Lab3 以后内存出现的问题
对于GCC 7.0 以上的版本在Lab3以后, 会出现 kernel panic at kern/pmap.c:147: PADDR called with invalid kva 00000000 这个错误, 我本身也很疑惑, 明明在 Lab2 代码是正确的, 这里为什么是错的呢?
从错误的结果来看是
boot_alloc memory at f018e000, next memory allocate at f018f000
kernel panic at kern/pmap.c:154: PADDR called with invalid kva 00000000
错误的部分是在 boot_alloc 函数中.
static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
if (!nextfree) {
extern char end[];
// 将地址 end 向上以页面大小对齐
nextfree = ROUNDUP((char *) end, PGSIZE);
}
result = nextfree;
nextfree = ROUNDUP((char *) result+n, PGSIZE);
cprintf("boot_alloc memory at %x, next memory allocate at %x
", result, nextfree);
return result;
}
然后我发现,在
// 分配一个物理页大小的虚拟空间, 对于页目录来说, 这里使用 boot_alloc
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
// 初始化页目录
memset(kern_pgdir, 0, PGSIZE);
删除 memset 之后, 可以得到部分正确, 而且在 memset 之前, kern_pgdir 都是 f018e000, 那么这一步到底发生了什么呢? 其实错误的真正原因不在这里, 而是在 end 这里, 我们知道, end是内核段的末尾, 也就是 bss 段的末尾, 根据 objdump -h obj/kern/kernel 可知 bss 段在内存的位置:
Idx Name Size VMA LMA File off Algn
9 .bss 00000f14 f018d100 0018d100 0008e100 2**5
CONTENTS, ALLOC, LOAD, DATA
bss 段的起始位置是 f018d100 , 大小为 00000f14, 所以虚拟内存范围是 0xf018d100 到 0xf018e014 , 从result 返回的数据可以知道,end 的地址为 f018e000, 在bss 的范围内, 然后我们使用 objdump -t obj/kern/kernel | grep kern_pgdir 查看一下 kern_pgdir 的情况可以得到:
f018e00c g O .bss 00000004 kern_pgdir
kern_pgdir 存储的地址 f018e00c 恰好就在 end 后面, 这会导致什么呢? 我们要知道 0xf018e000 恰好是 PAGESIZE 对齐的.所以会发生下面的问题:
// kern_pgdir == NULL, &kern_pgdir == 0xf018f00c
// in mem_init()
kern_pgdir = (pde_t *) boot_alloc(PGSIZE); // call boot_alloc(4096)
// in boot_alloc()
if (!nextfree) {
extern char end[]; // end == 0xf018e000
nextfree = ROUNDUP((char *) end, PGSIZE); // nextfree = 0xf018e000
}
// ...
// 0xf018f000 is returned to to mem_init()
kern_pgdir = (pde_t *) boot_alloc(PGSIZE); // kern_pgdir = 0xf018e000, 这里是返回的 result 的数据
// 注意这一步, 恰好把 kern_pgdir清空了
memset(kern_pgdir, 0, PGSIZE); // Damn! 0xf018e000 to 0xf0180000 are set to 0, including 0xf018e00c
// Now kern_pgdir == 0
kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P; // call PADDR(0), panic!
为什么 end 会设置错误呢? 我们可以看下 kern/kernel.ld , 这个文件是内核的各个段的描述, 解决方法就是添加了 *(COMMON) 段, 至于为什么了, 个人还是不太清楚,
.bss : {
PROVIDE(edata = .);
*(.bss)
*(COMMON)
PROVIDE(end = .);
BYTE(0)
}
JOS 的一个进程可以看作是一个线程与地址空间的结合, 因为运行一个进程需要将 CPU 建立在保存的寄存器与用户空间之上.
Lab3 的 GNUmakefile 会产生大量的二进制文件在 /obj/user/ 目录下, kern/Makefrag 会将链接 /obj/user/ 文件下面的 .o 文件得到一个可执行文件. 这是一种得到可执行文件的方式, 是将可执行文件嵌入到内核中去.
