1
2、Python Web框架介绍
1、什么是框架?
框架,即framework,特指为解决一个开放性问题而设计的具有一定约束性的支撑结构,使用框架可以帮你快速开发特定的系统,简单说就是使用别人搭好的舞台,你来做表演。
2、常见的Python Web框架:
Full-Stack Frdmeworks(全栈框架、重量级框架):Django,web2py、TurboGears.Pylons..…Non Full-Stack Frameworks(非全栈框架、轻量级的框架):tornado、Flask、Bottle、web.py、Pyramid、…
3、这么多框架,如何选择?
1、根据项目需求去选择。
内容支撑 djangoapp网络接口
2、根据框架的特点去选择
django、tornado、flask、bottletornado 性能高
4.django-admin.py & manage.py
django-admin.py是Django的一个用于管理任务的命令行工具,manage.py是对django-admin.py的简单包装,每个Django Project里面都会包含一个manage.py
语法:
django-admin.py <subcommand>[options]manage.py <subcommand> [options]subcommand是子命令;options是可选的常用子命令:
startproject:创建一个项目(*)startapp:创建一个app(*)runserver:运行开发服务器(*)shell:进入django shell(*)dbshell:进入django dbshellcheck:检查django项目完整性flush:清空数据库compilemessages:编译语言文件makemessages:创建语言文件makemigrations:生成数据库同步脚本(*)migrate:同步数据库(*)showmigrations:查看生成的数据库同步脚本(*)sqlflush:查看生成清空数据库的脚本(*)sqlmigrate:查看数据库同步的sql语句(*)dumpdata:导出数据loaddata:导入数据diffsettings:查看你的配置和django默认配置的不同之处manage.py特有的一些子命令:
createsuperuser:创建超级管理员(*)changepassword:修改密码(*)clearsessions:清除session
5、快速创建一个网页
本课学习目标:
10分钟快速搭建一个查询用户列表的页面。注册app到配置文件第一步,在views.py里面定义一个业务请求处理的函数第二步,定义一个模板并引入静态文件第三步,在urls.py里面定义url地址第四步,启动服务第五步,把用户数据查询出来并渲染到页面上
课后思考:
1、目前模板和静态文件都是放在app的目录下面的,如果我想把模板目录和静态文件放到项目根目录下怎么做;2、目前我app的url是直接定义在工程目录下的urls.py下面的,我想定义到app下面的urls.py可以怎么做?3、想想模板渲染的过程,静态文件引入的标签最终变成什么了?
目录结构:
manage.py:命令行工具脚本hello_django(project):
settings.py:项目配置urls.py:URL配置wsgipy:WSGI配置
hello(app):
migrations:数据库同步脚本目录admin.py:admin配置apps.py:app配置models.py:模型代码tests.py:单元测试views.py:业务代码
6、mtv开发模式
上一节课的思考题:
1、目前模板和静态文件都是放在app的目录下面的,如果我想把模板目录和静态文件放到项目根目录下怎么做;2、目前我app的url是直接定义在工程目录下的urls.py下面的,我想定义到app下面的urls.py可以怎么做?3、想想模板渲染的过程,静态文件引入的标签最终变成什么了?
上一节课,大家快速创建了一个网页。这个网页的运行机制是怎样的呢?
