一、概念:
1、粘包是发送端发送数据,接收端不知如何接受而造成的一种数据混乱的现象。
2、只存在于TCP中,而UDP中没有。
二、两种出现粘包的机制
1、合包机制:
当发送端的数据是多个数据包,并且数据之间的间隔很短时,多个数据包发送到缓冲区时就会进行合包(Nagle算法实现的).然后发送到
接收端的操作系统的缓冲区,然后再进行拆成原来的组合前的样子,接收端下达接收指令,根据接受的内容的大小进行接收。由于TCP是
面向字节流的,所以无法有明确的截取数据的大小,而是有可能全部都被接收,导致数据混乱,造成粘包现象。

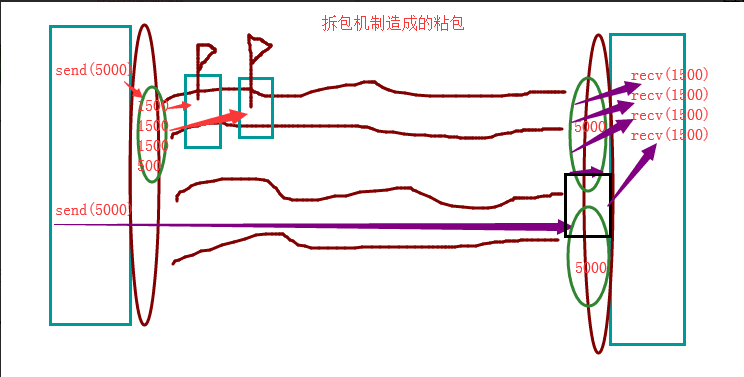
2、拆包机制
发送端的数据大于网卡MTU值(最大1500)时,以5000为例。就会拆包然后发送到缓冲区。再由缓冲区将所有的拆成小数据包的数据
一个一个的发送到接收端的缓冲区。被拆分的数据包到达缓冲区是没有顺序的,先到的会等待所有数据包都到达之后在进行组合,成为
原来5000大小的包。由于受网卡MTU值的限制,每次只能接受1472(1500 -20(ip报头)- 8(tcp报头))。这时又有一个5000的数据包过来的时候,上个一5000的数据包剩
下的500就会和下一个5000的包中的1000组成成为一个1500的包被接受,导致数据混乱,造成粘包现象。
三、如何解决粘包问题
使用 struct 模块
当我们发送数据的时候如果能够让接收端接收数据的时候先接受一个固定长度的数据,然后再把接到的这个数据的长度最为下一次接收的大小,这样就能避免数据包过大或者过小而导致粘包了。
# struct 的用法 import struct a = 1234 r = struct.pack('i', a) # struct.pack(数据类型,数据) 打包成一个定长为4个字节的bytes 类型 print(r) r_back = struct.unpack('i',r) # 解包成原来的数字 print(r_back) # 解包出来是一个元祖 (1234,)