Creating and Running Environments
这里的 env 表示的是进程, 因为进程的本质就是 CPU + 运行环境, 用 env 表示进程完全没有问题, 这里需要注意的问题是启动的过程是下面这个树形结构,
start (kern/entry.S)
i386_init (kern/init.c)
cons_init(控制台初始化)
mem_init(内存初始化)
env_init(进程初始化)
trap_init (still incomplete at this point)
env_create(创建进程)
env_run
env_pop_tf
struct Env *envs = NULL; // All environments
struct Env *curenv = NULL; // The current env
// 这里空闲链表的形式是, env_free_list 指向空闲的 envs[i] 结构体,
// 然后使用 env_link 连接起来
static struct Env *env_free_list; // Free environment list
// (linked by Env->env_link)
// 构建全局描述表, SEG 函数是构建一个段,
struct Segdesc gdt[] =
{
// 0x0 - unused (always faults -- for trapping NULL far pointers)
SEG_NULL,
// 0x8 - kernel code segment
// SEG 的参数分别表示 权限, 基地址, 大小限制, 优先级
[GD_KT >> 3] = SEG(STA_X | STA_R, 0x0, 0xffffffff, 0),
// 0x10 - kernel data segment
[GD_KD >> 3] = SEG(STA_W, 0x0, 0xffffffff, 0),
// 0x18 - user code segment
[GD_UT >> 3] = SEG(STA_X | STA_R, 0x0, 0xffffffff, 3),
// 0x20 - user data segment
[GD_UD >> 3] = SEG(STA_W, 0x0, 0xffffffff, 3),
// 0x28 - tss, initialized in trap_init_percpu()
[GD_TSS0 >> 3] = SEG_NULL
};
void env_init(void)
{
// Set up envs array
// LAB 3: Your code here.
// 初始化的时候, env_free_list 指向第一个 envs 结构体
env_free_list = &envs[0];
int i = 0;
for(i = 0; i<NENV-1; i++) {
envs[i].env_link = &envs[i+1];
}
envs[NENV-1].env_link = NULL;
// Per-CPU part of the initialization
env_init_percpu();
}
然后全局描述表与段描述符, 这里需要回顾一下 /inc/mmu.h 中的内容, 也就是对于目标的可执行文件而言, ELF 的构成以及各个段的结构, 这里我推荐下面这篇博客, 讲的很清楚, 传送门 .
void env_init_percpu(void)
{
lgdt(&gdt_pd);
// 将 GDT 的入口地址存入 gdtr寄存器
// The kernel never uses GS or FS, so we leave those set to
// the user data segment.
asm volatile("movw %%ax,%%gs" : : "a" (GD_UD|3));
asm volatile("movw %%ax,%%fs" : : "a" (GD_UD|3));
// The kernel does use ES, DS, and SS. We'll change between
// the kernel and user data segments as needed.
asm volatile("movw %%ax,%%es" : : "a" (GD_KD));
asm volatile("movw %%ax,%%ds" : : "a" (GD_KD));
asm volatile("movw %%ax,%%ss" : : "a" (GD_KD));
// Load the kernel text segment into CS.
// 在 x86中使用的是 IP 与 CS 寄存器实现指令寻址
asm volatile("ljmp %0,$1f
1:
" : : "i" (GD_KT));
// For good measure, clear the local descriptor table (LDT),
// since we don't use it.
// lldt 导入 0, 表示不使用 LDT
lldt(0);
}
static int
env_setup_vm(struct Env *e)
{
int i;
struct PageInfo *p = NULL;
// Allocate a page for the page directory
if (!(p = page_alloc(ALLOC_ZERO)))
return -E_NO_MEM;
// 通过返回的物理页得到虚拟地址
e->env_pgdir = (pde_t*)page2kva(p);
// 这一部分相当于初始化进程的虚拟空间, 对于所有进程而言, UTOP上面的部分是内核空间, 对所有用户来说是一样的
memcpy(e->env_pgdir, kern_pgdir, PGSIZE);
p->pp_ref += 1;
// LAB 3: Your code here.
