一、星型模型:是一种费正规化的结构,多维数据集的每一个维度都直接与事实表相连接, 不存在渐变维度,所以数据有一定的冗余。
二、雪花模型
当有一个或者多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展,原有的各维度表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表。它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。
二者的区别:
星型模型因为数据的荣誉所以很多查询不需要做外部连接,因此一般情况下效率比雪花模型高,设计与实现比较简单。
雪花模型由于去除了冗余,有些统计就需要通过表的连接才能产生,所以效率不一定有星型模型高。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
三、使用选择
四个角度来进行讨论:
1、数据优化
雪花模型使用的是规范化数据,数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型中。
相比较而言,星型模型实用的是反规范化数据。在星型模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完成性来部署。
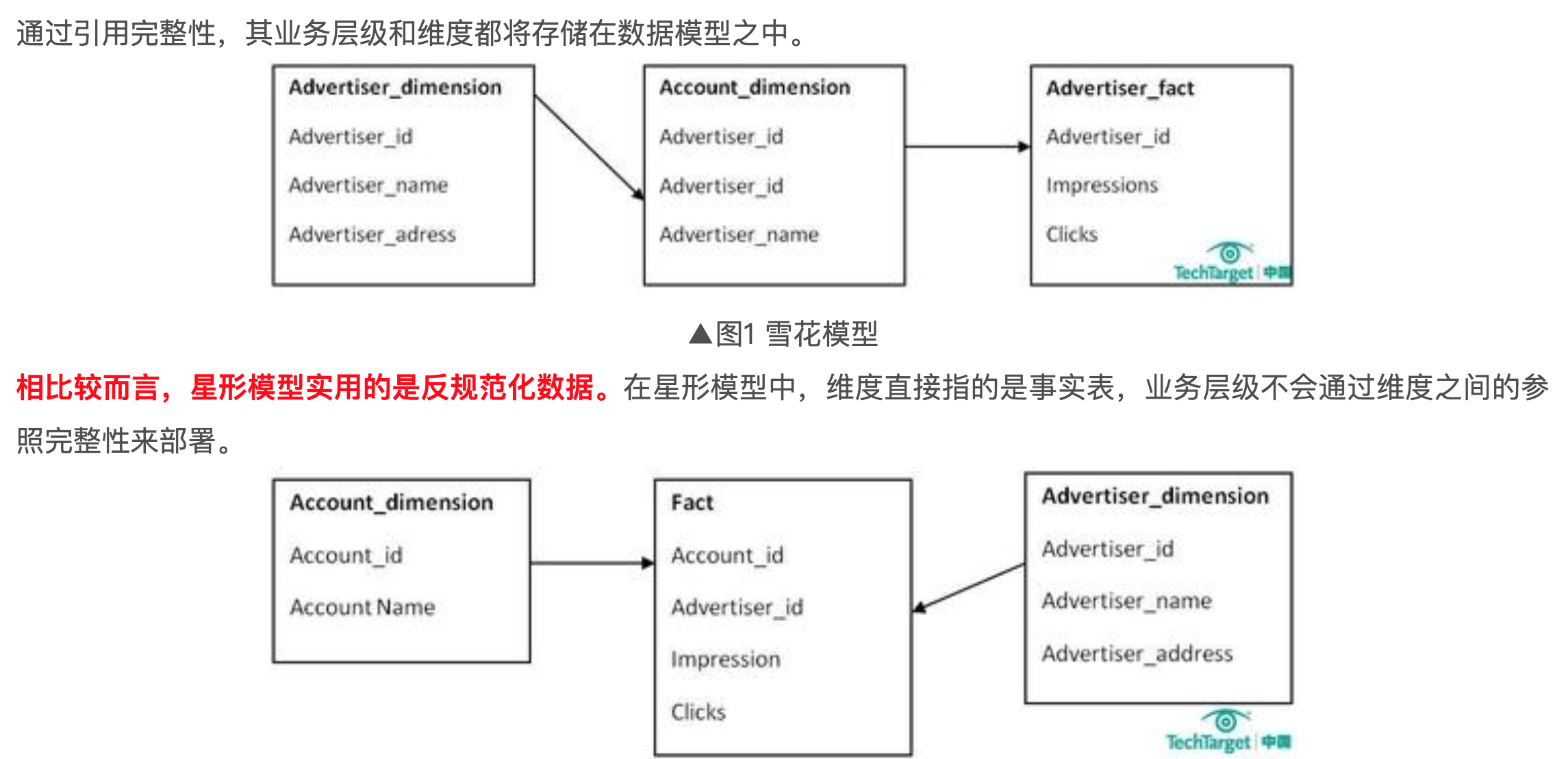
见上图
2、业务性能
在雪花模型中,数据模型的业务层级是有一个不同维度表主键-外键的关系来代表的;
在星型模型中,所有必要的维度表在事实表中都只拥有外键。
3、性能
雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。
4、ETL
雪花模型加载数据集市,因此ETL操作和设计上更加复杂,而且由于附属模型的限制,不能并行化。
星型模型加载维度表,不需要在维度表之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。
总结:
雪花模型使得维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司在线的?”
星型模型用来做指标分析更适合,比如“给定的一个客户他们的收入是多少?”