1.0 k8s 集群状态检查
# 查看集群信息
kubectl cluster-info
systemctl status kube-apiserver
systemctl status kubelet
systemctl status kube-proxy
systemctl status kube-scheduler
systemctl status kube-controller-manager
systemctl status docker
# 查看namespaces
kubectl get namespaces
# 为节点增加lable
kubectl label nodes 10.126.72.31 points=test
# 查看节点和lable
kubectl get nodes --show-labels
# 查看状态
kubectl get componentstatuses
# Node的隔离与恢复
## 隔离
kubectl cordon k8s-node1
## 恢复
kubectl uncordon k8s-node1
#查询
# 查看nodes节点
kubectl get nodes
# 通过yaml文件查询
kubectl get -f xxx-yaml/
# 查询资源
kubectl get resourcequota
# endpoints端
kubectl get endpoints
# 查看pods
# 查看指定空间`kube-system`的pods
kubectl get po -n kube-system
# 查看所有空间的
kubectl get pods -o wide --all-namespaces
# 其他的写法
kubectl get pod -o wide --namespace=kube-system
# 获取svc
kubectl get svc --all-namespaces
# 其他写法
kubectl get services --all-namespaces
# 通过lable查询
kubectl get pods -l app=nginx -o yaml|grep podIP
# 当我们发现一个pod迟迟无法创建时,描述一个pods
kubectl describe pod xxx
删除所有pod
# 删除所有pods
kubectl delete pods --all
# 删除所有包含某个lable的pod和serivce
kubectl delete pods,services -l name=<lable-name>
# 删除ui server,然后重建
kubectl delete deployments kubernetes-dashboard --namespace=kube-system
kubectl delete services kubernetes-dashboard --namespace=kube-system
# 强制删除部署
kubectl delete deployment kafka-1
# 删除rc
kubectl delete rs --all && kubectl delete rc --all
## 强制删除Terminating状态的pod
kubectl delete deployment kafka-1 --grace-period=0 --force
滚动
# 升级
kubectl apply -f xxx.yaml --record
# 回滚
kubectl rollout undo deployment javademo
# 查看滚动升级记录
kubectl rollout history deployment {名称}
查看日志
# 查看指定镜像的日志
kubectl logs -f kube-dns-699984412-vz1q6 -n kube-system
kubectl logs --tail=10 nginx
#指定其中一个查看日志
kubectl logs kube-dns-699984412-n5zkz -c kubedns --namespace=kube-system
kubectl logs kube-dns-699984412-vz1q6 -c dnsmasq --namespace=kube-system
kubectl logs kube-dns-699984412-mqb14 -c sidecar --namespace=kube-system
# 看日志
journalctl -f
扩展
# 扩展副本
kubectl scale rc xxxx --replicas=3
kubectl scale rc mysql --replicas=1
kubectl scale --replicas=3 -f foo.yaml
执行
# 启动
nohup kubectl proxy --address='10.1.70.247' --port=8001 --accept-hosts='^*$' >/dev/null 2>&1 &
# 进入镜像
kubectl exec kube-dns-699984412-vz1q6 -n kube-system -c kubedns ifconfig
kubectl exec kube-dns-699984412-vz1q6 -n kube-system -c kubedns ifconfig /bin/bash
# 执行镜像内命令
kubectl exec kube-dns-4140740281-pfjhr -c etcd --namespace=kube-system etcdctl get /skydns/local/cluster/default/redis-master
无限循环命令
while true; do sleep 1; done
资源管理
# 暂停资源更新(资源变更不会生效)
kubectl rollout pause deployment xxx
# 恢复资源更新
kubectl rollout resume deployment xxx
# 设置内存、cpu限制
kubectl set resources deployment xxx -c=xxx --limits=cpu=200m,memory=512Mi --requests=cpu=1m,memory=1Mi
# 设置storageclass为默认
kubectl patch storageclass <your-class-name> -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
其他
# 创建和删除
kubectl create -f dashboard-controller.yaml
kubectl delete -f dashboard-dashboard.yaml
# 查看指定pods的环境变量
kubectl exec xxx env
# 判断dns是否通
kubectl exec busybox -- nslookup kube-dns.kube-system
# kube-proxy状态
systemctl status kube-proxy -l
# 查看token
kubectl get serviceaccount/kube-dns --namespace=kube-system -o yaml|grep token
查看帮助:
[root@master1 ~]# kubectl --help
查看版本:(至今,yum安装的版本竟然是1.5.2,,这两天准备升级到1.8x)
[root@master1 ~]# kubectl --version
Kubernetes v1.5.2
get
get命令用于获取集群的一个或一些resource信息。 使用–help查看详细信息。
Ps:kubectl的帮助信息、示例相当详细,而且简单易懂。建议大家习惯使用帮助信息。kubectl可以列出集群所有resource的详细。resource包括集群节点、运行的pod,ReplicationController,service等。