// UVPT maps the env's own page table read-only.
// Permissions: kernel R, user R
// 这里和设置内核页表的方法是一样的, 设置 UVPT为页目录, 在物理内存中分配页目录,
e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U;
return 0;
}
int env_alloc(struct Env **newenv_store, envid_t parent_id)
{
int32_t generation;
int r;
struct Env *e;
// 如果 env_free_list 指向 NULL, 表示进程数目满了
if (!(e = env_free_list))
return -E_NO_FREE_ENV;
// 初始化一个用户进程虚拟空间, 也就是分配页目录
// Allocate and set up the page directory for this environment.
if ((r = env_setup_vm(e)) < 0)
return r;
// Generate an env_id for this environment.
generation = (e->env_id + (1 << ENVGENSHIFT)) & ~(NENV - 1);
if (generation <= 0) // Don't create a negative env_id.
generation = 1 << ENVGENSHIFT;
e->env_id = generation | (e - envs);
// Set the basic status variables. 设置新进程的一些状态变量
e->env_parent_id = parent_id;
e->env_type = ENV_TYPE_USER;
e->env_status = ENV_RUNNABLE;
e->env_runs = 0;
// 清空进程寄存器部分
memset(&e->env_tf, 0, sizeof(e->env_tf));
// 手动构建出段寄存器的内容, 这里没有使用 LDT表, 这里的内容使用的是段描述符, 也就是描述不同的段,
// 是对于一个用户程序而言的
e->env_tf.tf_ds = GD_UD | 3;
e->env_tf.tf_es = GD_UD | 3;
e->env_tf.tf_ss = GD_UD | 3;
e->env_tf.tf_esp = USTACKTOP;
e->env_tf.tf_cs = GD_UT | 3;
// You will set e->env_tf.tf_eip later.
// 将 env_free_list 向后移动
// commit the allocation
env_free_list = e->env_link;
*newenv_store = e;
cprintf("[%08x] new env %08x
", curenv ? curenv->env_id : 0, e->env_id);
return 0;
}
// 对于输入虚拟地址, 在物理内存上分配 len 字节的内存, 使用 page_alloc, 可以得到返回的物理页描述符
// 同时将分配的物理页使用 page_insert 使之与虚拟地址对应我来
static void
region_alloc(struct Env *e, void *va, size_t len)
{
// LAB 3: Your code here.
// (But only if you need it for load_icode.)
struct PageInfo *temp;
// 这里必须是向下对齐, 向上的话会导致 va 起始地址空白
uintptr_t start = ROUNDDOWN((uintptr_t)va, PGSIZE);
uintptr_t end = ROUNDUP((uintptr_t)va+len, PGSIZE);
// 得到需要分配多少个页面, 而分配页面的方法就是, 先分配物理页, 然后将物理页与虚拟地址进行对应
size_t num = (end - start) >> PGSHIFT;
size_t i = 0;
for(i = 0; i< num; i++) {
if ((temp = page_alloc(0)) == NULL) {
panic("region_alloc: %e", -E_NO_MEM);
}
int r = page_insert(e->env_pgdir, temp, (void*)(start + i * PGSIZE), PTE_W | PTE_U);
if (r < 0) {
panic("region_alloc: %e", r);
}
}
}
// obj/kern/kernel.sym中类似_binary_obj_user_hello_start,_binary_obj_user_hello_end,_binary_obj_user_hello_size
// 这种符号就是用户程序的起始线性地址,终止线性地址, 在内核启动一个用户进程的过程中的调用顺序就是:
// 在 init.c 里面的 ENV_CREATE(user_hello, ENV_TYPE_USER); -->> env_create(_binary_obj_user_hello_start, ENV_TYPE_USER)
// -->> env_create(uint8_t *binary, enum EnvType type) -->> load_icode(new_env, binary);
// 所以 uint8_t *binary:就是可执行用户代码的起始地址
static void load_icode(struct Env *e, uint8_t *binary)
{
// LAB 3: Your code here.
