前几天写了几篇关于IO操作的博客,今天再记录一下NIO相关知识点。
| NIO和IO的区别 |
1. 什么是NIO?
NIO是java1.4版本引入的,可以替代标准的java IO API,它与原来的IO有同样的作用和目的,但是IO是面向流的(字节流、字符流之类),但是NIO是面向缓冲区的、非阻塞式IO。整个图看一下:
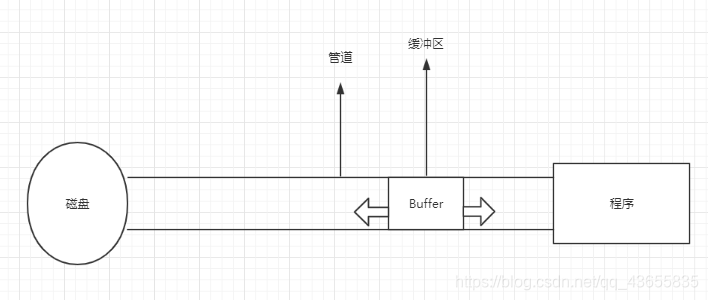
上图是NIO的传输方式,Channel就是我们的管道,如果你的程序和本地磁盘之间需要进行IO传输,通过使用NIO的方式,你可以从程序中将数据读到Buffer缓冲区中,然后Buffer再经过管道将数据写到本地磁盘。你也可以从本地磁盘中将数据读到Buffer缓冲区,然后缓冲区再通过Channel管道将数据写到程序中。它的传输与原来IO不同,它的双向的(以上工作流程可以想象成火车在两地之间来回运送旅客的情景)
2. NIO的核心
NIO的核心就是通道(Channel)和缓冲区(Buffer)。若要使用NIO系统,需要获取用户连接文件的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理.
3. IO和NIO的区别?
IO:
我们读文件需要创建一条输入流管道,写文件需要创建一条输出流管道,所以IO时单向传输。
IO的管道内是字节流,所以IO是面向流。
NIO:
读写文件都是在一个管道内,所以是双向传输。
NIO管道内是缓冲区,所以是NIO是面向缓冲区。
| Buffer缓冲区 |
Buffer缓冲区的作为NIO的核心之一,其主要的作用就是存储数据。缓冲区就是数组,用于存储不同数据类型的数据。
1.Buffer分类(根据数据类型)
1.ByteBuffer
2.CharBuffer
3.ShortBuffer
4.IntBuffer
5.LongBuffer
6.FolatBuffer
7.DoubleBuffer
以上除了boolean类型没有对应的Buffer外,其他的基本数据类型都有对应的Buffer缓冲区。都是通过allocate()方法来获取缓冲区。
CharBuffer allocate = CharBuffer.allocate(1024);
以上代码我们创建了一个指定大小为1024字节的缓冲区。
2.缓冲区存取数据的核心方法
1.get():将数据从缓冲区中取出来
2.put():将数据存到缓冲区
3.缓冲区核心属性
以上7种缓冲区都是继承了父类Buffer,在父类Buffer中可以看到缓冲区有3种属性,
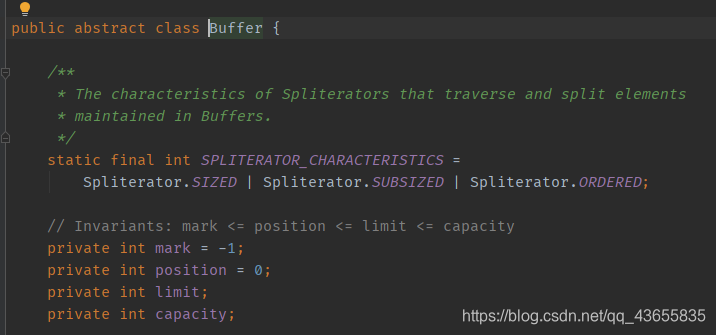
1.position:位置:☞缓冲区正在操作数据的位置
2.limit:界限:☞缓冲区可以操作数据的大小,limit之后的数据是不能修改的,一旦指定界限,无法更改
3.capacity:容量:☞缓冲区最大存储数据的容量,指定之后无法改变
mark:标记 ☞此属性没有特别的意义,mark就是用于在缓冲区的位置打个标记,一般配合reset(将此缓冲区的位置重置为之前mark标记的位置)来使用,注意:mark永远不会为负数,如果mark=-1,相当于丢弃mark。
下图可以很清楚的了解NIO的读写数据的过程:

4.NIO读写切换
使用NIO的话,就不得不提一下NIO的读写切换,也就是将Buffer缓冲区从读模式切换到写模式,我们一般使用缓冲区对象的flip()方法来进行读写模式的切换,来段伪代码:
@Test
void contextLoads() {
//创建指定大小为1024字节的缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
//将一段字符串放到缓冲区中
String str = "北京";
byteBuffer.put(str.getBytes());
//将缓冲区从写模式切换为读模式
byteBuffer.flip();
//将缓冲区中的数据写回来
byte[] bytes = new byte[byteBuffer.limit()];
byteBuffer.get(bytes);
System.out.println(new String(bytes, 0, bytes.length));
}
再来看看flip()方法的源码,调用flip()方法,缓冲区正在操作的数据位置将会赋值给limit界限,然后将正要操作的数据位置清0,
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
无论是使用哪种类型的缓冲区,在进行读写切换的时候,都需要调用缓冲区对象的flip()方法。
5.clear()方法和rewind()方法
Buffer对象中的clear()方法和rewind()方法相对于其他方法来说,既有相通的地方又有很明显的区别,总结一下两者的主要区别:
1.clear():
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
从clear()的源码中可以看出,调用此方法,缓冲区的位置被置为0,然后将缓冲区的容量赋值给了界限,mark标记也被遗弃,相当于将缓冲区清空,此时如果有未未处理的数据也不会再被处理。
2.rewind():
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
从rewind()的源码中可以看到,它与clear()最主要的区别就是rewind()只将位置置为0,并没有对界限limit进行调整赋值。所以调用rewind()方法,我们可以从头开始处理数据,limit界限不变。