基础查看命令
# kubectl get po //查看所有的pods
# kubectl get nodes //查看所有的nodes
# kubectl get pods -o wide //查看所有的pods更详细些
# kubectl get nodes -o wide //查看所有的nodes更详细些
# kubectl get po --all-namespaces //查看所有的namespace
3种方式查看一个pod的详细信息和参数:
# kubectl get po pod-redis -o yaml //以yaml文件形式显示一个pod的详细信息
kubectl get po <podname> -o json //以json文件形式显示一个pod的详细信息
2.0 常用命令详解
describe
describe类似于get,同样用于获取resource的相关信息。不同的是,get获得的是更详细的resource个性的详细信息,describe获得的是resource集群相关的信息。describe命令同get类似,但是describe不支持-o选项,对于同一类型resource,describe输出的信息格式,内容域相同。
注:如果发现是查询某个resource的信息,使用get命令能够获取更加详尽的信息。但是如果想要查询某个resource的状态,如某个pod并不是在running状态,这时需要获取更详尽的状态信息时,就应该使用describe命令。
# kubectl describe po rc-nginx-3-l8v2r
create
不多讲了,前面已经说了很多次了。 直接使用create则可以基于rc-nginx-3.yaml文件创建出ReplicationController(rc),rc会创建两个副本:
# kubectl create -f rc-nginx.yaml
replace
replace命令用于对已有资源进行更新、替换。如前面create中创建的nginx,当我们需要更新resource的一些属性的时候,如果修改副本数量,增加、修改label,更改image版本,修改端口等。都可以直接修改原yaml文件,然后执行replace命令。
注:名字不能被更更新。另外,如果是更新label,原有标签的pod将会与更新label后的rc断开联系,有新label的rc将会创建指定副本数的新的pod,但是默认并不会删除原来的pod。所以此时如果使用get po将会发现pod数翻倍,进一步check会发现原来的pod已经不会被新rc控制,此处只介绍命令不详谈此问题,好奇者可自行实验。
# kubectl replace -f rc-nginx.yaml
patch
如果一个容器已经在运行,这时需要对一些容器属性进行修改,又不想删除容器,或不方便通过replace的方式进行更新。kubernetes还提供了一种在容器运行时,直接对容器进行修改的方式,就是patch命令。
如前面创建pod的label是app=nginx-2,如果在运行过程中,需要把其label改为app=nginx-3,这patch命令如下:
kubectl patch pod rc-nginx-2-kpiqt -p '{"metadata":{"labels":{"app":"nginx-3"}}}'
edit
edit提供了另一种更新resource源的操作,通过edit能够灵活的在一个common的resource基础上,发展出更过的significant resource。例如,使用edit直接更新前面创建的pod的命令为:
# kubectl edit po rc-nginx-btv4j
上面命令的效果等效于:
kubectl get po rc-nginx-btv4j -o yaml >> /tmp/nginx-tmp.yaml
vim /tmp/nginx-tmp.yaml
/*do some changes here */
kubectl replace -f /tmp/nginx-tmp.yaml
Delete
根据resource名或label删除resource。
kubectl delete -f rc-nginx.yaml
kubectl delete po rc-nginx-btv4j
kubectl delete po -lapp=nginx-2
apply
apply命令提供了比patch,edit等更严格的更新resource的方式。通过apply,用户可以将resource的configuration使用source control的方式维护在版本库中。每次有更新时,将配置文件push到server,然后使用kubectl apply将更新应用到resource。kubernetes会在引用更新前将当前配置文件中的配置同已经应用的配置做比较,并只更新更改的部分,而不会主动更改任何用户未指定的部分。
apply命令的使用方式同replace相同,不同的是,apply不会删除原有resource,然后创建新的。apply直接在原有resource的基础上进行更新。同时kubectl apply还会resource中添加一条注释,标记当前的apply。类似于git操作。
logs
logs命令用于显示pod运行中,容器内程序输出到标准输出的内容。跟docker的logs命令类似。如果要获得tail -f 的方式,也可以使用-f选项。
# kubectl get pods
# kubectl logs mysql-478535978-1dnm2
rolling-update
rolling-update是一个非常重要的命令,对于已经部署并且正在运行的业务,rolling-update提供了不中断业务的更新方式。rolling-update每次起一个新的pod,等新pod完全起来后删除一个旧的pod,然后再起一个新的pod替换旧的pod,直到替换掉所有的pod。
rolling-update需要确保新的版本有不同的name,Version和label,否则会报错 。
kubectl rolling-update rc-nginx-2 -f rc-nginx.yaml
如果在升级过程中,发现有问题还可以中途停止update,并回滚到前面版本
kubectl rolling-update rc-nginx-2 —rollback
rolling-update还有很多其他选项提供丰富的功能,如—update-period指定间隔周期,使用时可以使用-h查看help信息。
scale
scale用于程序在负载加重或缩小时副本进行扩容或缩小,如前面创建的 nginx 有两个副本,可以轻松的使用scale命令对副本数进行扩展或缩小。
扩展副本数到4:
kubectl scale rc rc-nginx-3 —replicas=4
重新缩减副本数到2:
kubectl scale rc rc-nginx-3 —replicas=2
autoscale
scale虽然能够很方便的对副本数进行扩展或缩小,但是仍然需要人工介入,不能实时自动的根据系统负载对副本数进行扩、缩。autoscale命令提供了自动根据pod负载对其副本进行扩缩的功能。
autoscale命令会给一个rc指定一个副本数的范围,在实际运行中根据pod中运行的程序的负载自动在指定的范围内对pod进行扩容或缩容。如前面创建的nginx,可以用如下命令指定副本范围在1~4
kubectl autoscale rc rc-nginx-3 --min=1 --max=4
cordon, drain, uncordon
这三个命令是正式release的1.2新加入的命令,三个命令一起介绍,是因为三个命令配合使用可以实现节点的维护。
在1.2之前,因为没有相应的命令支持,如果要维护一个节点,只能stop该节点上的kubelet将该节点退出集群,是集群不在将新的pod调度到该节点上。如果该节点上本生就没有pod在运行,则不会对业务有任何影响。如果该节点上有pod正在运行,kubelet停止后,master会发现该节点不可达,而将该节点标记为notReady状态,不会将新的节点调度到该节点上。同时,会在其他节点上创建新的pod替换该节点上的pod。