从著名的MVC模式说起
所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的、松耦合的方式连接在一起,模型负责业务对象与数据库的映射(ORM),视图负责与用户的交互(页面面,控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示:
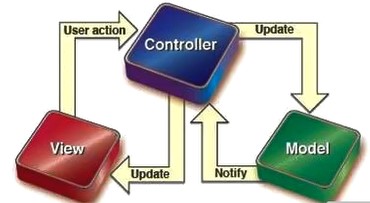
Django的MTV模式本质上和MVC是一样的,也是为了各组件间保持松耦合关系,只是定义上有些许不同,Django
的MTV分别是值:
M代表模型(Model):负责业务对象和数据库的关系映射(ORM)。T代表模板(Template):负责如何把页面展示给用户(html)。V代表视图(View):负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再
调用相应的Model和Template,MTV的响应模式如下所示:

1,Web服务器(中间件)收到一个http请求2,Django在URLconf里查找对应的视图(View)函数来处理http请求3,视图函数调用相应的数据模型来存取数据、调用相应的模板向用户展示页面4,视图函数处理结束后返回一个http的响应给Web服务器5,Web服务器将响应发送给客户端
这种设计模式关键的优势在于各种组件都是松耦合的。这样,每个由Django驱动的Web应用都有着明确的目的,并
且可独立更改而不影响到其它的部分。
比如,开发者更改一个应用程序中的URL而不用影响到这个程序底层的实现。设计师可以改变HTML页面的样式而
不用接触Python代码。
数据库管理员可以重新命名数据表并且只需更改模型,无需从一大堆文件中进行查找和替换。
落到实处,Django的MTV模式相对应的python文件如下:

7、urls.py详解
urls.py:URL分发器(路由配置文件)
URL配置(URLconf)就像是Django所支撑网站的目录。它的本质是URL模式以及要为
该URL 模式调用的视图函数之间的映射表。你就是以这种方式告诉Django,对于这个
URL 调用这段代码,对于那个URL调用那段代码。URL的加载是从配置文件中开始。
1、urlpatterns的两种形式:
没有前缀的情况,使用的列表(推荐方式)
urlpatterns=[ur1(r'hel1o/$",views.hel1o)]
有前缀的情况,使用patterns方法,过时的方法
from django.conf.urls import url,patternsfrom hello import viewsurlpatterns = patterns(",(r'^hello/$',views.hello),)或者from django.conf.urls import patternsurlpatterns = patterns('hello',(r'^hello/$','views.hello'),)
2、URL模式:
urlpatterns=[
url(正则表达式,view函数,参数,别名,前缀)]
参数说明:
*一个正则表达式字符串。*一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串[1.10后被遗弃已经不再使用]。*可选的要传递给视图函数的默认参数(字典形式)。*一个可选的name参数。*路径前缀[被遗弃]
urlpatterns=[
url(r'^hello/','views.hello',{'a':'123'},'hello','hello'),url(r'^test/(?P<id>d{2})/(?P<key>w+)/$','hello.views.test')
]
3、URL分解器,include函数:
通常一个URL分解器对应一个URL配置模块,它可以包含多个URL模式,也可以包含
多个其他URL分解器。通过这种包含结构设计,实现Django对URL的层级解析。
URL分解器是Django实现app与项目解耦的关键。通常由include方法操作的URL
配置模块,最终会被解释成为URL分解器。
上节课预留的问题,为什么admin模块引入的时候没有使用include
url(r'admin/',admin.site.urls)
4、URL常见写法示例,正则表达式
url(r'^test/d{2}/$',views.test)url(r'^test/(?P<id>d{2})/$',views.test)url(r'^test2/(?P<id>d{2})/(?P<key>w+)/$',views.test)
--------
8、views.py详解
1、http请求中产生的两个核心对象:
/Web 服务器
http请求:HttpRequesthttp响应:HttpResponse
所在位置:django.http
from django.shortcuts import render
from django.contrib.auth.models import User
from django.http import HttpRequest, HttpResponse
1、HttpRequest:
HttpRequest对象的属性:
Attribute |Description
path 请求页面的全路径,不包括域名一例如,
"/music/bands/the_beatles/"。
method 请求中使用的HTTP方法的字符串表示。全大写表示。例如:
if request.method=='GET':do_something()elif request.method =='POST':do_something_else()
GET 包含所有HTTP GET参数的类字典对象。参见QueryDict文档。
POST 包含所有HTTP POST参数的类字典对象。参见QueryDict文档。
服务器收到空的POST请求的情况也是有可能发生的。也就是说,表单form通过HTTP POST方法提交请求,但是表单中可以没有数据。因此,不能使用语句if request.POST来判断是否使用HTTP POST方法;应该使用if request.method=="POST"(参见本表的method属性)。注意:POST不包括file-upload信息。参见FILES属性。
REQUEST 'WSGIRequest' object has no attribute 'REQUEST'[被遗弃]
FILES 包含所有上传文件的类字典对象。FILES中的每个Key都是<input
type="file"name=""/>标签中name属性的值.FILES中的每个value 同时也是一个标准Python字典对象,包含下面三个Keys:·filename:上传文件名,用Python字符串表示·content-type:上传文件的Content type·content:上传文件的原始内容注意:只在请求方法是POST,并且请求页面中<form>有enctype="multipart/form-data"属性时FILES才拥有数据。否则,FILES是一个空字典。
