https://segmentfault.com/a/1190000015310299
Seaborn学习大纲
seaborn的学习内容主要包含以下几个部分:
-
风格管理
- 绘图风格设置
- 颜色风格设置
-
绘图方法
- 数据集的分布可视化
分类数据可视化- 线性关系可视化
-
结构网格
- 数据识别网格绘图
本次将主要介绍 分类数据可视化的使用。
分类数据可视化
数据集中的数据类型有很多种,除了连续的特征变量之外,最常见的就是类目型的数据类型了,常见的比如人的性别,学历,爱好等。这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示。
seaborn针对分类型的数据有专门的可视化函数,这些函数可大致分为三种:
- 分类数据散点图: swarmplot(), stripplot()
- 分类数据的分布图: boxplot(), violinplot()
- 分类数据的统计估算图 : barplot(), pointplot()
这三类函数可有特点,可以从各个方面展示分类数据的可视化效果,下面我们一一介绍。
首先的首先还是先导入需要的模块和数据集。
1 %matplotlib inline 2 import numpy as np 3 import pandas as pd 4 import matplotlib as mpl 5 import matplotlib.pyplot as plt 6 import seaborn as sns 7 sns.set(style="whitegrid", color_codes=True) 8 np.random.seed(sum(map(ord, "categorical"))) 9 titanic = sns.load_dataset("titanic") 10 tips = sns.load_dataset("tips") 11 iris = sns.load_dataset("iris")
1、分类数据散点图
在分类数据的基础上展示定量数据的最简单函数就是 stripplot()
1 sns.stripplot(x="day", y="total_bill", data=tips);
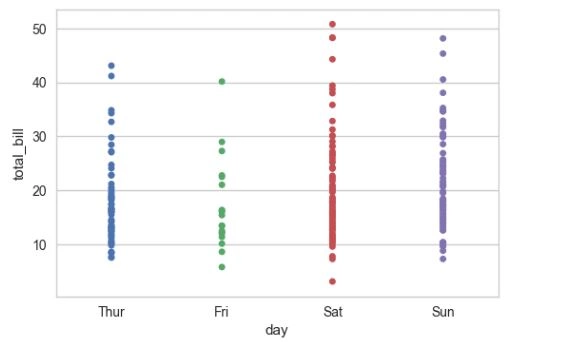
这看上去类似散点图,但不同的是,横坐标是分类的数据,只不过一些数据点上会互相重叠,不便于观察。所以一个简单的解决办法是加入jitter参数,调整横坐标位置。
sns.swarmplot(x="day", y="total_bill", data=tips,jitter=True);

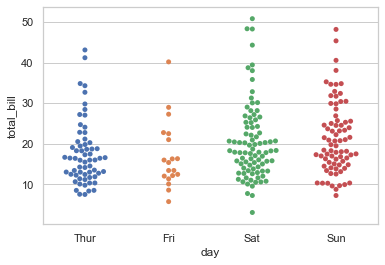
当然,还有一个不同的方法就是使用 swarmplot() 函数,这个函数的好处就是所有的点都不会重叠,这样可以很清晰的观察到数据的分布。
1 sns.swarmplot(x="day", y="total_bill", data=tips);
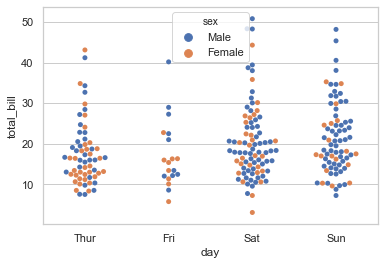
在这基础上,也可以通过 hue 参数加入另一个嵌套的分类变量,而且嵌套的分类变量可以以不同的颜色区别,十分方便。
1 sns.swarmplot(x="day", y="total_bill", hue="sex", data=tips);
通常情况下,seaborn 还会尝试推断出分类变量的顺序。如果你的数据是 pandas 的分类数据类型,那么就是使用默认的分类数据顺序,如果是其他的数据类型,字符串类型的类别将按照它们在DataFrame中显示的顺序进行绘制,但是数组类别将被排序。
1 sns.swarmplot(x="size", y="total_bill", data=tips);