这种方式虽然能够保证集群的健壮性,但是任然有些暴力,如果业务只有一个副本,而且该副本正好运行在被维护节点上的话,可能仍然会造成业务的短暂中断。
1.2中新加入的这3个命令可以保证维护节点时,平滑的将被维护节点上的业务迁移到其他节点上,保证业务不受影响。如下图所示是一个整个的节点维护的流程(为了方便demo增加了一些查看节点信息的操作):
1)首先查看当前集群所有节点状态,可以看到共四个节点都处于ready状态;
2)查看当前nginx两个副本分别运行在d-node1和k-node2两个节点上;
3)使用cordon命令将d-node1标记为不可调度;
4)再使用kubectl get nodes查看节点状态,发现d-node1虽然还处于Ready状态,但是同时还被禁能了调度,这意味着新的pod将不会被调度到d-node1上。
5)再查看nginx状态,没有任何变化,两个副本仍运行在d-node1和k-node2上;
6)执行drain命令,将运行在d-node1上运行的pod平滑的赶到其他节点上;
7)再查看nginx的状态发现,d-node1上的副本已经被迁移到k-node1上;这时候就可以对d-node1进行一些节点维护的操作,如升级内核,升级Docker等;
8)节点维护完后,使用uncordon命令解锁d-node1,使其重新变得可调度;
9)检查节点状态,发现d-node1重新变回Ready状态。
attach
类似于docker attach的功能,用于取得实时的类似于kubectl logs的信息
# kubectl get pods# kubectl attach sonarqube-3574384362-m7mdq
exec
exec命令同样类似于docker的exec命令,为在一个已经运行的容器中执行一条shell命令,如果一个pod容器中,有多个容器,需要使用-c选项指定容器。
# kubectl get pods
# kubectl exec mysql-478535978-1dnm2 hostname //查看这个容器的hostname
port-forward
转发一个本地端口到容器端口,博主一般都是使用yaml的方式编排容器,所以基本不使用此命令。
proxy
博主只尝试过使用nginx作为kubernetes多master HA方式的代理,没有使用过此命令为kubernetes api server运行过proxy
run
类似于docker的run命令,直接运行一个image。
label
为kubernetes集群的resource打标签,如前面实例中提到的为rc打标签对rc分组。还可以对nodes打标签,这样在编排容器时,可以为容器指定nodeSelector将容器调度到指定lable的机器上,如如果集群中有IO密集型,计算密集型的机器分组,可以将不同的机器打上不同标签,然后将不同特征的容器调度到不同分组上。
在1.2之前的版本中,使用kubectl get nodes则可以列出所有节点的信息,包括节点标签,1.2版本中不再列出节点的标签信息,如果需要查看节点被打了哪些标签,需要使用describe查看节点的信息。
cp
kubectl cp 用于pod和外部的文件交换。
在pod中创建一个文件message.log
# kubectl exec -it mysql-478535978-1dnm2 sh
#touch message.log
# kubectl cp message.log mysql-478535978-1dnm2:/tmp/message.log
kubectl cluster-info
使用cluster-info和cluster-info dump也能取出一些信息,尤其是你需要看整体的全部信息的时候一条命令一条命令的执行不如kubectl cluster-info dump来的快一些
# kubectl cluster-info
Kubernetes master is running at http://localhost:8080
3.0 常用命令实战详解
集群构成
一主三从的Kubernetes集群
[root@ku8-1 tmp]# kubectl get nodes
NAME STATUS AGE
192.168.32.132 Ready 12m
192.168.32.133 Ready 11m
192.168.32.134 Ready 11m
yaml文件:
[root@ku8-1 tmp]# cat nginx/nginx.yaml
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: nginx
spec:
replicas: 1
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: nginx
image: 192.168.32.131:5000/nginx:1.12-alpine
ports:
- containerPort: 80
protocol: TCP
---
kind: Service
apiVersion: v1
metadata:
name: nginx
labels:
name: nginx
spec:
type: NodePort
ports:
- protocol: TCP
nodePort: 31001
targetPort: 80
port: 80
selector:
name: nginx
创建pod/deployment/service
[root@ku8-1 tmp]# kubectl create -f nginx/
deployment "nginx" created
service "nginx" created
确认 创建pod/deployment/service
[root@ku8-1 tmp]# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 172.200.0.1 <none> 443/TCP 1d
nginx 172.200.229.212 <nodes> 80:31001/TCP 58s
[root@ku8-1 tmp]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2476590065-1vtsp 1/1 Running 0 1m
[root@ku8-1 tmp]# kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 1 1m
kubectl edit
edit这条命令用于编辑 服务器 上的资源,具体是什么意思,可以通过如下使用方式来确认。
编辑对象确认
使用-o参数指定输出格式为yaml的nginx的service的设定情况确认,取得现场情况,这也是我们不知道其yaml文件而只有环境时候能做的事情。
[root@ku8-1 tmp]# kubectl get service |grep nginx
nginx 172.200.229.212 <nodes> 80:31001/TCP 2m
[root@ku8-1 tmp]# kubectl get service nginx -o yaml
apiVersion: v1
kind: Service
metadata:
creationTimestamp: 2017-06-30T04:50:44Z
labels:
name: nginx
name: nginx
namespace: default
resourceVersion: "77068"
selfLink: /api/v1/namespaces/default/services/nginx
uid: ad45612a-5d4f-11e7-91ef-000c2933b773
spec:
clusterIP: 172.200.229.212
ports:
