加载购买商品表的数据
- 数据来源阿里天池:https://tianchi.aliyun.com/dataset/dataDetail?dataId=45
- 购买商品表字段信息:
- 用户ID 商品ID 商品二级分类 商品一级分类 商品属性 购买数量 购买日期
import pandas as pd import numpy as np import matplotlib.pyplot as plt from pandas import Series, DataFrame %matplotlib inline 魔法指令 # 导入数据 buy = pd.read_csv('./淘宝婴儿用品案例数据/(sample)sam_tianchi_mum_baby_trade_history.csv', engine='python')

考虑到属性字段,都是一些编号,没办法具体分析,因此去除该字段
buy.drop(labels='property', axis=1, inplace=True)

将day列的数据转换成时间序列
# 这里需要给时间指定格式 buy['day'] = pd.to_datetime(buy['day'], format='%Y%m%d')
查看数据的时间范围
- 显示出数据集的最早购买时间和最后购买时间
buy['day'].min(), buy['day'].max() (Timestamp('2012-07-02 00:00:00'), Timestamp('2015-02-05 00:00:00'))
查看buy_mount是否存有异常值
购买数量小于等于零为异常数据
# 通过条件查询购买数量小于等于0的数据,返回布尔值 # 如果小于等于就返回True为1,否则布尔值False为0,求和结果大于0说明有异常值 (buy['buy_mount'] <= 0).sum() 0
此时返回0,说明没有异常值
查看数据集用户购买商品的情况
- 需要获知,大部分用户是多次购买商品还是只是购买了一次商品
# nunique 可以返回去重后的个数,相当于unique加count # 这里通过这个操作得到总user_id数 buy['user_id'].nunique() 29944 # shape[0] 获取总体数据有多少行,得到总交易数 buy.shape[0] 29971
29971笔交易是29944个用户产生的,所以一次购买的多
加载婴儿表的数据
- 婴儿信息表字段信息:
- 用户ID 出生日期 性别
baby = pd.read_csv('./淘宝婴儿用品案例数据/(sample)sam_tianchi_mum_baby.csv', engine='python')
把birthday转换成时间序列
baby['birthday'] = pd.to_datetime(baby['birthday'], format='%Y%m%d')
查看gender列是否存在异常数据
# value_counts 可以统计一列的元素种类并记录 baby['gender'].value_counts() 0 489 1 438 2 26 Name: gender, dtype: int64
通过上述操作2为异常数据,并且有26个
清除gender列中的异常数据
# 通过条件筛选出gender中不是2的数据,重新给baby表赋值,清掉异常值 baby = baby.loc[~(baby['gender'] == 2)]
查看婴儿表中的男女比例
# value_counts 的到gender中的元素种类及个数 baby['gender'].value_counts() 0 489 1 438 Name: gender, dtype: int64 489/438 1.1164383561643836
男女比例近似1:1
汇总婴儿表和购买商品表的数据
df = pd.merge(buy, baby, on='user_id', how='outer')
查看新老用户的数量
# 对user_id分组求用户第一次购买时间和最后一次购买时间 user_df = df.groupby(by='user_id')['day'].agg(['min','max']) # 如果用户第一次购买时间和最后一次购买时间相等则是新用户,不等就是老用户 (user_df[min] == user_df[max]).value_counts() True 29920 False 24 dtype: int64
给数据添加新的一列为购买的月份
df['month'] = df['day'].astype('datetime64[M]')
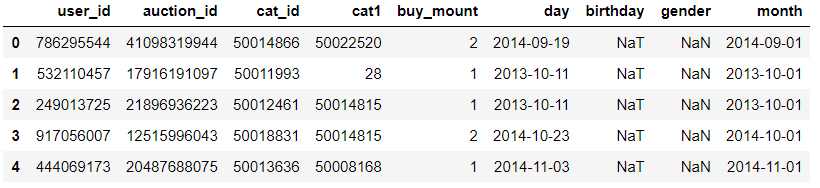
查看每个月商品的销量情况,绘制线形图进行展示
# 对月分组求每月的销量和 month_sales = df.groupby(by='month')['buy_mount'].sum()
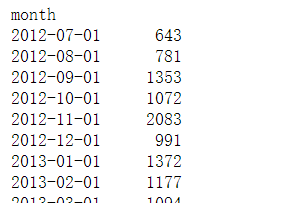
plt.plot(month_sales.index, month_sales.values) plt.xticks(rotation=30) # rotation=30 让它倾斜30度
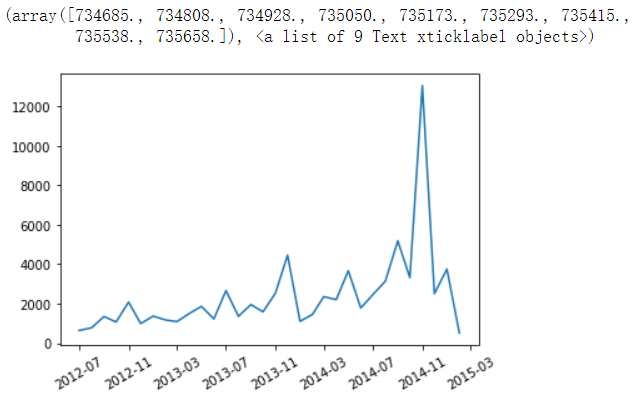
查看12,13,14年每个月的销量情况,绘制线性图进行展示
- 提示1:给源数据添加一列为购买的年份
- 提示2:给源数据添加一列为购买的年份的第几个月
- 比如购买时间为2010-10-12,该时间为该年的第10个月,添加数据为10
# 对原数据添加购买年份和购买年份的月份俩列 df['month_num'] = df['day'].dt.month df['year'] = df['day'].astype('datetime64[Y]')