META 包含所有可用HTTP头部信息的字典。例如:
·CONTENT_LENGTH·CONTENT_TYPE·QUERY_STRING:未解析的原始查询字符串·REMOTE_ADDR:客户端IP地址·REMOTE_HOST:客户端主机名·SERVER_NAME:服务器主机名·SERVER_PORT:服务器端口META中这些头加上前缀HTTP_最为Key,例如:·HTTP_ACCEPT_ENCODING·HTTP_ACCEPT_LANGUAGE·HTTP_HOST:客户发送的HTTP主机头信息·HTTP_REFERER:referring页·HTTP_USER_AGENT:客户端的user-agent字符串·HTTP_X_BENDER:X-Bender头信息
user 是一个django.contrib.auth.models.User对象,代表当前登录的用户。
如果访问用户当前没有登录,user将被初始化为
django.contrib.auth.models.AnonymousUser的实例。你可以通过user的is_authenticated()方法来辨别用户是否登录:if request.user.is_authenticated():#Do something for logged-in users.else:#Do something for anonymous users.只有激活Django中的AuthenticationMiddleware时该属性才可用
session 唯一可读写的属性,代表当前会话的字典对象。只有激活Django中的
session支持时该属性才可用。参见第12章。
raw_post_data 原始HTTPPOST数据,未解析过。高级处理时会有用处。
HttpRequest对象的方法(部分):
get_full_path() 返回包含查询字符串的请求路径。例如,
"/music/bands/the_beatles/?print=true"
QueryDict对象(部分)
get() 如果key对应多个value, get()返回最后一个value。
在HttpRequest对象中,GET和POST属性是django.http.QueryDict类的实例。
2、HttpResponse:
对于HttpRequest对象来说,是由Django自动创建,但是,HttpResponse对象就必
须我们自己创建。每个View方法必须返回一个HttpResponse对象。
HttpResponse类在django.http.HttpResponse。
构造HttpResponse:
>>>response=HttpResponse("Here's the text of the Web page.")
>>>response=HttpResponse("Text only,please.",mimetype="text/plain")
HttpResponse的子类(部分):
Class Description
HttpResponseRedirect 构造函数接受单个参数:重定向到的URL。可以
是全URL(e.g.,http://search.yahoo.com/")或者相对URL(e.g.,"/search/").注意:这将返回HTTP状态码302
HttpResponsePermanentRedirect 同HttpResponseRedirect一样,但是返回永久
重定向(HTTP状态码301)。
redirect 实现
HttpResponseNotFound 返回404 status code.
JsonResponse 返回Json字符串。
2、在HttpResponse对象上扩展的常用方法
render、render_to_response、redirect
更多详见:
https://docs.djangoproject.com/en/2.1/topics/http/shortcuts/
反回原生httpresponse
from django.http import HttpResponsefrom django.template import loaderdef my_view(request):# View code here...t=loader.get_template(' myapp/index. html')c={'foo':' bar'}return HttpResponse(t. render(c, request),content_type="application/xhtml+xml")
from django.shortcuts import render, render_to_response,redirect
9、数据库的配置
1、django默认支持sqlite、mysql、oracle、postgresq数据库,像db2和
sqlserver之类的数据库需要第三方的支持。具体详见:
sqlite:
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动
引擎名称:
django.db.backends.sqlite3
mysql:
引擎名称:
django.db.backends.mysql
2、mysql驱动程序:
MySQLdb:https://pypipython.org/pypi/MySQL-python/1.2.5mysqlclient:https://pypipython.org/pypi/mysqlclientMySQLConnector/Python: https://dev.mysql.com/downloads/connector/pythonPyMySQL(纯python的mysq区动):https://pypi.python.org/pypi/PyMysQL
3、演示pymysql的使用。
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'hello_django_db',
'USER': 'root',
'PASSWORD': '1234',
# 'HOST': '',
# 'PORT': '',
}
}
import pymysql
pymysql.instal1_as_MySQLdb()
11 orm机制讲解
1、定义:
对象关系映射(英语:Object Relational Mapping,简称ORM),用于实现面向对象编程语言里不同类型系统的数据之间的转换。换句话说,就是用面向对象的方式去操作数据库的创建表,增加、修改、删除、查询等操作。
2、演示:查看ORM生成的sql语句。
A、使用QuerySet中的query属性B、配置日志系统,将sql显示到控制台
django日志的详细使用详见:https://docs.djangoproject.com/en/2.1/topics/logging/