- nodePort: 31001
port: 80
protocol: TCP
targetPort: 80
selector:
name: nginx
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
使用edit命令对nginx的service设定进行编辑,得到如下信息
可以看到当前端口为31001,在此编辑中,我们把它修改为31002
[root@ku8-1 tmp]# kubectl edit service nginx
service "nginx" edited
编辑之后确认结果发现,此服务端口已经改变
[root@ku8-1 tmp]# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 172.200.0.1 <none> 443/TCP 1d
nginx 172.200.229.212 <nodes> 80:31002/TCP 8m
确认后发现能够立连通
[root@ku8-1 tmp]# curl http://192.168.32.132:31002/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
而之前的端口已经不通
[root@ku8-1 tmp]# curl http://192.168.32.132:31001/
curl: (7) Failed connect to 192.168.32.132:31001; Connection refused
kubectl replace
了解到edit用来做什么之后,我们会立即知道replace就是替换,我们使用上个例子中的service的port,重新把它改回31001
[root@ku8-1 tmp]# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 172.200.0.1 <none> 443/TCP 1d
nginx 172.200.229.212 <nodes> 80:31002/TCP 17m
取得当前的nginx的service的设定文件,然后修改port信息
[root@ku8-1 tmp]# kubectl get service nginx -o yaml >nginx_forreplace.yaml
[root@ku8-1 tmp]# cp -p nginx_forreplace.yaml nginx_forreplace.yaml.org
[root@ku8-1 tmp]# vi nginx_forreplace.yaml
[root@ku8-1 tmp]# diff nginx_forreplace.yaml nginx_forreplace.yaml.org
15c15
< - nodePort: 31001
---
> - nodePort: 31002
执行replace命令
提示被替换了
[root@ku8-1 tmp]# kubectl replace -f nginx_forreplace.yaml
service "nginx" replaced
确认之后发现port确实重新变成了31001
[root@ku8-1 tmp]# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 172.200.0.1 <none> 443/TCP 1d
nginx 172.200.229.212 <nodes> 80:31001/TCP 20m
kubectl patch
当部分修改一些设定的时候patch非常有用,尤其是在1.2之前的版本,port改来改去好无聊,这次换个image
当前port中使用的nginx是alpine的1.12版本
[root@ku8-1 tmp]# kubectl exec nginx-2476590065-1vtsp -it sh
/ # nginx -v
nginx version: nginx/1.12.0
执行patch进行替换
[root@ku8-1 tmp]# kubectl patch pod nginx-2476590065-1vtsp -p '{"spec":{"containers":[{"name":"nginx","image":"192.168.32.131:5000/nginx:1.13-alpine"}]}}'
"nginx-2476590065-1vtsp" patched
确认当前pod中的镜像已经patch成了1.13
[root@ku8-1 tmp]# kubectl exec nginx-2476590065-1vtsp -it sh
/ # nginx -v
nginx version: nginx/1.13.1
kubectl scale
scale命令用于横向扩展,是kubernetes或者swarm这类容器编辑平台的重要功能之一,让我们来看看是如何使用的
事前设定nginx的replica为一,而经过确认此pod在192.168.32.132上运行
[root@ku8-1 tmp]# kubectl delete -f nginx/
deployment "nginx" deleted
service "nginx" deleted
[root@ku8-1 tmp]# kubectl create -f nginx/
deployment "nginx" created
service "nginx" created
[root@ku8-1 tmp]#
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-74tpk 1/1 Running 0 17s 172.200.26.2 192.168.32.132
[root@ku8-1 tmp]# kubectl get deployments -o wide
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 1 27s
执行scale命令
使用scale命令进行横向扩展,将原本为1的副本,提高到3。
[root@ku8-1 tmp]# kubectl scale --current-replicas=1 --replicas=3 deployment/nginx
deployment "nginx" scaled
通过确认发现已经进行了横向扩展,除了192.168.132.132,另外133和134两台机器也各有一个pod运行了起来,这正是scale命令的结果。
[root@ku8-1 tmp]# kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 3 3 3 3 2m
[root@ku8-1 tmp]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-74tpk 1/1 Running 0 2m 172.200.26.2 192.168.32.132
nginx-2476590065-cm5d9 1/1 Running 0 16s 172.200.44.2 192.168.32.133
nginx-2476590065-hmn9j 1/1 Running 0 16s 172.200.59.2 192.168.32.134
kube autoscale ★★★★
autoscale命令用于自动扩展确认,跟scale不同的是前者还是需要手动执行,而autoscale则会根据负载进行调解。而这条命令则可以对Deployment/ReplicaSet/RC进行设定,通过最小值和最大值的指定进行设定,这里只是给出执行的结果,不再进行实际的验证。
[root@ku8-1 tmp]# kubectl autoscale deployment nginx --min=2 --max=5
deployment "nginx" autoscaled
当然使用还会有一些限制,比如当前3个,设定最小值为2的话会出现什么样的情况?