// ELF 头部的地址
struct Elf* elf = (struct Elf*)binary;
// 段表的开头与结尾
struct Proghdr *ph, *eph;
ph = (struct Proghdr*)(elf->e_phoff + binary);
// Segment 表的尾部, 也就是 end_of_Proghdr;
eph = ph + elf->e_phnum;
// 判断 ELF 文件的魔数是否正确
if (elf->e_magic != ELF_MAGIC) {
panic("load_icode: not an ELF file");
}
// 将 e->env_pgdir 的物理地址存入 cr3 寄存器, 表明当前正在运行的进程
lcr3(PADDR(e->env_pgdir));
// 对于 ELF 中每一个 Segment
while(ph < eph) {
// ph 是最终的可执行文件段表
if(ph->p_type == ELF_PROG_LOAD) {
if(ph->p_filesz > ph->p_memsz) {
panic("load_icode: p_filesz > p_memsz");
}
// 将程序段加载进物理内存, 同理会在物理内存上分配这一块段大小的空间, p_memsz 表示允许段的最大大小
region_alloc(e, (void*)(ph->p_va), ph->p_memsz);
// 这一步相当于对物理空间的初始化, 初始化了整个程序的各个段在物理内存中的内容
memcpy((void*)(ph->p_va), (void*)(binary + ph->p_offset), ph->p_filesz);
memset((void*)(ph->p_va + ph->p_filesz), 0 , ph->p_memsz - ph->p_filesz);
}
ph++;
}
e->env_tf.tf_eip = elf->e_entry;
// Now map one page for the program's initial stack
// at virtual address USTACKTOP - PGSIZE.
// LAB 3: Your code here.
region_alloc(e, (void*)(USTACKTOP - PGSIZE), PGSIZE);
lcr3(PADDR(kern_pgdir));
}
void env_create(uint8_t *binary, enum EnvType type)
{
// LAB 3: Your code here.
// 创建一个新的进程
struct Env *new_env = NULL;
// 分配一个进程, 同时分配了进程必须的部分, 页目录, 设置了进程的状态等
int result = env_alloc(&new_env, 0);
if(result < 0) {
panic("env_create: %e", result);
}
new_env->env_type = type;
// 在物理内存中构建出程序环境
load_icode(new_env, binary);
}
void env_free(struct Env *e)
{
pte_t *pt;
uint32_t pdeno, pteno;
physaddr_t pa;
// If freeing the current environment, switch to kern_pgdir
// before freeing the page directory, just in case the page
// gets reused.
if (e == curenv)
lcr3(PADDR(kern_pgdir));
// Note the environment's demise.
cprintf("[%08x] free env %08x
", curenv ? curenv->env_id : 0, e->env_id);
// Flush all mapped pages in the user portion of the address space
static_assert(UTOP % PTSIZE == 0);
// 将每一个页表对应的空间清空, 但是也不是全部, 而是在 UTOP下面的部分, 所以页表自身要手动清空
for (pdeno = 0; pdeno < PDX(UTOP); pdeno++) {
// only look at mapped page tables, 只删除 mapped 虚拟地址与物理地址的页表项
if (!(e->env_pgdir[pdeno] & PTE_P))
continue;
// find the pa and va of the page table
// e->env_pgdir[pdeno] 是页目录项的内容,所以这里是页表的物理地址
pa = PTE_ADDR(e->env_pgdir[pdeno]);
pt = (pte_t*) KADDR(pa);
// unmap all PTEs in this page table
// 将页表中的每一页删除 mapped, 也就是从物理地址中删除,
for (pteno = 0; pteno <= PTX(~0); pteno++) {
if (pt[pteno] & PTE_P)
// 将虚拟地址与物理页的对应关系在页表中删除
// PGADDR 可以按顺序构建出虚拟地址
page_remove(e->env_pgdir, PGADDR(pdeno, pteno, 0));
}
// free the page table itself, 页目录中, 该页表项的内容为空
e->env_pgdir[pdeno] = 0;
page_decref(pa2page(pa));
}
// free the page directory
pa = PADDR(e->env_pgdir);
e->env_pgdir = 0;
page_decref(pa2page(pa));
// return the environment to the free list, 进程状态改变
e->env_status = ENV_FREE;
e->env_link = env_free_list;
env_free_list = e;
}
void env_run(struct Env *e)
{
// LAB 3: Your code here.