C、使用一些开发工具,django_debug_toolbar。
1 SELECTauth_user. id,' auth_user.' password,' auth_user.' last_login",' auth_user. ia
2 select * from auth #效率低
STATIC_URL = '/static/'
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'),
)
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
3、ORM优缺点:
优点:
1、ORM使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。2、可以避免一些新手程序猿写sql语句带来的性能效率和安全问题。
缺点:
1、性能有所牺牲,不过现在的各种ORM框架都在尝试使用各种方法来减轻这个问题(LazyLoad,Cache),效果还是很显著的。2、对于个别复杂查询,ORM仍然力不从心。为解决这个问题,ORM框架一般也提供了直接写原生sql的方式。
12 models.py-模型类的定义
一、创建数据模型。
实例:
我们来假定下面的这些概念、字段和关系:
作者模型:一个作者有姓名。
作者详情模型:把作者的详情放到详情表,包含性别、email 地址和出生日
期,作者详情模型和作者模型之间是一对一的关系(OneToOneField)
出版商模型:出版商有名称,地址,所在城市、省,国家,网站。
书籍模型:书籍有书名和出版日期。一本书可能会有多个作者,一个作者也
可以写多本书,所以作者和书籍的关系是多对多的关联关系[many-to-
many],一本书只应该由一个出版商出版,所以出版商和书籍是一对多的关
联关系[one-to-many],也被称作外键[Foreignkey]。
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30, verbose_name="名称")
address = models.CharField("地址", max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Meta:
verbose_name = '出版商'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=30)
class AuthorDetail(models.Model):
sex = models.BooleanField(max_length=1, choices=((0, '男'),(1, '女'),))
email = models.EmailField()
address = models.CharField(max_length=50)
birthday = models.DateField()
author = models.OneToOneField(Author)
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
一起来看看上面的代码:
1、每个数据模型都是django.db.models.Model的子类。它的父类Model包含了所有必要的和数据库交互的方法,并提供了一个简洁漂亮的定义数据库字段的语法。2、每个模型相当于单个数据库表(这条规则的例外情况是多对多关系,多对对关系的时候会多生成一张关系表),每个属性也是这个表中的一个字段。属性名就是字段名,它的类型(例如 CharField)相当于数据库的字段类型(例如varchar)。大家可以留意其他的类型都和数据库里面的什么字段类型对应。
一对一 实质上也是主外键的关系,只不过多了Unique的约束
一对多 用外键关联 ForeignKey 不是 Unique的约束
多对多 生成第三张表
4、模型的常用字段类型
1、BooleanField:布尔类型字段2、CharField:字符串类型字段3、DateField:日期字段4、DateTimeField:日期时间字段5、DecimalField:(精确)小数字段6、EmailField:Email字段7、FileField:文件字段(保存和处理上传的文件)8、FloatField:(浮点数)小数字段9、ImageField:图片字段(保存和处理上传的图片)10、IntegerField:整数字段11、IPAddressField:IP字段12、SmalIntegerField:小整数字段13、TextField:文本字段14、URLField:网页地址字段
5、模型常用的字段选项
1、null(null=TruelFalse)数据库字段的设置是否可以为空(数据库进行验证)2、blank(blank=TruelFalse)字段是否为空django会进行效验(表单进行验证)3、choices 轻量级的配置字段可选属性的定义4、default 字段的默认值5、help_text 字段文字帮助6、primary_key(=TruelFalse)一般情况不需要进行定义是否主键,如果没有显示指明主键的话,django会自动增加一个默认主键:id=models.AutoField(primary_key=True)7、unique 是否唯一,对于数据表而言。8、verbose_name 字段的详细名称,如果不指定该属性,默认使用字段的属性名称
字段类型和字段选项的设置更多详见:
https://docs.djangoproject.com/en/2.1/ref/models/fields/
name = models.CharField(max_length=30, verbose_name="名称") #不指明,则显示name
address = models.CharField("地址", max_length=50) # 简便的设置
13
二、定义数据模型的扩展属性,
通过内部类Meta给数据模型类增加扩展属性:class Meta:verbose_name=名称’verbose_name_plural='名称复数形式’ordering=['排序字段]还有很多扩展属性,更多详见:
https://docs.djangoproject.com/en/2.1/ref/models/options/
三、定义模型的方法
定义模型方法和普通python类方法没有太大差别,定义模型方法可以将当前对应的数据,组装成具体的业务逻辑。示例:定义__unicode__()让对象有个默认的名字注意:python2里面用_unicode_(),python3里面用_str_()def_str_(self):return self.name
12、models.py-数据库同步操作技巧
一、认识一个目录
目录名:migrations
作用:用来存放通过makemigrations命令生成的数据库脚本,不熟悉的情况
下,里面生成的脚本不要轻易修改。app目录下必须要有migrations的目录且