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-74tpk 1/1 Running 0 5m 172.200.26.2 192.168.32.132
nginx-2476590065-cm5d9 1/1 Running 0 2m 172.200.44.2 192.168.32.133
nginx-2476590065-hmn9j 1/1 Running 0 2m 172.200.59.2 192.168.32.134
[root@ku8-1 tmp]# kubectl autoscale deployment nginx --min=2 --max=2
Error from server (AlreadyExists): horizontalpodautoscalers.autoscaling "nginx" already exists
kubectl cordon 与 uncordon ★★★
在实际维护的时候会出现某个node坏掉,或者做一些处理,暂时不能让生成的pod在此node上运行,需要通知kubernetes让其不要创建过来,这条命令就是cordon,uncordon则是取消这个要求。例子如下:
创建了一个nginx的pod,跑在192.168.32.133上。
[root@ku8-1 tmp]# kubectl create -f nginx/
deployment "nginx" created
service "nginx" created
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-dnsmw 1/1 Running 0 6s 172.200.44.2
192.168.32.133
执行scale命令 ★★★
横向扩展到3个副本,发现利用roundrobin策略每个node上运行起来了一个pod,134这台机器也有一个。
[root@ku8-1 tmp]# kubectl scale --replicas=3 deployment/nginx
deployment "nginx" scaled
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-550sm 1/1 Running 0 5s 172.200.26.2 192.168.32.132
nginx-2476590065-bt3bc 1/1 Running 0 5s 172.200.59.2 192.168.32.134
nginx-2476590065-dnsmw 1/1 Running 0 17s 172.200.44.2 192.168.32.133
[root@ku8-1 tmp]# kubectl get pods -o wide |grep 192.168.32.134
nginx-2476590065-bt3bc 1/1 Running 0 12s 172.200.59.2 192.168.32.134
执行cordon命令
设定134,使得134不可使用,使用get node确认,其状态显示SchedulingDisabled。
[root@ku8-1 tmp]# kubectl cordon 192.168.32.134
node "192.168.32.134" cordoned
[root@ku8-1 tmp]# kubectl get nodes -o wide
NAME STATUS AGE EXTERNAL-IP
192.168.32.132 Ready 1d <none>
192.168.32.133 Ready 1d <none>
192.168.32.134 Ready,SchedulingDisabled 1d <none>
执行scale命令
再次执行横向扩展命令,看是否会有pod漂到134这台机器上,结果发现只有之前的一个pod,再没有新的pod漂过去。
[root@ku8-1 tmp]# kubectl scale --replicas=6 deployment/nginx
deployment "nginx" scaled
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-550sm 1/1 Running 0 32s 172.200.26.2 192.168.32.132
nginx-2476590065-7vxvx 1/1 Running 0 3s 172.200.44.3 192.168.32.133
nginx-2476590065-bt3bc 1/1 Running 0 32s 172.200.59.2 192.168.32.134
nginx-2476590065-dnsmw 1/1 Running 0 44s 172.200.44.2 192.168.32.133
nginx-2476590065-fclhj 1/1 Running 0 3s 172.200.44.4 192.168.32.133
nginx-2476590065-fl9fn 1/1 Running 0 3s 172.200.26.3 192.168.32.132
[root@ku8-1 tmp]# kubectl get pods -o wide |grep 192.168.32.134
nginx-2476590065-bt3bc 1/1 Running 0 37s 172.200.59.2 192.168.32.134
执行uncordon命令
使用uncordon命令解除对134机器的限制,通过get node确认状态也已经正常。
[root@ku8-1 tmp]# kubectl uncordon 192.168.32.134
node "192.168.32.134" uncordoned
[root@ku8-1 tmp]#
[root@ku8-1 tmp]# kubectl get nodes -o wide
NAME STATUS AGE EXTERNAL-IP
192.168.32.132 Ready 1d <none>
192.168.32.133 Ready 1d <none>
192.168.32.134 Ready 1d <none>
执行scale命令
再次执行scale命令,发现有新的pod可以创建到134node上了。
[root@ku8-1 tmp]# kubectl scale --replicas=10 deployment/nginx
deployment "nginx" scaled
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-550sm 1/1 Running 0 1m 172.200.26.2 192.168.32.132
nginx-2476590065-7vn6z 1/1 Running 0 3s 172.200.44.4 192.168.32.133
nginx-2476590065-7vxvx 1/1 Running 0 35s 172.200.44.3 192.168.32.133
nginx-2476590065-bt3bc 1/1 Running 0 1m 172.200.59.2 192.168.32.134
nginx-2476590065-dnsmw 1/1 Running 0 1m 172.200.44.2 192.168.32.133
nginx-2476590065-fl9fn 1/1 Running 0 35s 172.200.26.3 192.168.32.132
nginx-2476590065-pdx91 1/1 Running 0 3s 172.200.59.3 192.168.32.134
nginx-2476590065-swvwf 1/1 Running 0 3s 172.200.26.5 192.168.32.132
nginx-2476590065-vdq2k 1/1 Running 0 3s 172.200.26.4 192.168.32.132