if(curenv && curenv->env_status == ENV_RUNNING) {
curenv->env_status = ENV_RUNNABLE;
}
curenv = e;
e->env_status = ENV_RUNNING;
e->env_runs++;
// 需要注意的是, 这里 e->env_pgdir 是在KERNBASE 上面的, 是 boot alloc 分配的
lcr3(PADDR(e->env_pgdir));
env_pop_tf(&(e->env_tf));
}
JOS 处理中断与异常
Basics of Protected Control Transfer
中断与异常都需要 CPU 从用户态进入内核态, 其本质是将 CPU 的控制权交给内核, 操作系统需要保证这个交接过程的正确执行. 中断通常是由外部程序异步造成的, 而异常是由一些内部程序造成的. 对于正在运行的进程遇到中断或者异常的时候, 操作系统中处理中断与异常的机制需要谨慎的控制内核进程.这里面有两个机制:
The Interrupt Descriptor Table.
中断描述符表: 中断与异常导致陷入内核的时候, 陷入内核的地址必须是内核事先指明的一些特定地址, 对于 x86 来说, 支持 256 种基于不同情况的中断与异常, 对于这 256 种来说, 可以使用 8 位bit 的向量来唯一表示, 所以就构成了中断(描述符)向量表, 使用这个向量作为中断(描述符)向量表的索引, 对于中断向量表entry的内容:
- EIP 寄存器的内容, 指向内核处理该异常的代码段
- CS 寄存器的内容, 该值的 01 两位表示运行异常处理程序的特权级别, 在 JOS 中,异常程序都是内核态,优先级也就是 0
The Task State Segment
现在, 在发生中断或者异常进入内核的时候, 需要保存现场, 对于保存的位置需要先指明, 这个位置是在内核栈中, Task State Segment(TSS) 的作用就是确定这个内核栈的段选择器以及地址, 保存用户程序信息的方式就是, 对这个特殊的栈顶, KSTACKTOP, 进行下面的压栈操作,
+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20 <---- ESP
| error code | " - 24 <---- ESP (可选)
+--------------------+
那么我们如何通过 TSS 获得这个内核栈的地址呢? TSS 使用的是 SS0(Stack Segment 0), 与 ESP0 确定的, 其中的 0 表示内核的优先级. 在 JOS中,这两个字段的值分别是 GD_KD 和 KSTACKTOP, 所以中断发生后, SS 与 ESP两个寄存器的值分别为: GD_KD 和 KSTACKTOP. 这两个位置是操作系统决定的, 在由于中断进入内核后, 会将 GD_KD 和 KSTACKTOP 写入 SS 与 ESP, 而在 KSTACKTOP 下面存储的是用户模型下的 SS 寄存器与 ESP 寄存器. 所以说, 如果中断发生在内核态, 就不需要存储 SS 寄存器与 ESP 寄存器的值了. 其实, 处理中断与异常的本质有点类似与在栈上调用函数, 只是保存寄存器的位置是特定声明的位置, 内核栈中的特定位置.