有时候将分类变量放在垂直轴上是非常有用的(当类别名称相对较长或有很多类别时,这一点特别有用)。 可以使用 orient 关键字强制定向,但通常可以互换x和y的变量的数据类型来完成:
1 sns.swarmplot(x="total_bill", y="day", hue="time", data=tips);
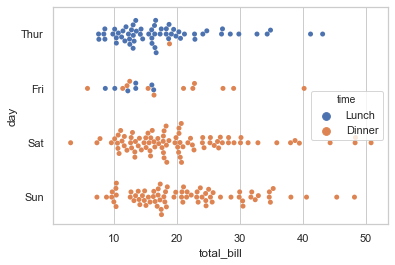
虽然分类的散点图很有用,但有时候想要快速查看各分类下的数据分布就不是很直观了。为此,第二种函数解决了这个问题。
2、箱型图
通过箱型图可以很直观的观察到数据的四分位分布(1/4分位,中位数,3/4分位,以及四分位距),这种可视化对于在机器学习的预处理阶段(尤其是发现数据异常离散值)十分有效。
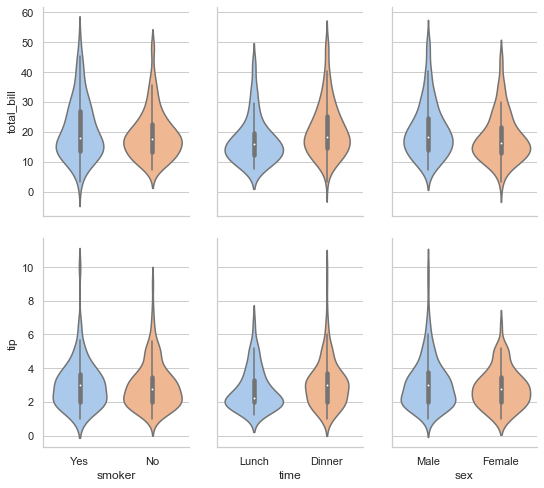
1 sns.boxplot(x="day", y="total_bill", hue="time", data=tips);

对于箱型图来说,使用 hue 参数的假设是这个变量嵌套在x或者y轴内。所以默认的情况下,hue 变量的不同类型值会保持偏置状态(两类或几类数据共同在x轴数据类型的一个类中),就像上面那个图所示。但是如果 hue 所使用的变量不是嵌套的,那么你可以使用 dodge 参数来禁止这个默认的偏置状态。
1 tips["weekend"] = tips["day"].isin(["Sat", "Sun"]) 2 sns.boxplot(x="day", y="total_bill", hue="weekend", data=tips, dodge=False);

3、提琴图
另一种不同的方法是 violinplot() 函数,它结合了箱体图和分布教程中描述的核心密度估计过程:
1 sns.violinplot(x="total_bill", y="day", hue="time", data=tips);
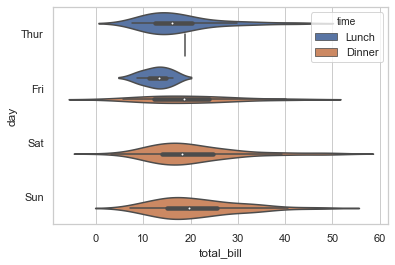
这种方法使用核密度估计来更好地描述值的分布。此外,小提琴内还显示了箱体四分位数和四分位距。由于小提琴使用KDE,还有一些其他可以调整的参数,相对于简单的boxplot增加了一些复杂性:
1 sns.violinplot(x="total_bill", y="day", hue="time", data=tips, 2 bw=.1, scale="count", scale_hue=False);