nginx-2476590065-wdv52 1/1 Running 0 3s 172.200.59.4 192.168.32.134
kubectl drain ★★★★★
drain命令用于对某个node进行设定,是为了设定此node为维护做准备。英文的drain有排干水的意思,下水道的水之后排干后才能进行维护。那我们来看一下kubectl”排水”的时候都作了什么
将nginx的副本设定为4,确认发现134上启动了两个pod。
[root@ku8-1 tmp]# kubectl create -f nginx/
deployment "nginx" created
service "nginx" created
[root@ku8-1 tmp]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-d6h8f 1/1 Running 0 8s 172.200.59.2 192.168.32.134
[root@ku8-1 tmp]#
[root@ku8-1 tmp]# kubectl get nodes -o wide
NAME STATUS AGE EXTERNAL-IP
192.168.32.132 Ready 1d <none>
192.168.32.133 Ready 1d <none>
192.168.32.134 Ready 1d <none>
[root@ku8-1 tmp]#
[root@ku8-1 tmp]# kubectl scale --replicas=4 deployment/nginx
deployment "nginx" scaled
[root@ku8-1 tmp]#
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-9lfzh 1/1 Running 0 12s 172.200.59.3 192.168.32.134
nginx-2476590065-d6h8f 1/1 Running 0 1m 172.200.59.2 192.168.32.134
nginx-2476590065-v8xvf 1/1 Running 0 43s 172.200.26.2 192.168.32.132
nginx-2476590065-z94cq 1/1 Running 0 12s 172.200.44.2 192.168.32.133
执行drain命令
执行drain命令,发现这条命令做了两件事情:
设定此node不可以使用(cordon)
evict了其上的两个pod
[root@ku8-1 tmp]# kubectl drain 192.168.32.134
node "192.168.32.134" cordoned
pod "nginx-2476590065-d6h8f" evicted
pod "nginx-2476590065-9lfzh" evicted
node "192.168.32.134" drained
结果确认
evict的意思有驱逐和回收的意思,让我们来看一下evcit这个动作的结果到底是什么。 结果是134上面已经不再有pod,而在132和133上新生成了两个pod,用以替代在134上被退场的pod,而这个替代的动作应该是replicas的机制保证的。所以drain的结果就是退场pod和设定node不可用(排水),这样的状态则可以进行维护了,执行完后重新uncordon即可。
[root@ku8-1 tmp]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2476590065-1ld9j 1/1 Running 0 13s 172.200.44.3 192.168.32.133
nginx-2476590065-ss48z 1/1 Running 0 13s 172.200.26.3 192.168.32.132
nginx-2476590065-v8xvf 1/1 Running 0 1m 172.200.26.2 192.168.32.132
nginx-2476590065-z94cq 1/1 Running 0 55s 172.200.44.2 192.168.32.133
[root@ku8-1 tmp]#
[root@ku8-1 tmp]# kubectl get nodes -o wide
NAME STATUS AGE EXTERNAL-IP
192.168.32.132 Ready 1d <none>
192.168.32.133 Ready 1d <none>
192.168.32.134 Ready,SchedulingDisabled 1d <none>
4.0 kubectl 深入解读
kubectl cluster-info 查看集群信息
kubectl version 显示命令行和kube服务端的版本
kubectl api-versions 显示支持的api版本集合
kubectl config view 显示当前kubectl的配置信息
kubectl logs 查看pod日志
kubectl exec -t [podname] /bin/bash 以交互模式进入容器执行命令
kubectl scale 实现水平或收缩
kubectl rollout status deploy [name]部署状态变更状态检查
kubectl rollout history 部署历史
kubectl rollout undo 回滚部署到最近或者某个版本
kubectl get nodes 查看集群中的节点
kubectl get [type] [name] 查看某种类型资源
kubectl describe [type] [name] 查看特定资源实例详情
kubectl get ep 查看路由端点信息
kubectl set image deploy [deployment-name] [old-image-name]=[new-image-name] 为部署设置镜像
kubectl cordon [nodeid] 标记节点不接受调度
kubectl uncordon [nodeid] 恢复节点可以接受调度
kubectl drain [nodeid] 驱赶该节点上运行的所有容器到其他可用节点
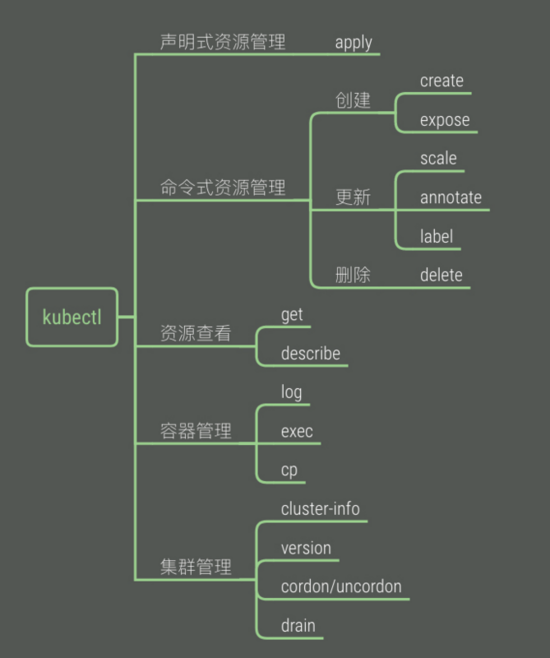
这里把Kubectl常用子命令大概分为以下几类:
语法
$ kubectl [command] [TYPE] [NAME] [flags]
command:子命令
TYPE:资源类型
NAME:资源名称
flags:命令参数
命令帮助
kubectl命令的帮助很详细, kubectl -h 会列出所有的子命令,在任何子命令后跟 -h,都会输出详细的帮助以及用例,遇到问题可以随时查看帮助。
资源对象
kubectl大部分子命令后都可以指定要操作的资源对象,可以用 kubectl api-resources 命令参考
全局参数
kubectl options 命令可以列出可以全局使用的命令参数,比较重要的有:
--cluster='': 指定命令操作对象的集群
--context='': 指定命令操作对象的上下文
-n, --namespace='': 指定命令操作对象的Namespace
资源字段
kubectl explain 命令可以输出资源对应的属性字段及定义,在定义资源配置文件时候非常有用。
# Usage:
kubectl explain RESOURCE [options]
# Examples:
$ kubectl explain deployment.spec.selector
KIND: Deployment
VERSION: extensions/v1beta1
RESOURCE: selector <Object>
DESCRIPTION:
Label selector for pods. Existing ReplicaSets whose pods are selected by
this will be the ones affected by this deployment.