该目录下必须要有_init_.py才能正常的使用数据库同步的功能。
二、认识一张数据表(django_migrations)
表中的字段:app:app名字name:脚本的文件名称applied:脚本执行的时间
三、数据库相关的命令
flush:清空数据库-恢复数据库到最初状态不记录日志makemigrations:生成数据库同步的脚本 可以加app 操作单个同步app , makemigrations hellomigrate:同步数据库(*)showmigrations:查看生成的数据库同步脚本(*) [X] 表示已经执行sqlflush:查看生成清空数据库的脚本(*)sqlmigrate:查看数据库同步的sql语句(*)
终极大招:
在开发的过程中,数据库同步误操作之后,难免会遇到后面不能同步成功的情况,解决这个问题的方法,一是去分析生成的数据库脚本和django_migrations中的同步记录是否匹配,另外一个简单粗暴的方法就是把migrations目录下的脚本(除_init__.py)之外全部删掉,再把数据库删掉之后创建一个新的数据库,数据库同步操作再重新做一遍。
13、ORM常用操作
一、增加
create和save方法
实例:
1、增加一条作者记录
2、增加一条出版社记录
3、增加一条书籍记录
二、修改
update和save方法
实例:
1、修改id为1的作者的名字为叶良辰,性别改为女
2、修改名为“电子工业出版社"的出版社的网址为
http://www.maiziedu.com,城市为成都
>>>pub=Publisher()
>>>pub.name=‘电子工业出版社
>>>pub.address=‘成都华阳
>>>pub.city=‘成都’
>>>pub.state_prouince=‘四川’
>>>pub.country=‘中国
>>>pub.website=‘http://www.maiziedu.com
>>>pub.saue()
(0.002)INSERT INTO hello_publisher'(‘name',"address',citu','state_provi
e',country',website)UALUES(‘电子工业出版社,‘成都华阳‘,‘成都,“四川
·中国‘,‘http://www.maiziedu.com");args=[‘电子工业出版社‘,‘成都华阳‘,‘成都
·四川’,‘中国,‘http://www.maiziedu.com']
objects:model默认管理器。create是这个管理器里面的方法
插入主外键关系的时候,可以用对象的方式,也可以直接以关联id的方式。
插入多对多关系的时候要分步操作。
save的这个方法是model对象的方法
update是QuerySet对象的方法
三、查询(惰性机制)
实例:
1、查询所有的出版社信息
所谓惰性机制:Publisher.objects.all()只是返回了一个QuerySet(查询结果
集对象),并不会马上执行sql,而是当调用QuerySet的时候才执行。
四、删除
delete方法
实例:
1、删除id为1的书籍信息;
2、删除出版社城市为成都的记录;
注意:django中的删除默认是级联删除。
delete方法也是QuerySet对象的方法
课外思考:
去官方文档查查,有没有提供批量增加数据的方法。
多表查询技巧:
__ 两个下划线可以生成连接查询,查询关联的字段信息
_set:提供了对象访问相关联表数据的方法。但是这种方法只能是相关类访问定
义了关系的类(主键类(一)访问外键类(二))。
出版社相对于书是主键类,可以直接访问
>>>publisher.book.set.all()
(0.002) SELECT helo _book."id', hello_book'."title, hello_book."publisher
id', hello_book. publication_date' FROM "hello_book' WHERE hello_book'."publi
|sher_id'=6 LIMIT 21; args=(6,)
|[<Book: Book object>]
>>>publisher. book_set. all()
16、聚集查询和分组查询
1、annotate(*args,**kwargs):可以为QuerySet 中的每个对象添加注解。
可以通过计算查询结果中每个对象所关联的对象集合,从而得出总计值(也可
以是平均值或总和,等等),用于分组查询
2、aggregate(*args,**kwargs):通过对QuerySet 进行计算,返回一个聚
合值的字典。aggregate()中每个参数都指定一个包含在字典中的返回
值。用于聚合查询
聚合函数(Aggregation Functions)
所在位置:django.db.models
1、Avg
返回所给字段的平均值。
2、Count
根据所给的关联字段返回被关联model的数量。
Publisher.objects.filter(name='广东人民出版社').aggregate(Count('name')){'name__count': 1}Publisher.objects.filter(name='广东人民出版社').aggregate(mycpunt=Count('name')){'mycpunt': 1}
4、Max
返回所给字段的最大值
5、Min
返回所给字段的最小值
6、Sum
计算所给字段值的总和
>>>Book.objects.ualues('authors__name').annotate(Sum(‘price')
[{'price__sum':Decimal('252.00'),‘authors__name':'胡大海},{'price__sum':De
cimal('97.00),‘authors__name':‘王尼玛),{'price__sum':Decimal('62.00"),‘au
thors__name:‘郭德纲}]
>>>Book.objects.values('publisher__name").annotate(Min(‘price'))
[{‘price__min':Decimal(99.00'),‘publisher__name':‘安徽大学出版社),{'price_
_min':Decimal('35.00"),‘publisher__name':‘北京出版社),{'price__min':Decima
1(56.00"),‘publisher_name':'广东人民出版社,'pricemin':Decimal('70.00
),‘publisher__name:北京范大学出版社,{krice__min':Decimal("27.00),‘p
ub1isher__name:‘安徽科学技术出版社‘)]
17、使用原生sql
注意:使用原生sql的方式主要目的是解决一些很复杂的sql不能用ORM的方
式写出的问题。
一、extra:结果集修改器-一种提供额外查询参数的机制.