# 对年和月分组求销量和 year_month_sales = df.groupby(by=['year', 'month_num'])['buy_mount'].sum()

# 将每年的数据单独取出 sale_2012 = year_month_sales['2012-01-01'] sale_2013 = year_month_sales['2013-01-01'] sale_2014 = year_month_sales['2014-01-01']

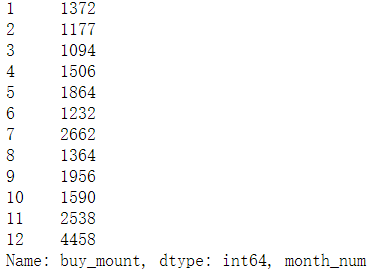
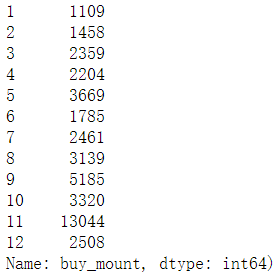
plt.plot(sale_2012.index, sale_2012.values, label='2012') plt.plot(sale_2013.index, sale_2013.values, label='2013') plt.plot(sale_2014, label='2014') plt.legend()
通过走势分析发现,在每年的5月,9月,11月都有不同程度的高峰凸起,整体呈现上涨趋势,接下来分析,为什么销量上涨?
查看每年的5,9,11这三个月每天的销量情况
- 查看12,13年11月份每天的销量情况,同理查看5,9月每天的销量情况
- 提示:给原始数据添加一列为销售时间的天数
11月
通过query对原始数据筛选
df['day_num'] = df['day'].dt.day

