具有大尺寸洞的图,这主要与空洞卷积所能“看到”的区域大小有关,文中最大可看到
307×307pixels。 - 不能生成复杂性的结构性纹理,这个可能与作者的网络设计的网络有关。
- 一定程度上受到训练图像库的限制。
- 如果
mask中抹掉的是大块的结构状物体,复原效果比较差,接近object removal的效果了