A label selector is a label query over a set of resources. The result of
matchLabels and matchExpressions are ANDed. An empty label selector matches
all objects. A null label selector matches no objects.
FIELDS:
matchExpressions <[]Object>
matchExpressions is a list of label selector requirements. The requirements
are ANDed.
matchLabels <map[string]string>
matchLabels is a map of {key,value} pairs. A single {key,value} in the
matchLabels map is equivalent to an element of matchExpressions, whose key
field is "key", the operator is "In", and the values array contains only
"value". The requirements are ANDed.
声明式资源对象管理
对集群资源的声明式管理,是Kubernetes最主要的特性之一,而kubectl apply命令是最能体现这个特性的命令。apply命令最主要的参数有两个:
# Usage:
kubectl apply (-f FILENAME | -k DIRECTORY) [options]
-f 参数后跟yaml或 json 格式的资源配置文件,-k 参数后跟kustomization.yaml配置文件的位置。
为什么说apply是声明式管理呢,因为所有对集群的增改操作,都能用apply命令完成,一切取决于后面的配置文件:
如果配置文件中的资源找集群中不存在,则创建这个资源。
如果配置文件中的资源在集群中已存在,则根据配置对资源字段进行更新
举个例子:
# 部署一个goweb应用,配置pod数为4个:
[root@master-1 ~]# grep replicas deployment-goweb.yaml
replicas: 4
# 使用 apply 创建资源
[root@master-1 ~]# kubectl apply -f deployment-goweb.yaml
deployment.apps/goweb created
[root@master-1 ~]# kubectl get po
NAME READY STATUS RESTARTS AGE
goweb-6b5d559869-4x5mb 1/1 Running 0 14s
goweb-6b5d559869-77lbz 1/1 Running 0 14s
goweb-6b5d559869-9ztkh 1/1 Running 0 14s
goweb-6b5d559869-ccjtp 1/1 Running 0 14s
# 修改pod数量为2个:
[root@master-1 ~]# sed -ri 's/4$/2/g' deployment-goweb.yaml
[root@master-1 ~]# grep replicas deployment-goweb.yaml
replicas: 2
# 使用apply更新资源
[root@master-1 ~]# kubectl apply -f deployment-goweb.yaml
deployment.apps/goweb configured
[root@master-1 ~]# kubectl get po
NAME READY STATUS RESTARTS AGE
goweb-6b5d559869-4x5mb 1/1 Running 0 8m21s
goweb-6b5d559869-77lbz 1/1 Running 0 8m21s
# pod数已更新为2个
可以看到,同一个 kubectl apply -f deployment-goweb.yaml 命令,可以用来创建资源也可以更新资源。
简单来说,apply命令的作用就是一个:使集群的实际状态朝用户声明的期望状态变化,而用户不用关心具体要进行怎样的增删改操作才能呢达到这个期望状态,也即Kubernetes的声明式资源管理。
命令式资源对象管理
命令式管理类就是直接通过命令执行增删改的操作,除了删除资源外,下面的命令能用apply代替,kubernetes也建议尽量使用apply命令。
创建资源
kubectl create deployment my-dep --image=busybox # 创建一个deplpyme
kubectl expose rc nginx --port=80 --target-port=8000 # 创建一个svc,暴露 nginx 这个rc
更新资源
kubectl scale --replicas=3 -f foo.yaml # 将foo.yaml中描述的对象扩展为3个
kubectl annotate pods foo description='my frontend' # 增加description='my frontend'备注,已有保留不覆盖
kubectl label --overwrite pods foo status=unhealthy # 增加status=unhealthy 标签,已有则覆盖
删除资源
kubectl delete -f xxx.yaml # 删除一个配置文件对应的资源对象
kubectl delete pod,service baz foo # 删除名字为baz或foo的pod和service
kubectl delete pods,services -l name=myLabel # -l 参数可以删除包含指定label的资源对象
kubectl delete pod foo --grace-period=0 --force # 强制删除一个pod,在各种原因pod一直terminate不掉的时候很有用
查看资源状态
get
最常用的查看命令,显示一个或多个资源的详细信息
# Usage:
kubectl get
[(-o|--output=)](TYPE[.VERSION][.GROUP] [NAME | -l label] | TYPE[.VERSION][.GROUP]/NAME ...) [flags]
[options]