当 hue 的嵌套类型只有两类的时候,也可以使用split 参数将小提琴分割:
1 sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, split=True);
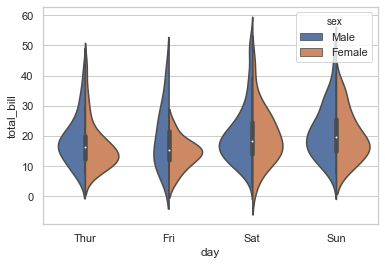
在提琴图内,也可以使用 inner 参数以横线的形式来展示每个观察点的分布,来代替箱型的整体分布:
1 sns.violinplot(x="day", y="total_bill", hue="sex", data=tips, 2 split=True, inner="stick", palette="Set3");
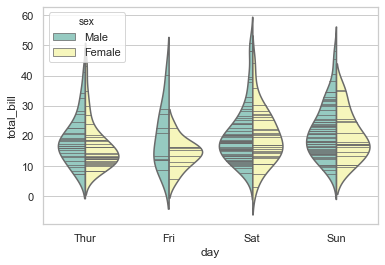
还有一点比较好的是,可以将 swarmplot(),violinplot(),或 boxplot() 混合使用,这样可以结合多种绘图的特点展示更完美的效果。
1 sns.violinplot(x="day", y="total_bill", data=tips, inner=None) 2 sns.swarmplot(x="day", y="total_bill", data=tips, color="w", alpha=.5);
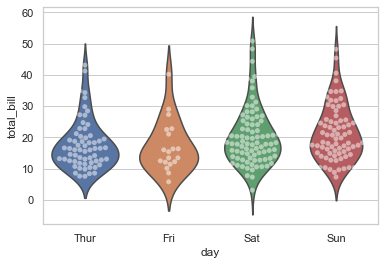
有时候,我们不想展示分类数据下的分布,而是想展示每一类的集中趋势。seaborn 有两个主要的方法来展示这个,并且这些函数api与上面函数的用法是一样的。
3、 条形图
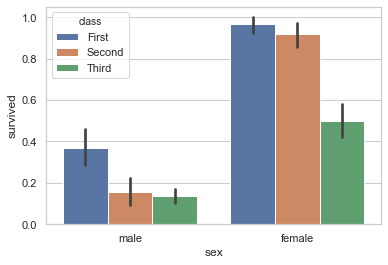
我们最熟悉的方式就是使用一个条形图。 在Seaborn中barplot()函数会在整个数据集上显示估计,默认情况下使用均值进行估计。 当在每个类别中有多个类别时(使用了 hue),它可以使用引导来计算估计的置信区间,并使用误差条来表示置信区间:
1 sns.barplot(x="sex", y="survived", hue="class", data=titanic);
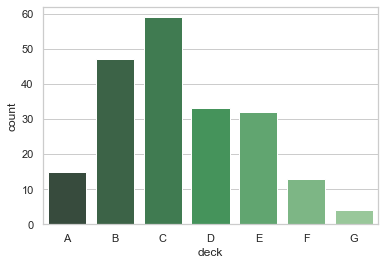
条形图的特殊情况是当您想要显示每个类别的数量,而不是计算统计量。这有点类似于一个分类而不是定量变量的直方图。在Seaborn中,使用countplot()函数很轻易的完成:
1 sns.countplot(x="deck", data=titanic, palette="Greens_d");
如果将要计数的变量移动到y轴上,那么条形就会横过来显示:
1 sns.countplot(y="deck", hue="class", data=titanic, palette="Greens_d");

