今天上传txt文件下载下来却乱码,搞了一下午,发现还挺复杂。记录一下。
1.首先服务器只接受utf-8格式的文件,所以首先想到的就是转码问题。
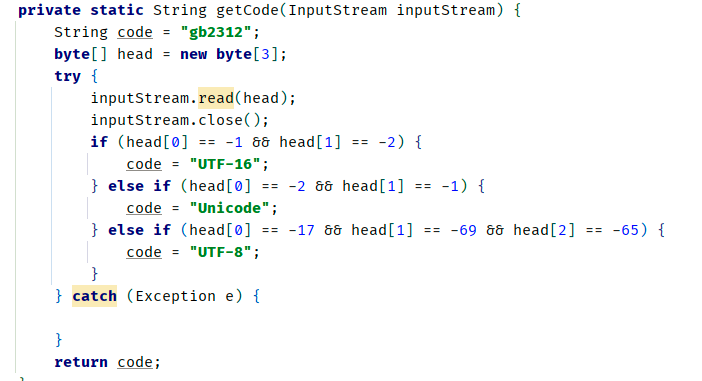
这是网上很容易就找到的判断文件编码的代码。判断出来之后如果是UTF8格式的文件就正常上传,如果不是就先转成UTF8格式再上传。
我以为问题解决了的时候,发现上传之后还是乱码。然后我就创建两个内容一样但是编码不一样的文件仔细比较,发现我转码之后的byte数组少了正常文件的utf8标识符。
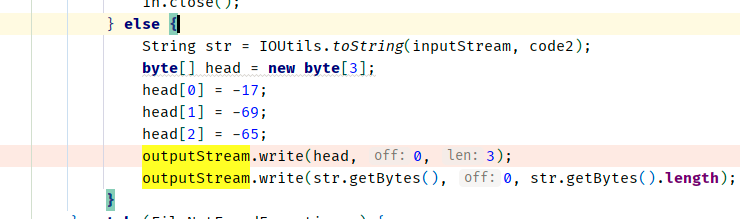
然后byte数组前面就要加上-17 -69 -65的标识符
代码如下
就我以为要万事大吉的时候,那边测试告诉我还不行。于是我把他的文件拿过来测试。
发现他的文件是UTF8格式,但是没有标识符!!我的getCode代码判断不出来他是UTF8 当成GBK处理了,自然还是乱码。
于是我百度一番,找到了一个jar包可以帮住我识别他是utf8文件,可是直接上传还不行,因为没有前缀 oss服务器那边也不认。
于是我就要用jar包的方式判断编码来转码,用前缀判断编码的方式来给byte数组增加前缀。
下面是完整的代码和关联的pom文件
<dependency>
<groupId>com.googlecode.juniversalchardet</groupId>
<artifactId>juniversalchardet</artifactId>
<version>1.0.3</version>
</dependency>
private static InputStream create(MultipartFile file) throws IOException { if (!file.getOriginalFilename().endsWith("txt")) { return file.getInputStream(); } OutputStream outputStream = new ByteArrayOutputStream(); String code = getCode(file.getInputStream()); String code2 = getCode2(file.getInputStream()); //getFilecharset(file.getInputStream()) if (code.equals("UTF-8")) { return file.getInputStream(); } else { String str = IOUtils.toString(file.getInputStream(), code2); byte[] head = new byte[3]; head[0] = -17; head[1] = -69; head[2] = -65; outputStream.write(head, 0, 3); outputStream.write(str.getBytes(), 0, str.getBytes().length); ByteArrayOutputStream baos = (ByteArrayOutputStream)outputStream; InputStream inputStream = new ByteArrayInputStream(baos.toByteArray()); return inputStream; } } private static String getCode2(InputStream inputStream) throws IOException { UniversalDetector detector = new UniversalDetector(null); byte[] buf = new byte[4096]; // (2) int nread; while ((nread = inputStream.read(buf)) > 0 && !detector.isDone()) { detector.handleData(buf, 0, nread); } // (3) detector.dataEnd(); // (4) String encoding = detector.getDetectedCharset(); return encoding; } private static String getCode(InputStream inputStream) { String charsetName = "gbk"; byte[] head = new byte[3]; try { inputStream.read(head); inputStream.close(); if (head[0] == -1 && head[1] == -2 ) //0xFFFE charsetName = "UTF-16"; else if (head[0] == -2 && head[1] == -1 ) //0xFEFF charsetName = "Unicode";//包含两种编码格式:UCS2-Big-Endian和UCS2-Little-Endian else if(head[0]==-27 && head[1]==-101 && head[2] ==-98) charsetName = "UTF-8"; //UTF-8(不含BOM) else if(head[0]==-17 && head[1]==-69 && head[2] ==-65) charsetName = "UTF-8"; //UTF-8-BOM } catch (Exception e) { } return charsetName; }