二、raw:执行原始sql并返回模型实例
三、直接执行自定义SQL
这种方式完全不依赖model,前面两种方式还是要依赖于model来看一些实例:
使用extra:1、Book.objects.filter(publisher_name='广东人民出版社).extra(where=Book.objects.filter(publisher_name='广东人民出版社”,price_gt=50)>>>Book.objects.extra(select={'count':'select count(*) from hello_book'})(0.001) SELECT(select coun(x) from hello_book) AS count,"hello_book. id',hello_book. title',"hello_book'."publisher_id', hello_book'."publication_date, hello_book. priceFROM hello_book' LIMIT 21; args=()[<Book: Book object>,<Book: Book object>,<Book: Book object〉,<Book: Book objest>,<Book: Book object>]>>>Book.objects.raw('select * from hello_book')<RawQuerySet:select x from hello_book>>>>bbb=Book.objects.raw('select x from hello_book")>>>for b in bbb:~print(b.title)(0.001)select x from hello_book;args=()|Python开发实战|论撩妹的重要性|Java开发实战|web开发从入门到放弃|21天成为撩妹高手
from django.db import connection
cursor=connection.cursor0#获得一个游标(cursor)对象
#插入操作I
cursor.execute("insert into hello_author(name)values(“郭敬明)")
#更新操作
cursor.execute("update hello_author set name='韩寒' where name='郭敬明”)
#删除操作
cursor.execute("delete from hello_author where name=韩寒”)
#查询操作
cursor.execute('select * from hello_author')
raw=cursor.fetchone()#返回结果行
cursor.fetchall()
18、常用模板标签及过滤器
一、模板的组成
HTML代码+逻辑控制代码。
二、逻辑控制代码的组成
1.变量(使用双大括号来引用变量)
{{var_name }}
2.标签(tag)的使用(使用大括号和百分号的组成来表示使用tag)
{% load staticfiles %}
3.过滤器(filter)的使用
{{ ship_date|date:"Fj,Y" }},ship_date变量传给data过滤器,data过滤器通
过使用“Fj,Y"这几个参数来格式化日期数据。"|"代表类似Unix命令中的管道操作。
三、常用标签(tag)
1、{%if%}的使用
可以使用and,or,not来组织你的逻辑。但不允许and和or同时出现的条件语
句中。新版本中已经支持(% elif %}这样的用法。
2、{%ifequal %}和(% ifnotequal%}的使用
比较是否相等,只限于简单的类型,比如字符串,整数,小数的比较,列
表,字典,元组不支持。
3、{%for%}的使用
用来循环一个list,还可以使用resersed关键字来进行倒序遍历,一般可以用if
语句来先判断一下列表是否为空,再进行遍历;还可以使用empty关键字来进行为空时候的跳转。
**for标签中可以使用forloop
a.forloop.counter 当前循环计数,从1开始b.forloop.counter0 当前循环计数,从0开始,标准索引方式c.forloop.revcounter 当前循环的倒数计数,从列表长度开始d.forloop.revcounterO当前循环的倒数计数,从列表长度减1开始,标准e.forloop.first bool值,判断是不是循环的第一个元素f.forloop.last 同上,判断是不是循环的最后一个元素g.forloop.parentloop 用在嵌套循环中,得到parent循环的引用,然后可以使用以上的参数
4、{% cycle%} 在循环时轮流使用给定的字符串列表中的值。
5、{##单行注释,{%comment%}多行注释
6、{%csrf_token%} 生成csrf_token的标签,用于防止跨站攻击验证。
使用render_to_response注意
导入RequestContext,指定上下文
from django.shortcuts import render, render_to_response, redirectfrom django.contrib.auth.models import Userfgom django.http import HttpRequest, HttpResponsefrom django.template import loader, RequestContextreturn render_to_response('tabre.html', locals(), context_instance=RequestContext(request))
7、{%debug %} 调用调试信息
8、{%filter%} 将filter 标签圈定的内容执行过滤器操作。
{% filter force_escape | upper %}This text will be HTML-escaped, and will appear in all lowercase.{% endfilter%}{{ value | upper}} # 通过变量调用过滤器
9、{% autoescape %} 自动转义设置
value5="<a href=''>百度</a>"
{% autoescape off%} [变量可以渲染显示标签元素,而不是转义成别的]{{value5}}(% endautoescape %}
