1、生产者和消费者模型
作用:用于解耦。
原理:生产者将生产的数据放到缓存区,消费者从缓存区直接取。借助队列来实现该模型(队列就是缓存区)
队列是安全的,自带锁机制。
q = Queue(num) num 为队列的最大长度,可以自己设定。
q.put(): 向队列里放数据,如果数据满了就阻塞等待,如果还能放就直接放如。
q.get(): 阻塞等待获取数据,如果队列中有数据直接拿,没有就等待。
q.put_nowait(): 不阻塞,向队列里放数据,如果数据满了就直接报错。
q.get_nowait(): 不阻塞,直接从队列拿数据,如果没有数据就直接报错。
方法一:
用 Queue (队列)模块编写


from multiprocessing import Process, Queue def producer(q, production): for i in range(10): info = production + '打败了第%s只 小怪兽' % (i + 1) q.put(info) q.put(None) # 当生产者生产完之后,放一个None def consumer(q, name): while 1: info = q.get() if info: print('%s%s' % (name, info)) else: # 当info 中没有产品了,就会收到一个None,此时结束进程 break if __name__ == '__main__': q = Queue() p1 = Process(target=producer, args=(q, '奥德曼')) p2 = Process(target=consumer, args=(q, '迪迦')) p1.start() p2.start()
方法二:
用Queue(队列)模块编写
from multiprocessing import Process, Queue def producer(q, production): for i in range(10): info = production + '打败了第%s只 小怪兽' % (i + 1) q.put(info) def consumer(q, name, color): while 1: info = q.get() if info: print('%s%s%s�33[0m' % (color, name, info,)) else: break if __name__ == '__main__': q = Queue(5) p1 = Process(target=producer, args=(q, '奥特曼')) p2 = Process(target=producer, args=(q, '蝙蝠侠')) p3 = Process(target=producer, args=(q, '绿巨人')) p4 = Process(target=consumer, args=(q, '刘奶奶操纵', '�33[33m')) p5 = Process(target=consumer, args=(q, '李二毛骑着', '�33[36m')) p_lst = [p1, p2, p3, p4, p5] [i.start() for i in p_lst] p1.join() p2.join() p3.join() q.put(None) q.put(None)
当有多个生产者和消费者时,有几个消费者取,就放几个put(None)
方法三:
用 JionableQueue (可加入队列)编写
JionableQueue是继承Queue,同时多了两个方法
q.join(): 用于生产者。等待q.task_done的返回结果。生产者就能获得消费者当前消费了多少数据。
q.task_done(): 用于消费者,消费者每拿一个数据都会给jion返回一个标识,标记数据。