# Examples:
kubectl get services # 列出当前NS中所有service资源
kubectl get pods --all-namespaces # 列出集群所有NS中所有的Pod
kubectl get pods -o wide # -o wide也比较常用,可以显示更多资源信息,比如pod的IP等
kubectl get deployment my-dep # 可以直接指定资源名查看
kubectl get deployment my-dep --watch # --watch 参数可以监控资源的状态,在状态变换时输出。在跟踪服务部署情况时很有用
kubectl get pod my-pod -o yaml # 查看yaml格式的资源配置,这里包括资实际的status,可以用--export排除
kubectl get pod my-pod -l app=nginx # 查看所有带有标签app: nginx的pod
kubectl 可用JSONPATH来过滤字段,JSON Path的语法可参考 这里
kubectl get pods --selector=app=cassandra rc -o jsonpath='{.items[*].metadata.labels.version}' # 获取所有具有 app=cassandra 的 pod 中的 version 标签
describe
describe命令同样用于查看资源信息,但相比与get只输出资源本身的信息,describe聚合了相关资源的信息并输出。比如,在describe node信息时,同时会输出该node下的pod的资源利用情况。所以describe命令在排错和调试时非常有用。
# Usage:
kubectl describe (-f FILENAME | TYPE [NAME_PREFIX | -l label] | TYPE/NAME) [options]
# Examples:
kubectl describe nodes my-node # 查看节点my-node的详细信息
kubectl describe pods my-pod # 查看pod my-pod的详细信息
容器管理
虽然逻辑上,Kubernetes的最小管理单位是Pod,但是实际上还是免不了与容器直接交互,特别是对于多容器的Pod,任意容器有问题,都会导致Pod不可用。
日志查看
# Usage:
kubectl logs [-f] [-p] (POD | TYPE/NAME) [-c CONTAINER] [options]
# Examples:
kubectl logs my-pod
# 输出一个单容器pod my-pod的日志到标准输出
kubectl logs nginx-78f5d695bd-czm8z -c nginx
# 输出多容器pod中的某个nginx容器的日志
kubectl logs -l app=nginx
# 输出所有包含app-nginx标签的pod日志
kubectl logs -f my-pod
# 加上-f参数跟踪日志,类似tail -f
kubectl logs my-pod -p
# 输出该pod的上一个退出的容器实例日志。在pod容器异常退出时很有用
kubectl logs my-pod --since-time=2018-11-01T15:00:00Z
# 指定时间戳输出日志
kubectl logs my-pod --since=1h
# 指定时间段输出日志,单位s/m/h
执行命令
命令作用和参数基本与docker exec一致
# Usage:
kubectl exec POD [-c CONTAINER] -- COMMAND [args...] [options]
# Examples:
kubectl exec my-pod ls # 对my-pod执行ls命令
kubectl exec -t -i nginx-78f5d695bd-czm8z bash # 进入pod的shell,并打开伪终端和标准输入
文件传输
在排错和测试服务的时候,时不时需要和容器互相交互文件,比如传输容器内存的dump到宿主机,或从宿主机临时拷贝个新配置文件做调试,这时就可以用*kubectl cp命令。要注意的是,cp命令需要容器里已安装有tar程序
# Usage:
kubectl cp <file-spec-src> <file-spec-dest> [options]
# Examples:
kubectl cp /tmp/foo_dir <some-pod>:/tmp/bar_dir # 拷贝宿主机本地文件夹到pod
kubectl cp <some-namespace>/<some-pod>:/tmp/foo /tmp/bar # 指定namespace的拷贝pod文件到宿主机本地目录
kubectl cp /tmp/foo <some-pod>:/tmp/bar -c <specific-container> # 对于多容器pod,用-c指定容器名
集群管理
除了和具体的资源打交道,在对集群进行维护时,也经常需要查看集群信息和对节点进行管理,集群管理有以下这些常用的命令:
集群信息查看
kubectl cluster-info # 查看master和集群服务的地址
kubectl cluster-info dump # 查看集群详细日志
kubectl version # 查看Kubernetes集群和客户端版本
节点管理
在集群节点出问题时,可能希望把一个节点不再被调度pod,或把节点目前的pod都驱逐出去
kubectl cordon my-node
# 标记 my-node 为 unschedulable,禁止pod被调度过来。注意这时现有的pod还会继续运行,不会被驱逐。
kubectl uncordon my-node
# 与cordon相反,标记 my-node 为 允许调度。
kubectl drain my-node
# drain字面意思为排水,实际就是把my-node的pod平滑切换到其他node,同时标记pod为unschedulable,也就是包含了cordon命令。
# 但是直接使用命令一般不会成功,建议在要维护节点时,加上以下参数:
kubectl drain my-node --ignore-daemonsets --force --delete-local-data
# --ignore-daemonsets 忽略daemonset部署的pod
# --force 直接删除不由workload对象(Deployment、Job等)管理的pod
# --delete-local-data 直接删除挂载有本地目录(empty-dir方式)的pod