10、{% firstof %} 输出第一个值不等于False的变量
11、{%load%} 加载标签库
12、{% now %} 获取当前时间
13、{% spaceless %} 移除空格
14、{%url%} 引入路由配置的地址
<form method="post" action="{% url 'test'%}"> 'test' 是路由别名,灵活方便更改
15、{%verbatim%} 禁止render
{% verbatim%}
{{ ver }} {#不渲染ver,前端显示本性{{ ver }} #}
{% endverbatim %}
16、{% with% } 用更简单的变量名缓存复杂的变量名
{% with total=fdsafsdafdsafdsfadsfafdsa %}{{ total}}{%endwith%}
四、常用过滤器(filter)
1、add
给变量加上响应的值
{{ value2|add:"2"}}
2、addslashes
给变量中的引号前加上斜线
3、capfirst
首字母大写
4、cut 从字符串中移除指定的字符
{{ valuelcut:""}}If value is "string with spaces", the output willbe "stringwithspaces".
5、date 格式化日期字符串
6、default 如果值是False,就替换成设置的默认值,否则就使用本来的值
7、default_if_none 如果值是None,就替换成设置的默认值,否则就使用本来的值
8、dictsort 按照设定参数(key)对应的value对列表进行排序
9、dictsortreversed 和上面恰好相反
10、divisibleby 是否能够被某个数字整除,是的话返回True,否则返回False
11、escape 对字符串进行转义
12、escapejs 替换value中的某些字符,以适应JAVASCRIPT和JSON格式
13、filesizeformat 格式化文件大小显示
14、first 返回列表中的第一个值
15、last 返回列表中最后一个值
16、floatformat 格式化浮点数
17、length 求字符串或者列表长度
18、length_is 比较字符串或者列表的长度
19、urlencode 对URL进行编码处理
Escapes a value for use in a URL.
For example:
{{ value | urlencode }}
If value is "https://www.example.org/foo?a=bac=d", the output will be
"https%3A//www.example.org/foo%3Fa%3Db%26c%3Dd".
20、upperlower大写小写
21、safe 对某个变量关闭自动转义
22、slice 切片操作
23、time 格式化时间
24、timesince 格式化时间(e.g,"4 days,6 hours").
25、truncatechars 按照字符截取字符串 用于显示不完后面部分。。。
26、truncatewords 按照单词截取字符串 [按空格]
27、striptags 过滤掉html标签
标签和过滤器完整介绍
五、自定义标签、过滤器,引用jinja2模板系统
详见django进阶课程
19、模板包含和继承
包含:
{% include %} 允许在模板中包含其它模板的内容。
标签的参数可以是:模板名称、变量、字符串。
{%include'nav.html"%}
{% include'app/nav.html"%}
{% include template_name %}
还可以在包含的时候传递变量。
from django.template import loader, Template
{% include 'aaa/sub.html' with hello='hello! Djang' %}
继承:
本质上说:模板继承就是先构造一个基础框架模板,而后在其子模板中对它所包含站点共用部分和定义进行重载。
1、{%block%}
定义块
https://docs.djangoproject.com/en/2.1/ref/templates/builtins/#block
2、{%extends%}
继承父模板
https://docs.djangoproject.com/en/2.1/ref/templates/builtins/#extends
注意事项:
1,包含和继承可以把一些共用的网页模块独立出来,以减少代码的冗余。
2,如果在模板里使用(% extends %}的话,这个标签必须在所有模板标签的
最前面,否则模板继承不工作
3,通常尽可能模板里的(% block %}越多越好,子模板不必定义所有的父block
4,如果你需要得到父模板的块内容,{{block.super}变量可以帮你完成工作
当你需要给父块添加内容而不是取代它的时候这就很有用
5,不能在同一模板里定义多个同名的(% block %},因为块标签同时在两个
地方工作,不仅仅在子模板中,而且在父模板中也填充内容,如果子模板有
两个同名的标签,父模板将不能决定使用哪个块内容来使用
20、admin基本配置
django admin是django自带的一个后台app,提供了后台的管理功能。
基础知识点:
一、认识ModelAdmin
管理界面的定制类,如需扩展特定的model界面需要从该类继承
二、注册model类到admin的两种方式:
1、使用register的方法2、使用register的装饰器
三、掌握一些常用的设置技巧
list_display:指定要显示的字段search_fields:指定搜索的字段list_filter:指定列表过滤器ordering:指定排序字段fieldsexclude:指定编辑表单需要编辑不需编辑的字段fieldsets:设置分组表单
更多高级使用的功能,将在《Django进阶》课程里面介绍,另外,值得注意的
是,django admin更适合开发人员来使用,最终用户来使用的话用户体验还
不是很好。