from multiprocessing import Process, JoinableQueue def consumer(j, name, color): while 1: info = j.get() print('%s%s拿走了%s�33[0m' % (color, name, info)) j.task_done() def producer(j, name): for i in range(20): info = '第%s个%s' % (i + 1, name) j.put(info) j.join() if __name__ == '__main__': j = JoinableQueue(10) p1 = Process(target=consumer, args=(j, '猥琐大叔', '�33[35m')) p2 = Process(target=producer, args=(j, '巴拉巴拉小魔仙',)) p1.daemon = True p1.start() p2.start() p2.join()
2、管道
分为: 单进程管道和多进程管道
但进程管道收发:
con1 发送,只能con2接收。
con2发送, 只能con1接收
多进程管道收发:
父进程con1发送, 子进程只能con2接收
父进程con2发送, 子进程只能con1接收
父进程con1接收, 子进程只能con2发送
父进程con2接收, 子进程只能con1发送
from multiprocessing import Pipe, Process def fn(*args): con1, con2 = args con1.close() while 1: try: b = con2.recv() print(b) except EOFError: con2.close() break if __name__ == '__main__': con1, con2 = Pipe() p = Process(target=fn, args=(con1, con2)) p.start() con2.close() for i in range(10): con1.send(i) con1.close()
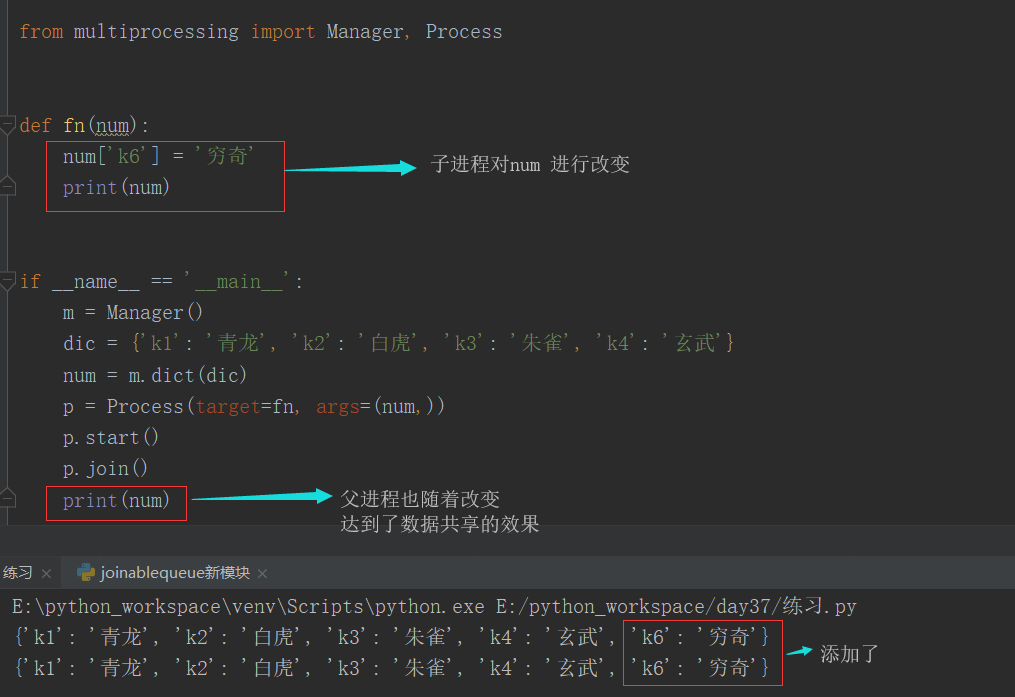
3、进程间的数据共享
Manager
from multiprocessing import Manager
4、进程池
1)定义:一个池子里(其实相当于一个存储场所)有一定数量的进程。这些进城一直处于待命状态,一旦有任务就去执行。
2)为什么要有进程池?在实际业务中,任务量有多有少,如果任务特别多,不可能有正好开启对应的任务。如果要开启那么多进程就会需要消耗大量的时间让操作系统为你管理。其次还需要消耗大量的时间让cpu调度。
因此,进程池就会帮程序员去管理池中的进程。
from multiprocessing import Pool
3)规则:进程池中所存放的进程数量最好是cpu核数 + 1
4)进程池中的三种方法:
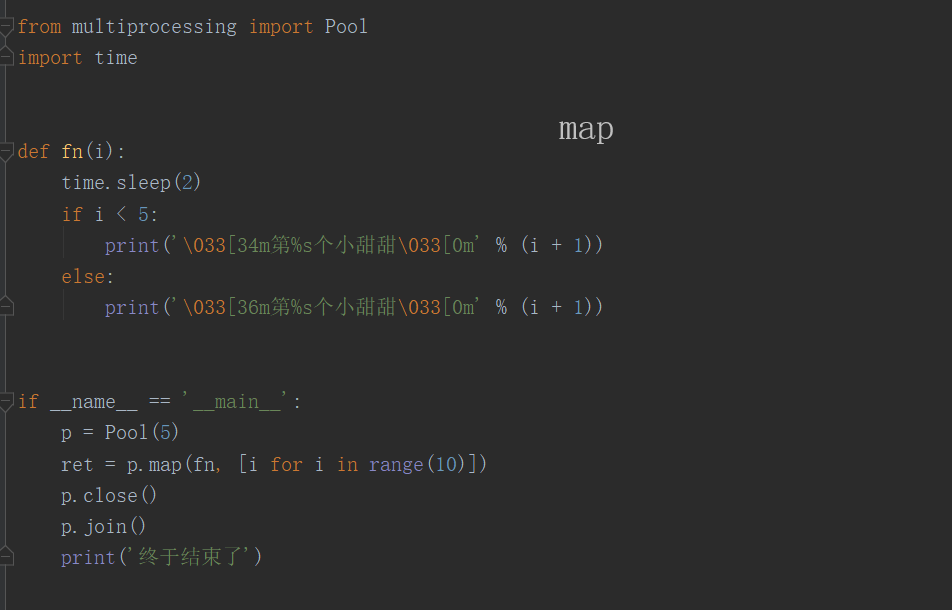
(1)map (func, iterable)
func:进程池中的进程执行的任务函数
iterable:可迭代对象,把可迭代对象中的每个元素依次传递给任务函数。
(2)apply(func,agrs=())
同步的效率。进程会一个一个的执行任务
func:进程池中的进程执行的任务函数
args:可迭代对象型的参数,是传给任务函数的参数
同步处理时,不需要close 和 join
同步处理时,进程池中的所有进程都是普通进程

(3)apply_async(func, args=()), cllback=None):
异步效率:进程池中的进程会同时去执行任务。
func: 进程池中的进程执行的函数
args:可迭代对象的参数,是传给任务函数的参数
callback: 回调函数,就是每当进程池中的进程处理任务完成后,会返回结果给回调函数,让回调函数进一步处理,回调函数只有异步才有,同步没有。
异步处理任务时:进程中的所有进程时守护进程。
异步处理任务是:必须加close 和 join

回调函数的使用:
进程的任务函数的返回值,被当成回调函数的形参被接收到,以此进行进一步操作处理
回调函数是由主进程调用的,而不是子进程,子进程只负责把结果返回给回调函数。