4、点图
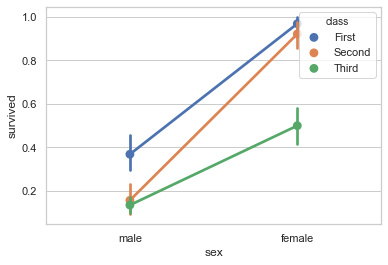
pointplot()函数提供了估计可视化的另一种风格。该函数会用高度估计值对数据进行描述,而不是显示一个完整的条形,它只绘制点估计和置信区间。另外,点图连接相同hue类别的点,比如male中的蓝色会连接female中的蓝色。这使得很容易看出主要关系如何随着第二个变量的变化而变化,因为你的眼睛可以很好地辨别斜率的差异:
1 sns.pointplot(x="sex", y="survived", hue="class", data=titanic);
为了使能够更好的显示,可以使用不同的标记和线条样式来展示不同hue类别的层次:
1 sns.pointplot(x="class", y="survived", hue="sex", data=titanic, 2 palette={"male": "g", "female": "m"}, 3 markers=["^", "o"], linestyles=["-", "--"]);
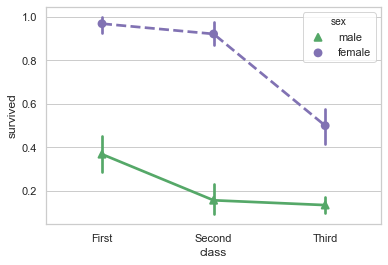
5、绘制“宽格式”数据
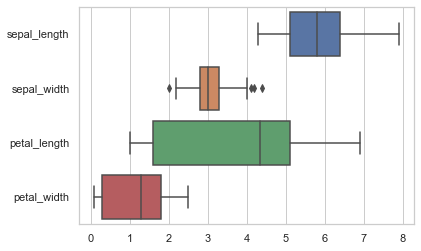
虽然使用“长格式”或“整洁”数据是优选的,但是这些函数也可以应用于各种格式的“宽格式”数据,包括pandas DataFrame或二维numpy数组阵列。这些对象应该直接传递给数据参数:
1 sns.boxplot(data=iris, orient="h");
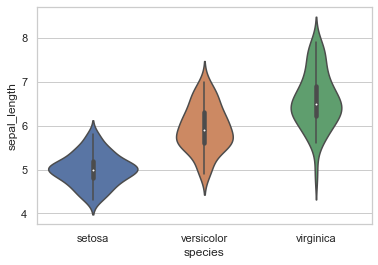
此外,这些函数也接受Pandas或numpy对象的向量,而不仅仅是DataFrame中的变量:
1 sns.violinplot(x=iris.species, y=iris.sepal_length);
为了控制由上述函数制作的图形的大小和形状,你必须使用matplotlib命令自己设置图形。 当然,这也意味着这些图块可以和其他种类的图块一起在一个多面板的绘制中共存:
1 f, ax = plt.subplots(figsize=(7, 3)) 2 sns.countplot(y="deck", data=titanic, color="c");
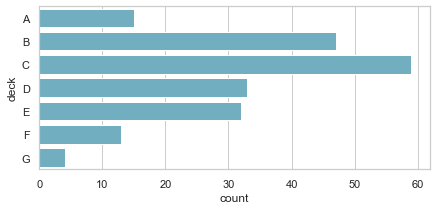
6、绘制多层面板分类图
正如我们上面提到的,有两种方法可以在Seaborn中绘制分类图。与回归图中的二元性相似,您可以使用上面介绍的函数,也可以使用更高级别的函数factorplot(),将这些函数与FacetGrid()相结合,通过这个图形的更大的结构来增加展示其他类别的能力。 默认情况下,factorplot()产生一个pairplot():
1 sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips);
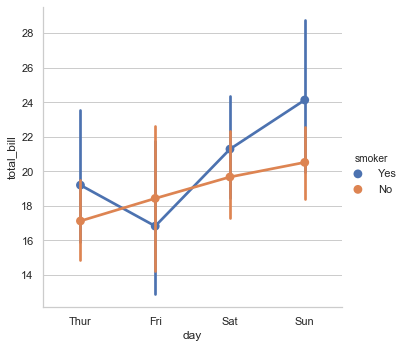
但是,kind参数可以让你选择以上讨论的任何种类的图:
sns.factorplot(x="day", y="total_bill", hue="smoker", data=tips, kind="bar");
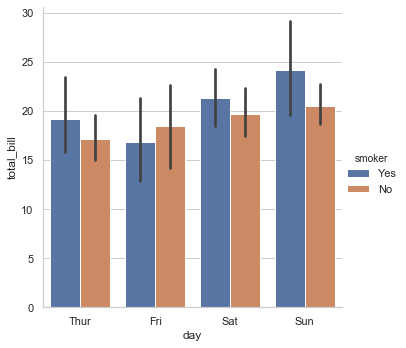
使用factorplot()的主要优点是可以很容易使用"facet"绘制多面图,展示更多其他分类变量:
1 sns.factorplot(x="day", y="total_bill", hue="smoker", 2 col="time", data=tips, kind="swarm");

任何一种图形都可以画出来。由于FacetGrid的工作原理,要更改图形的大小和形状,需要指定适用于每个图的size和aspect参数:
sns.factorplot(x="time", y="total_bill", hue="smoker", col="day", data=tips, kind="box", size=4, aspect=.5);
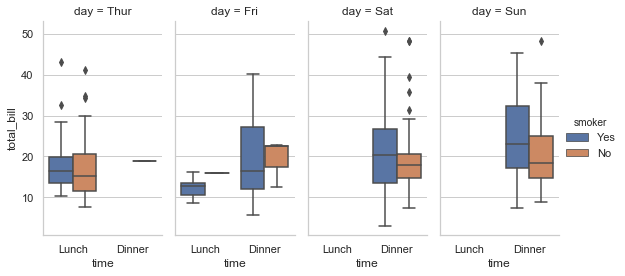
你也可以直接使用boxplot()和FacetGrid来制作这个图。但是,必须特别注意确保每个图的分类变量的顺序需要被强制,或者是使用具有Categorical数据类型的数据或通过命令和hue_order。
1 sns.factorplot(x="time", y="total_bill", hue="smoker",hue_order=["No","Yes"] 2 ,col="day", data=tips, kind="box", size=4, aspect=.5, 3 palette="Set3");

由于广义API函数的存在,分类数据也可以很容易应用于其他更复杂的上下文。 例如,它们可以轻松地与PairGrid结合,以显示多个不同变量之间的分类关系:
g = sns.PairGrid(tips, x_vars=["smoker", "time", "sex"], y_vars=["total_bill", "tip"], aspect=.75, size=3.5) g.map(sns.violinplot, palette="pastel");