from django.contrib import adminfrom hello.models import*@admin.register(Publisher)class PublisherAdmin(admin.ModelAdmin):1ist_display='name','country','state province','city',)admin.site.register(Author)admin.site.register(AuthorDetail)# admin.site.register(Publisher, PublisherAdmin)admin.site.register(Book)
class FlatPageAdmin(admin. ModelAdmin):
fieldsets=(
(None,{
fields':(' url',' title',' content',' sites')
}),(Advanced options',{
' classes':(' collapse',),fields':(' registration_required",' template_name'),
}),
21、Form
一、什么是Form?什么是Django Form?
django表单系统中,所有的表单类都作为django.forms.Form的子类创建,
包括ModelForm
关于django的表单系统,主要分两种
基于django.forms.Form:所有表单类的父类
基于django.forms.ModelForm:可以和模型类绑定的Form
案例:
实现添加出版社信息的功能。
二、不使用Django Form的情况
前端自己写表单标签
后端接受创建保存
三、使用Form的情况
from django import formsclass PublisherForm(forms.Form): # 标签内容name = forms.CharField(label="名称", error_messages={"required": "这个项必须填写"})
address = forms.CharField(label="地址", error_messages={"required": "这个项必须填写"})
city = forms.CharField(label="城市", error_messages={"required": "这个项必须填写"})
state_province = forms.CharField(label="省份", error_messages={"required": "这个项必须填写"})
country = forms.CharField(label="国家", error_messages={"required": "这个项必须填写"})
website = forms.URLField(label="网址", error_messages={"required": "这个项必须填写"})#view.py 接受校验使用Django Form的情况。
publisher_form = PublisherForm(request.POST)
if publisher_form.is_valid():
Publisher.objects.create(
name = publisher_form.cleaned_data['name'],
address = publisher_form.cleaned_data['address'],
city = publisher_form.cleaned_data['city'],
state_province = publisher_form.cleaned_data['state_province'],
country = publisher_form.cleaned_data['country'],
website = publisher_form.cleaned_data['website'],
)
return HttpResponse("添加出版社信息成功!")
else:
publisher_form = PublisherForm()
return render(request, 'add_publisher.html', locals())
空的内容不合法 不用自己校验数据
四、使用ModelForm的情况
总结:
使用Django中的Form可以大大简化代码,常用的表单功能特性都整全
Form中,而ModelForm可以和Model进行绑定,更进一步简化
class PublisherForm(forms.ModelForm):#view.pypublisher_form = PublisherForm(request.POST)
if publisher_form.is_valid():
publisher_form.save() # 直接保存
return HttpResponse("添加出版社信息成功!")
22、Form的验证
Django提供了3种方式来验证表单。
一、表单字段的验证器
def validate_name(value):
try:
Publisher.objects.get(name=value)
raise ValidationError("%s的信息已经存在"%value)
except Publisher.DoesNotExist:
pass
二、clean_filedname,验证字段,针对某个字段进行验证
def clean_name(self):
value = self.cleaned_data.get('name')
try:
Publisher.objects.get(name=value)
raise ValidationError("%s的信息已经存在" % value)
except Publisher.DoesNotExist:
pass
return value # 没有错误要返回
三、表单clean方法,可针对整个表单进行验证。
案例:
自定义验证,不能插入重名的出版社名称。
clean_filedname 优先
# 三、表单clean方法,可针对整个表单进行验证。
def clean(self):
cleaned_data = super(PublisherForm, self).clean()
value = cleaned_data.get('name')
try:
Publisher.objects.get(name=value)
self._errors['name']=self.error_class(["%s的信息已经存在" % value]) #单独指定错误信息
except Publisher.DoesNotExist:
pass
return cleaned_data