Setting Up the IDT
这一部分我们先来构建出处理中断向量为 0-31 部分的中断向量表, 对于系统调用以及后面的中断与异常的处理在后面的 Lab, 我们先来看一下相关的文件, 在 /inc/trap.h 文件中定义了处理中断与异常的一些信息, 主要有中断的类型, 以及需要保存的寄存器, 在 /kern/trap.h 中主要注意的定义是:
// Gate descriptors for interrupts and traps, 中断描述符, 描述一个中断与陷入内核
struct Gatedesc {
unsigned gd_off_15_0 : 16; // low 16 bits of offset in segment
unsigned gd_sel : 16; // segment selector,
unsigned gd_args : 5; // # args, 0 for interrupt/trap gates, 参数的个数
unsigned gd_rsv1 : 3; // reserved(should be zero I guess)
unsigned gd_type : 4; // type(STS_{TG,IG32,TG32}), 描述符的类型, 是哪种, 有中断门, 陷阱门, 与任务门
unsigned gd_s : 1; // must be 0 (system)
unsigned gd_dpl : 2; // descriptor(meaning new) privilege level
unsigned gd_p : 1; // Present
unsigned gd_off_31_16 : 16; // high bits of offset in segment,
};
// Pseudo-descriptors used for LGDT, LLDT and LIDT instructions.
struct Pseudodesc {
uint16_t pd_lim; // Limit
uint32_t pd_base; // Base address
} __attribute__ ((packed));
/* The kernel's interrupt descriptor table */
extern struct Gatedesc idt[]; // 中断描述符数组
extern struct Pseudodesc idt_pd; // 用于
具体的结构, 在这篇博客有详细的图解释: 传送门
我们最需要关注的是, 处理中断与异常的寄存器, 首先是 CS 与 EIP 寄存器, 这两个寄存器来自中断向量表的中断描述符, 表示中断处理程序的地址, 这个地址就是 trapentry.S 中 handler 的地址 将这个地址保存在 IDT 中, 是 trap.init() 的结果, 然后在 handler 中, 首先在 内核栈中建立一个 Trapframe 结构体, 这个结构体是被中断进程寄存器的结构体, 然后才真正进入内核, 调用 trap() 函数, 这个函数的参数就是 Trapframe 结构体的指针(指明了中断前的 env), 然后处理这个中断或者异常. 这个过程可以用下图表示:
IDT trapentry.S trap.c
+----------------+
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
| | // do stuff {
| | call trap // handle the exception/interrupt
| | // ... }
+----------------+
| &handler2 |--------> handler2:
| | // do stuff
| | call trap
| | // ...
+----------------+
.
.
.
+----------------+
| &handlerX |--------> handlerX:
| | // do stuff
| | call trap
| | // ...
+----------------+
所以 trapentry.S 的作用是, 在栈中建立一个 Trapframe 结构体, 然后调用 trap() 函数. 需要注意的是, 这个Trapframe结构体不同于保存的被中断进程的信息.而是我们通过信息来构建一个进程运行状态, 构建 Trapframe 的原因是, 中断处理进程只能通过 Trapframe 初始化,这里构建 Trapframe 的最后一步就是将 error number 压入栈中, 所以在 trapentry.S 中构建 Trapframe 结构的过程是手动的, 不是使用结构体的方式, 而是采用手动压栈的方式, 除了这里的 error number 信息,其他信息可以通过中断向量表直接获得.