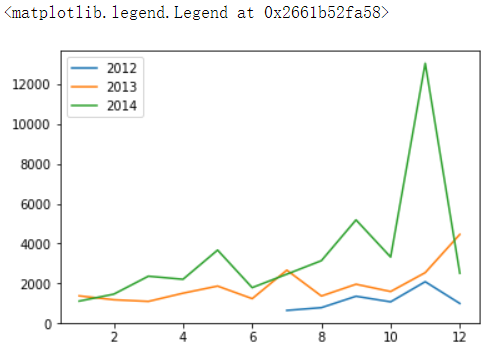
# 每年11销量 由于14年11月存在一笔很大的订单导致销量异常,现将其14年11排除 df_12_11 = df.query('year == "2012-01-01" & month_num == 11') df_13_11 = df.query('year == "2013-01-01" & month_num == 11') df_14_11 = df.query('year == "2014-01-01" & month_num == 11') df_12_11_sale = df_12_11.groupby('day_num')['buy_mount'].sum() df_13_11_sale = df_13_11.groupby('day_num')['buy_mount'].sum() # 由于14年11月存在一笔很大的订单导致销量异常,现将其14年11月排除 df_14_11_sale = df_14_11.groupby('day_num')['buy_mount'].sum() df_14_11_sale plt.plot(df_12_11_sale.index, df_12_11_sale.values, label='12-11') plt.plot(df_13_11_sale, label='13-11') plt.legend()
结论:2012年在11月10日和11月19日出现高峰,2013年在11月11日和11月29日出现高峰很明显是双十一促销带来的影响。
5月
# 没有12年5月的数据 df_13_5 = df.query('year == "2013-01-01" & month_num == 5') df_14_5 = df.query('year == "2014-01-01" & month_num == 5') df_13_5_sale = df_13_5.groupby(by='day_num')['buy_mount'].sum() df_14_5_sale = df_14_5.groupby('day_num')['buy_mount'].sum() plt.plot(df_13_5_sale,label='13-5') plt.plot(df_14_5_sale, label='14-5') plt.legend()

结论:13年和14年5月与出现了不同的峰值,很可能是因为节日导致销量的上升,因为5月有劳动节,母亲节还有520,521
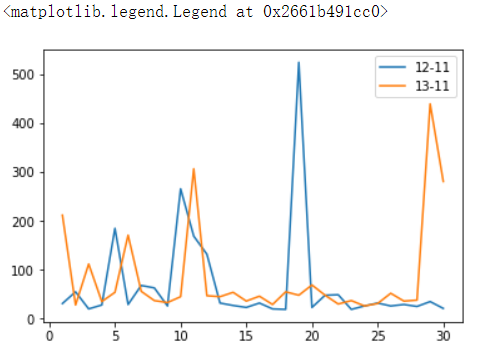
# 每年9月的销量 df_12_9_sale = df.query('year == "2012-01-01" & month_num == 9').groupby('day_num')['buy_mount'].sum() df_13_9_sale = df.query('year == "2013-01-01" & month_num == 9').groupby('day_num')['buy_mount'].sum() # 14年9月存在异常大单 df_14_9_sale = df.query('year == "2014-01-01" & month_num == 9').groupby('day_num')['buy_mount'].sum() plt.plot(df_12_9_sale, label='12-9') plt.plot(df_13_9_sale, label='13-9') #plt.plot(df_14_9_sale, label='14-9') plt.legend()
结论:9月有中秋节,9月的峰值很可能是中秋节销量上涨
分析一级分类商品的销量情况,使用柱状图显示
cat1_sales = df.groupby('cat1')['buy_mount'].sum() # 要将index转成str plt.bar(cat1_sales.index.astype('str'), cat1_sales.values) plt.xticks(rotation=30)
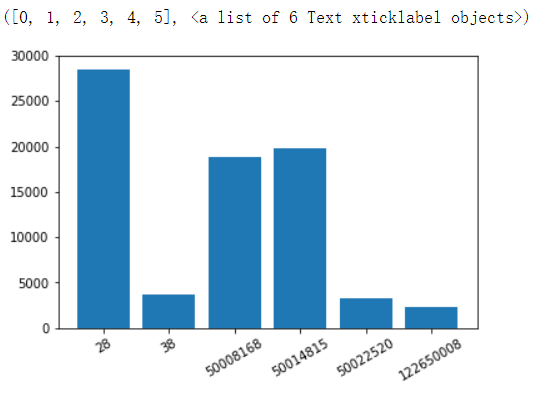
28商品的销量最高,这里要注意销量高并不是热销产品
分析一级分类商品的购买用户人数,使用柱状图显示
买的人多的产品,才是热销产品
# 这里要使用nunique去重计数,count会将重复值计算到其中 cat1_user_count = df.groupby('cat1')['user_id'].nunique() plt.bar(cat1_user_count.index.astype('str'), cat1_user_count.values)

结论:从图中可以看出 68结尾的商品,购买用户人数是最大的,但是总销量低于28产品,按照我们对于热销产品的定义,50008168为热销产品。
- 热销产品为购买人数最多的产品而不是销量最高的产品,因为可能会有少量用户一次性购买大量的某种商品