// 这里是定义了一个全局函数, 用来将陷入内核的编号压入栈中, 在函数内还定义了一个 name, 表示 trap 执行程序的名字,
// 这个函数就构造出来一个 handler, 函数末尾跳转到 _alltraps,
#define TRAPHANDLER(name, num)
.globl name; /* define global symbol for 'name' */
.type name, @function; /* symbol type is function */
.align 2; /* align function definition */
name: /* function starts here */
pushl $(num);
jmp _alltraps
// 这一步就是将中断处理函数名与错误代码入栈
TRAPHANDLER_NOEC(th_divide, T_DIVIDE)
TRAPHANDLER_NOEC(th_debug, T_DEBUG)
TRAPHANDLER_NOEC(th_nmi, T_NMI)
TRAPHANDLER_NOEC(th_brkpt, T_BRKPT)
TRAPHANDLER_NOEC(th_oflow, T_OFLOW)
TRAPHANDLER_NOEC(th_bound, T_BOUND)
TRAPHANDLER_NOEC(th_illop, T_ILLOP)
TRAPHANDLER_NOEC(th_device, T_DEVICE)
TRAPHANDLER_NOEC(th_syscall, T_SYSCALL)
TRAPHANDLER(th_dblflt, T_DBLFLT)
TRAPHANDLER(th_tss, T_TSS)
TRAPHANDLER(th_segnp, T_SEGNP)
TRAPHANDLER(th_stack, T_STACK)
TRAPHANDLER(th_gpflt, T_GPFLT)
TRAPHANDLER(th_pgflt, T_PGFLT)
TRAPHANDLER_NOEC(th_fperr, T_FPERR)
TRAPHANDLER(th_align, T_ALIGN)
TRAPHANDLER_NOEC(th_mchk, T_MCHK)
TRAPHANDLER_NOEC(th_simderr, T_SIMDERR)
// 这里 Alltraps 的意思, 是对于所有的 trap 都需要进行的操作,
.global _alltraps
_alltraps:
pushl %ds
pushl %es
pushal
movw $GD_KD, %ax
movw %ax, %ds
movw %ax, %es
pushl %esp
call trap
在初始化IDT 的时候, 是使用 trap_init() 来实现的, 实现的方式是, 构造函数, 这个函数也就是 TRAPHANDLER 中的函数名, 表示执行函数的名称, 在构造的 trap gate就是下图所示的结构:
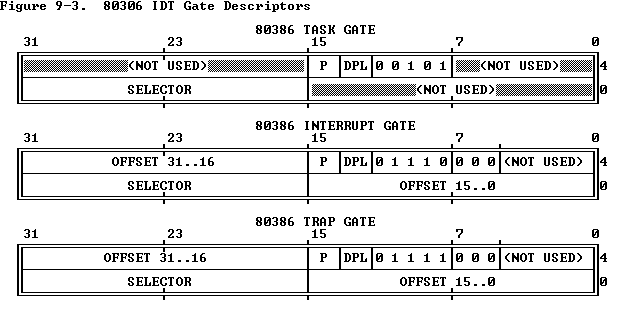
void trap_init(void)
{
extern struct Segdesc gdt[];
// 这里是函数的声明
void th_divide();
void th_debug();
void th_nmi();
void th_brkpt();
void th_oflow();
void th_bound();
void th_illop();
void th_device();
void th_dblflt();
void th_tss();
void th_segnp();
void th_stack();
void th_gpflt();
void th_pgflt();
void th_fperr();
void th_align();
void th_mchk();
void th_simderr();
/*
建立了一个正常的,中断或者trap的门, istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate.
sel: 中断处理程序的代码段, 也就是 SST中的 SS0, 段的基地址, 所以这里都是 GD_KT
off: 中断处理程序代码段的偏移, 这里的偏移
dpl: 中断描述符的优先级, 不过基本上所有的中断都是在内核态下进行的, 这个结构符合上面图中所示的结构
#define SETGATE(gate, istrap, sel, off, dpl)
{
(gate).gd_off_15_0 = (uint32_t) (off) & 0xffff;
(gate).gd_sel = (sel);
(gate).gd_args = 0;
(gate).gd_rsv1 = 0;
(gate).gd_type = (istrap) ? STS_TG32 : STS_IG32;
(gate).gd_s = 0;
(gate).gd_dpl = (dpl);
(gate).gd_p = 1;
(gate).gd_off_31_16 = (uint32_t) (off) >> 16;
}
*/
// 这里就是建立了各种各样的中断处理程序, 主要是改变 idt 的内容, 也就是中断向量表的内容, 这样就构造出来中断向量表
SETGATE(idt[T_DIVIDE], 0, GD_KT, &th_divide, 0);
SETGATE(idt[T_DEBUG], 0, GD_KT, &th_debug, 0);
SETGATE(idt[T_NMI], 0, GD_KT, &th_nmi, 0);
SETGATE(idt[T_BRKPT], 0, GD_KT, &th_brkpt, 0);
SETGATE(idt[T_OFLOW], 0, GD_KT, &th_oflow, 0);
SETGATE(idt[T_BOUND], 0, GD_KT, &th_bound, 0);
SETGATE(idt[T_ILLOP], 0, GD_KT, &th_illop, 0);
SETGATE(idt[T_DEVICE], 0, GD_KT, &th_device, 0);
SETGATE(idt[T_DBLFLT], 0, GD_KT, &th_dblflt, 0);
SETGATE(idt[T_TSS], 0, GD_KT, &th_tss, 0);
SETGATE(idt[T_SEGNP], 0, GD_KT, &th_segnp, 0);
SETGATE(idt[T_STACK], 0, GD_KT, &th_stack, 0);
SETGATE(idt[T_GPFLT], 0, GD_KT, &th_gpflt, 0);
SETGATE(idt[T_PGFLT], 0, GD_KT, &th_pgflt, 0);
SETGATE(idt[T_FPERR], 0, GD_KT, &th_fperr, 0);
SETGATE(idt[T_ALIGN], 0, GD_KT, &th_align, 0);
SETGATE(idt[T_MCHK], 0, GD_KT, &th_mchk, 0);
SETGATE(idt[T_SIMDERR], 0, GD_KT, &th_simderr, 0);
// Per-CPU setup
trap_init_percpu();
}
这里代码部分是在这里, 但是调用过程是在 trapentry.S 之前的, 最后是调用 trap() 的过程:
// Trapframe 在 Env 中的定义是保存当前环境, 这里传入的参数是中断处理程序的寄存器信息
// 表示开始处理中断或者异常
void trap(struct Trapframe *tf)
{
// The environment may have set DF and some versions
// of GCC rely on DF being clear
asm volatile("cld" ::: "cc");
// Check that interrupts are disabled. If this assertion
// fails, DO NOT be tempted to fix it by inserting a "cli" in
// the interrupt path., 进入内核之后要先关中断, 不允许其他中断
assert(!(read_eflags() & FL_IF));
// 输出了 trap 的信息,
cprintf("Incoming TRAP frame at %p
", tf);
if ((tf->tf_cs & 3) == 3) {
// Trapped from user mode.
assert(curenv);
// Copy trap frame (which is currently on the stack) into 'curenv->env_tf',
// so that running the environment will restart at the trap point.
curenv->env_tf = *tf;
// The trapframe on the stack should be ignored from here on.
tf = &curenv->env_tf;
}
// Record that tf is the last real trapframe so
// print_trapframe can print some additional information.
last_tf = tf;
// Dispatch based on what type of trap occurred, 为 tf 分配一个 handler,
// 并进行了 trap 处理
trap_dispatch(tf);
// 在 trap_dispatch 函数的末尾, 使用了 env_destroy(curenv);
// Return to the current environment, which should be running.
assert(curenv && curenv->env_status == ENV_RUNNING);
// 返回到用户进入内核之前执行的指令
env_run(curenv);
}
然后是两个问题:
- What is the purpose of having an individual handler function for each exception/interrupt? (i.e., if all exceptions/interrupts were delivered to the same handler, what feature that exists in the current implementation could not be provided?)
不同的函数对应的是不同的中断描述符, 也就是对应着不同的 trap SETGATE, 对应这不同的操作, 还有就是优先级问题,
Did you have to do anything to make the user/softint program behave correctly? The grade script expects it to produce a general protection fault (trap 13), but softint's code says int 14. Why should this produce interrupt vector 13? What happens if the kernel actually allows softint's int 14 instruction to invoke the kernel's page fault handler (which is interrupt vector 14)?
因为当前的系统正在运行在用户态下,特权级为3,而INT指令为系统指令,特权级为0。特权级为3的程序不能直接调用特权级为0的程序,会引发一个General Protection Exception,即trap 13。